What are AI evals? The work that decides whether a model ships
Evals are how labs decide a model is ready to ship — and how buyers decide which model to buy. A plain-English guide to capability, safety, and production evals, the LLM-as-a-judge pattern, and what changed in 2026.
By Priya Patel, Insightful AI Desk
If you spend any time around the people who actually ship AI models, you notice a strange thing about how they talk. They almost never describe a model as smart or good. They describe it as passing something. A capability eval. A safety eval. An internal regression. A red-team set. A specific customer's eval. The verb is consistent across labs: a model does not graduate, it passes evals.
Evals are short for evaluations, and the abbreviation has done a lot of work in the last two years. It has absorbed everything from academic benchmarks, to internal quality dashboards, to the tests a regulator runs before a frontier model is allowed near a state customer. The word now sits in board decks, procurement RFPs, model cards, and policy submissions. It is also frequently used badly — as a synonym for "we ran a test" — by companies that have not really thought about what their test measures.
This piece is the plain-English version. What an eval actually is, what it is for, why benchmark scores stopped meaning what they used to mean, how labs now decide a model is ready to ship, and what a buyer of AI should ask before treating any vendor's numbers as evidence of anything.
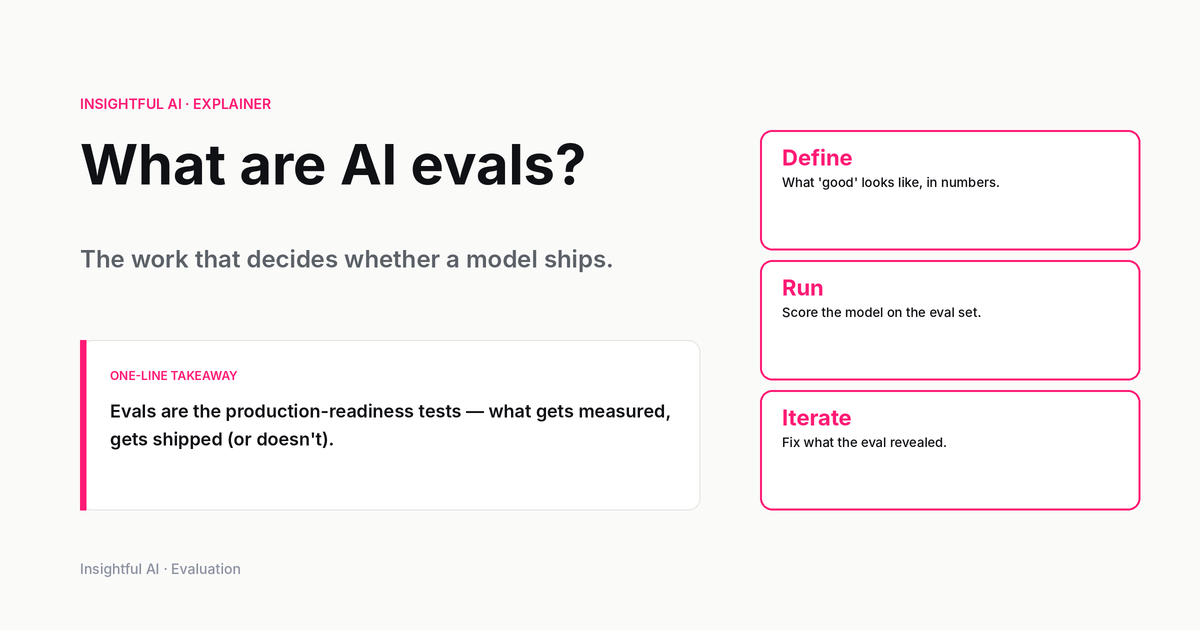
What an eval actually is
An eval is a measurement of model behaviour against a defined expectation. That sentence sounds bureaucratic, but every word does work.
Measurement means a number, or at least something countable. A vibe-check is not an eval. A screenshot of one good answer is not an eval. An eval has a sample of inputs, a scoring procedure, and a result that you can compare across runs.
Model behaviour means what the model does, not what it is. You can measure parameter counts and training compute, but those are properties of the artefact. An eval is about output: did the model answer the question, refuse the request, call the right tool, generate harmful content, follow the system prompt, stay grounded in the document.
A defined expectation is the part that separates a good eval from a vague one. The expectation can be a reference answer, a rubric, a list of disallowed behaviours, or a target score on some external metric. Without it, you are not evaluating, you are just sampling.
Note what is missing from this definition: any claim about intelligence. Evals do not measure how smart a model is. They measure whether it does specific things, on specific inputs, the way you wanted it to. A model can pass every eval you can think of and still be unsuitable for your use case, because your use case was not in the eval set. This is the central, slightly humbling fact of the field. Evals are necessary, narrow, and easy to overinterpret.
Eval versus benchmark
The two words get used interchangeably, but inside labs there is a working distinction.
A benchmark is a public, shared eval. MMLU, GSM8K, HumanEval, GPQA, SWE-bench, AIME, the various long-context tests, the various agent leaderboards — those are benchmarks. They are useful because everyone runs them the same way and the scores are comparable. They are also gameable, because everyone knows they exist, the data is often discoverable on the web, and there is competitive pressure to optimise for them.
An eval in the broader sense includes the benchmarks, plus everything labs build internally: held-out test sets that have never been published, customer-specific evals that mirror real production traffic, safety probes that the lab does not want adversaries to study, capability-elicitation tests that try to find the dangerous edge of what a model can do under prompting, and regression suites that catch when a routine fine-tune accidentally breaks something that used to work.
When a lab says a model is ready to ship, they almost never mean it on the strength of public benchmarks alone. Public benchmarks tell you the model is in the right neighbourhood. The internal evals tell you whether it is the right model.
Why this matters now
Three things changed at once in the last eighteen months, and together they made evals load-bearing.
First, deployments got more autonomous. Earlier chat models were used by a human who could correct them in the next turn. Modern systems are agents. They take steps, call tools, write files, send emails, hit APIs. A bad output is no longer a wrong sentence; it can be a wrong action. The cost of a low-quality answer used to be embarrassment; now it can be a deleted database or a leaked document. Evals are how you find out, before deployment, where the model fails in ways that turn into actions.
Second, regulators showed up. The EU AI Act treats certain frontier models as systemic risk. The US Center for AI Standards and Innovation (CAISI) runs pre-deployment evaluations of leading models on a voluntary basis. State attorneys-general have started asking for documented testing on consumer-facing systems. None of those regimes is satisfied by a screenshot of a chatbot doing well on a math problem. They want a measurement methodology, a result, and a record.
Third, the model menu exploded. Two years ago an enterprise might have chosen between three or four frontier models. Today the same buyer is choosing among dozens — proprietary frontier, smaller frontier, open-weights large, open-weights small, fine-tuned variants, distilled variants, vendor-specific routes that switch between several of those under the hood. The only sane way to pick is to have an eval set that reflects your actual workload. The phrase that quietly replaced "we use GPT" in many enterprises is "we evaluate models on our own evals."
The eval funnel
Inside a frontier lab, a model on the path to release passes through several distinct stages of evaluation. The labs use different names but the order is broadly the same.
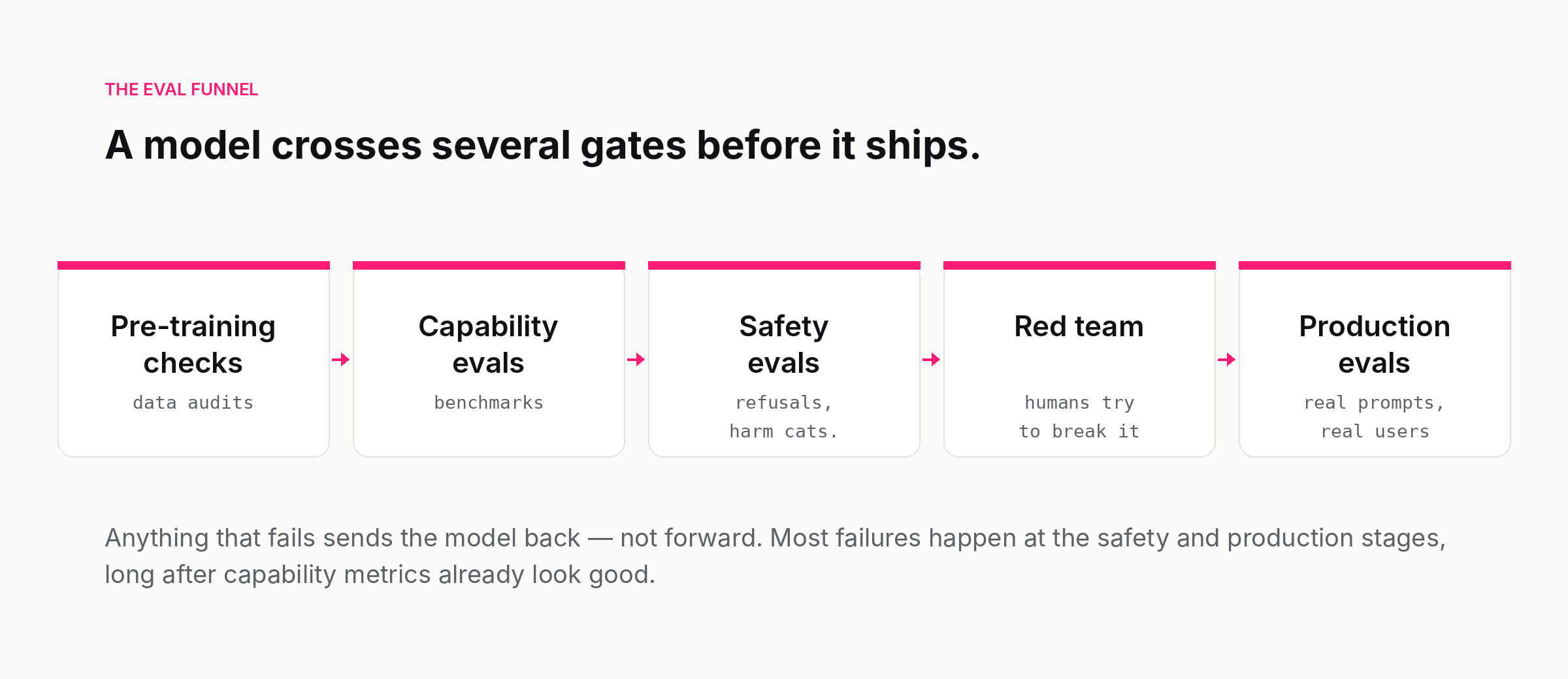
Pre-training checks. Before the model is anything you would call a model, the training run itself is monitored. Loss curves, gradient norms, data audits for contamination and licensing problems, sanity checks on early intermediate checkpoints. This stage catches catastrophic failures — a model that is not learning, a dataset that is broken — long before anyone tries to evaluate behaviour.
Capability evals. Once a base model exists, it is run against the public benchmarks and against internal capability sets. This is the stage that produces the numbers in launch posts: math, code, reasoning, factuality, multilingual performance, long context. It tells the team whether the new model is at, above, or below the previous one, and whether the training recipe worked.
Safety evals. A separate axis. Capability says the model can. Safety asks whether it will, when it should not. The categories are well-established at this point: biosecurity uplift, cyber uplift, child safety, self-harm, weapons, fraud, copyright, privacy, persuasion, jailbreak resistance. Each one has a set of prompts and a scoring procedure. A model that aces capability and fails safety is not a model that ships; it is a model that goes back to the alignment team.
Red team. Humans, often external, try to break the model on purpose. Red teams are a complement to automated evals, not a substitute. The most interesting failures are usually the ones an automated test could never have written, because the attacker had to think like a human adversary.
Production evals. Once the model is deployed, evaluation does not stop. Production evals run on real prompts, real traffic, real users. They are how the lab catches regressions, monitors drift, and detects when a deployment-time change — a system prompt update, a tool added to the harness, a routing change — accidentally broke something.
The funnel is one-directional in theory. In practice, signals from production routinely send a new model back to the safety team, and signals from red teams routinely add cases to the capability eval set. The release process is less of an assembly line and more of a feedback loop with a release gate at the end.
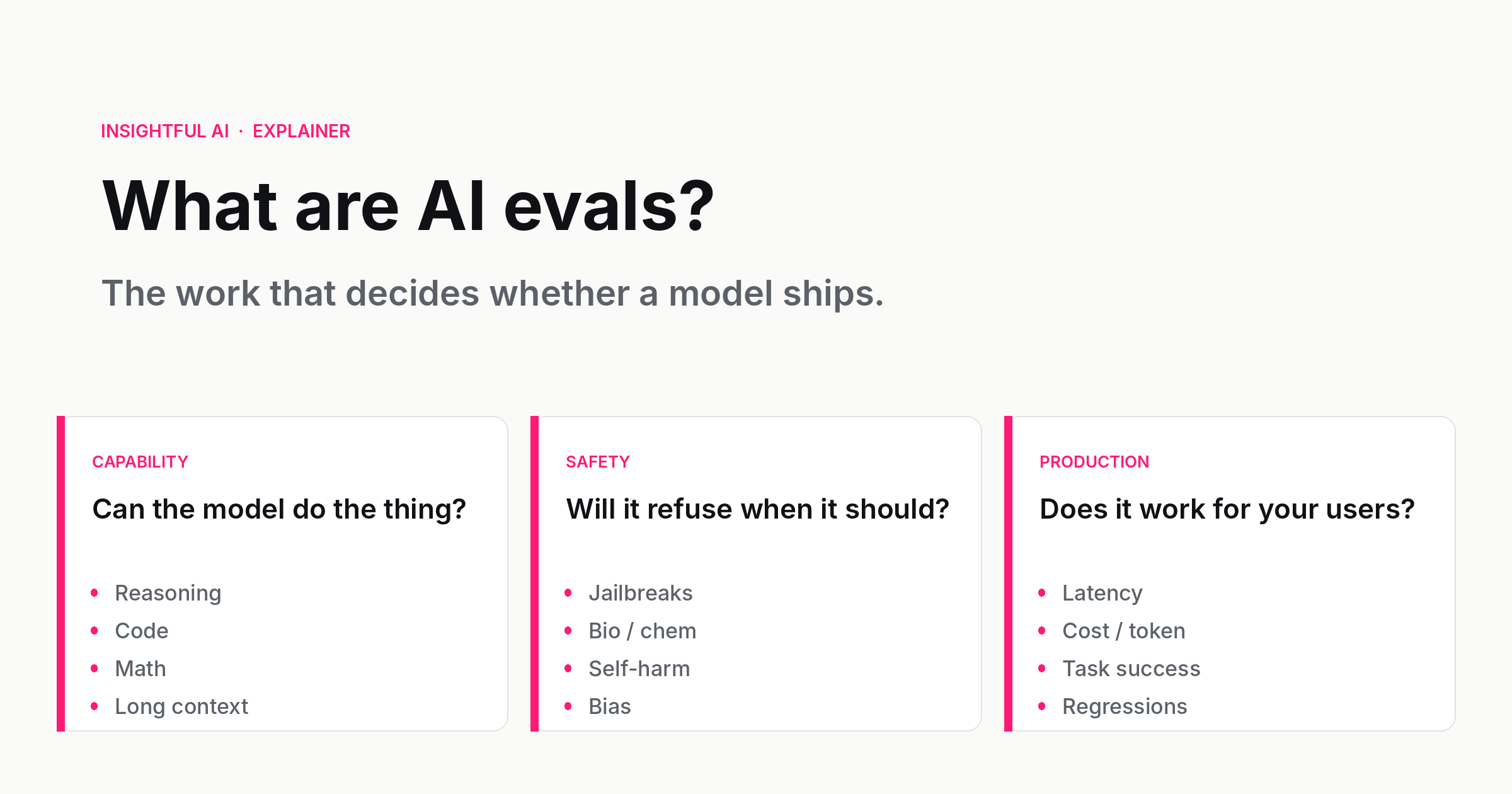
Three families of evals
Most evals you will encounter as a buyer, builder, or user fit into one of three families. Knowing which family you are looking at is the single most useful filter when someone tells you a number.
Capability evals ask: can the model do the thing? They have a right answer, or at least a reference answer, and the score reflects how close the model came to it. Math problems with verifiable answers. Coding tasks that pass or fail unit tests. Translation pairs scored against a reference. Multi-step reasoning problems with a defined solution. Long-context tasks where the answer is somewhere in the input. Capability evals are the most legible to outsiders because they look like school tests. They are also the most gameable, for exactly the same reason — schools have been teaching to the test for a long time, and so have AI labs.
Safety evals ask: will the model do the thing it should not? They are mostly about refusal, harm categories, and bias. Will the model help with weapons design when asked nicely? Will it produce convincing self-harm content when prompted with a fictional framing? Will it generate code that exfiltrates a database? Will it stereotype a protected group when asked to imagine one? The scoring is harder because there is no single right answer; instead there is a rubric for what an acceptable response looks like (refuse, redirect, partial, comply) and a judge that classifies each output.
Production evals ask: does the model work on what your users are actually doing? This is the family that matters to anyone shipping AI for real, and it is the family that public benchmarks tell you almost nothing about. The inputs are sampled from real production traffic, optionally with PII scrubbed. The scoring is workload-specific: did the support-bot follow policy, did the legal summariser quote the contract correctly, did the agent finish the task without hallucinating a tool. Production evals are the only ones that catch what your particular deployment, in your particular industry, with your particular users, is going to break.
How evals are actually scored
For some evals, scoring is trivial. Math problems have a single number; you check whether the model produced it. Code tasks have unit tests; you run them. Multiple-choice questions have a key.
For most interesting evals, scoring is not trivial, because the right answer is "a sentence that contains the following ideas and does not assert any of the following falsehoods," not "42." Three methods have emerged, and almost every modern eval pipeline mixes them.
Programmatic checks. Where they exist, they are the gold standard. A math answer either matches or does not. A regex either fires or does not. A function either returns the expected value or does not. The downside is that programmatic checks only cover the slim subset of tasks where the right answer can be exactly specified.
Human raters. Trained people grade the outputs against a rubric. This is the most reliable method for nuanced tasks and the most expensive. Human evaluation is where every modern lab eventually goes to settle a disputed score — when one automated method says model A is better and another says model B, a careful human study is the tiebreaker.
LLM as a judge. A language model grades the outputs against a rubric, often with the option to cite its reasoning. This is now the dominant method for medium-volume evaluation, because it is cheap and surprisingly aligned with human ratings on many tasks. It is also flawed, in interesting ways, which the field has had to confront over the last year.
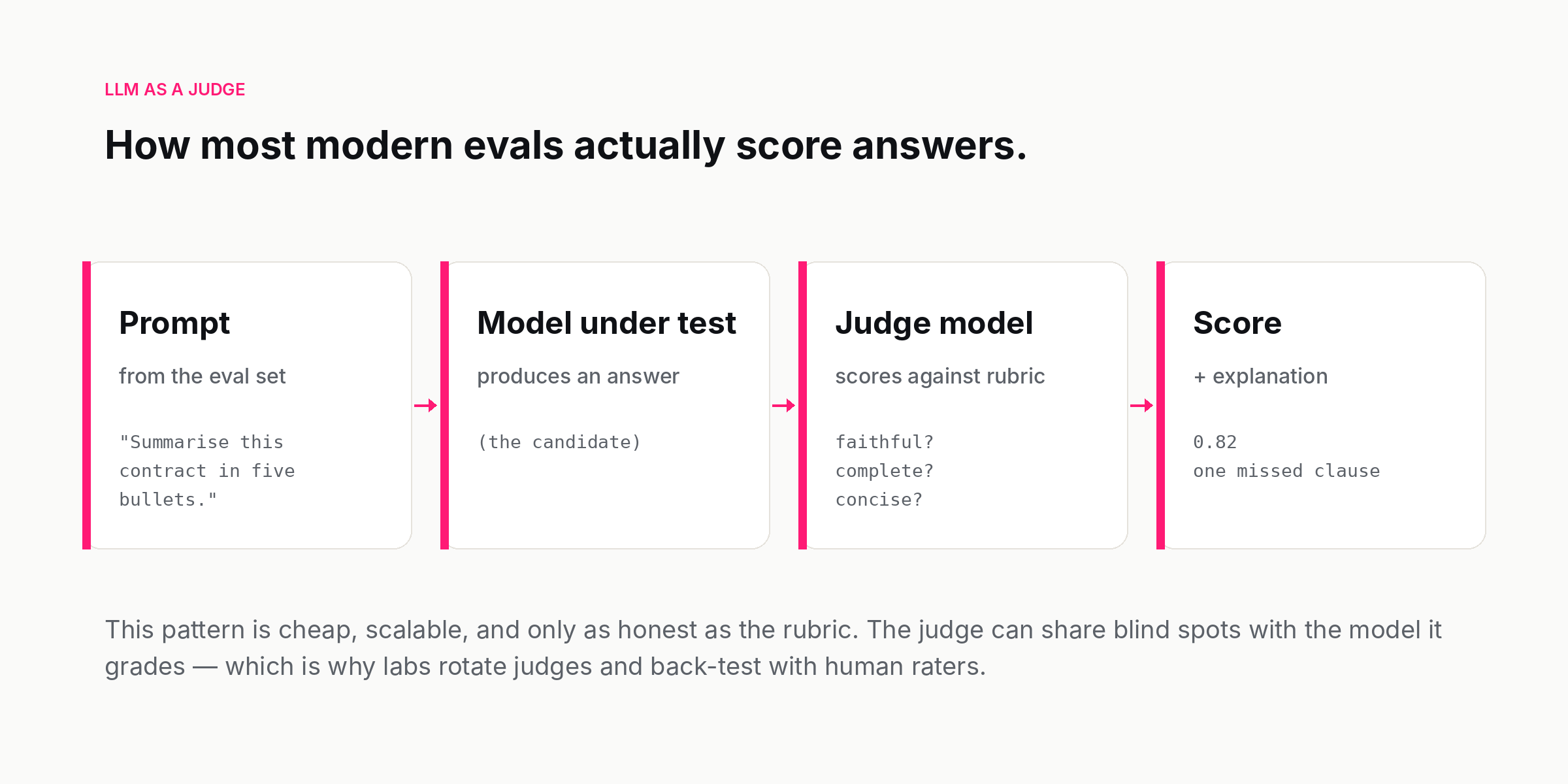
The judge pattern has known failure modes. Judges can share blind spots with the model they grade, which makes the scoring artificially generous. Judges can be sensitive to surface features — answer length, formatting, confidence — in ways that do not reflect quality. Judges can be biased toward the family of model they came from, which is why no serious lab uses the same model as both candidate and judge. The standard mitigations are rotating the judge, anchoring with human-rated subsets, and using multiple judges for hard cases. None of those is free, but they are cheaper than scaling human evaluation to the volume modern training runs require.
The eval crisis nobody quite calls a crisis
Around the middle of 2025, a quiet realisation hardened across the field: the public benchmarks had stopped being useful as a comparison between frontier models.
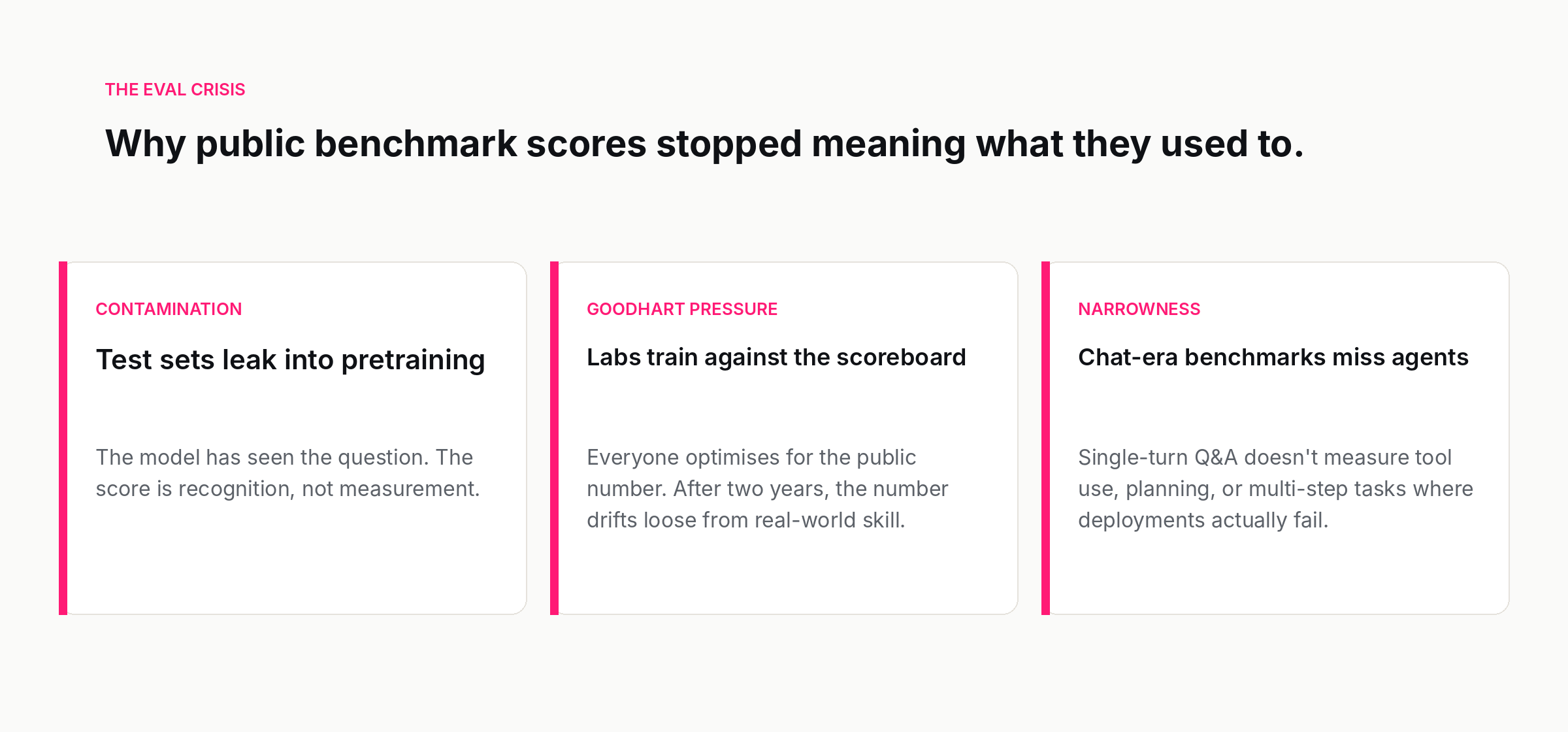
The reasons were familiar but their accumulation was not. Public benchmarks live on the open web. Foundation models are trained on the open web. Even with deduplication and contamination filters, it is hard to be sure that a benchmark's test set has not leaked, in some form, into pre-training. A model that has seen the test is not being measured; it is being recognised.
There was also Goodhart's pressure. When the same scoreboards are publicly tracked, every lab has an incentive to optimise for them, including with synthetic training data designed to look like the benchmark. By the time a benchmark has been the headline number for two years, scores on it have become almost meaningless as a comparison, because every lab has trained against it in some way. The numbers go up. Real-world performance does not move in parallel.
A third pressure was narrowness. The dominant benchmarks were designed for the chat era. They reward short, single-turn answers. They do not measure tool use, multi-step planning, long-horizon agentic tasks, or the kind of careful instruction-following that production deployment actually requires. A model can score the best in the world on the famous benchmarks and still be a poor agent.
The response, across labs, has been a quiet pivot. Public benchmarks are still reported, because the audience expects them, but the internal decisions are made on private eval sets that the lab can guarantee were not seen during training, and on agentic harnesses that measure performance on multi-step tasks. The numbers in launch posts and the numbers used to actually choose the next training direction are not the same numbers.
What changed in 2026
This year three trends have made evals look noticeably different from what they were a year ago.

Agentic evals took over. The interesting frontier is no longer the single-turn benchmark; it is the multi-step task. A model is asked to triage a bug, browse a documentation site, run a test, fix the code, and submit a patch — or a model is asked to plan a trip across three booking sites — and the score is whether the task was completed and at what cost. SWE-bench Verified, the various web-agent harnesses, and the long-running task suites have become the conversation. They are harder to game because they are harder to memorise; the work is the trajectory, not the answer.
Capability elicitation became formal. The labs no longer trust a model's default behaviour as evidence of what it can do. The frontier safety teams now run dedicated "elicitation" runs that aggressively prompt, fine-tune, and scaffold a model to find the upper bound of what it could do if a motivated user tried. The eval result that matters is what the model is capable of under pressure, not what it does on a benign prompt. This is how labs reason about the bio and cyber categories in their frontier safety frameworks.
Third-party evaluation arrived. CAISI in the United States, the UK's AI Security Institute, and equivalent bodies in several other countries now run their own pre-release evaluations on frontier models, on a voluntary but increasingly expected basis. The labs share weights and harness access under NDA; the institutes run their own probes and publish summaries. This is the first time independent evaluation has been part of a frontier release cycle. It is small, slow, and constrained — but it exists, and a year ago it did not.
What this means if you are buying or building
If you are choosing between AI vendors, or building on top of a model, the practical implications are short.
Treat vendor benchmark scores as evidence that the model is roughly competent, not as evidence that it is the right model for you. Public numbers narrow the shortlist; they do not pick the winner.
Build a small eval set of your own — fifty to two hundred examples drawn from real or realistic workload — before you pick a vendor. The act of writing the eval forces you to specify what you actually want the model to do, which is the single most valuable artefact a procurement process produces. It is also the only honest way to compare two models on your problem.
When a vendor cannot tell you how their model performs on your eval, that is the answer. When they can run it and the numbers are middling, you have learned something specific. When they tell you their proprietary benchmark shows them on top, ask which family of eval it is, what the rubric looks like, and whether the test set is public. The answers are usually informative regardless of what they reveal.
And do not stop evaluating after deployment. Production evals are the ones that catch what a vendor's release notes will not mention: the silent regression, the new refusal pattern, the changed cost profile, the subtle drift after a routing change. The model you bought last quarter is not the model you are running this quarter, even if the name on the API key is the same. The only way to know is to keep measuring.
Evals are the unglamorous part of AI. They do not produce demo videos. They produce graphs and CSVs and meeting agendas. They are also, increasingly, the part of the field where the real decisions get made — about which models ship, which capabilities are safe to release, which vendors win procurement, and which deployments quietly get rolled back. Anyone serious about AI now spends more time reading evals than reading model cards. It is worth knowing what you are reading.
Further reading: EU AI Act overview (European Commission), Center for AI Standards and Innovation (NIST), Zheng et al., Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena (2023), Jimenez et al., SWE-bench: Can Language Models Resolve Real-World GitHub Issues? (2023).
How we use AI and review our work: About Insightful AI Desk.


