RAG vs fine-tuning vs prompting: which do you actually need?
Three techniques get pitched as competitors. They aren't. They solve different problems. Here's the decision frame for choosing one or combining all three.

By Kenji Tanaka, Insightful AI Desk
Level: beginner to intermediate. If you have read the RAG explainer, you can skim the first section.
Once you have used AI products for a few months, you start hearing the same three words come up whenever anyone discusses making a model do something specific. RAG. Fine-tuning. Prompting. Each is presented in vendor pitches as either the obvious answer or a competitor to the others, and the difference between the three is often left to figure out from context.
They are not competitors. They solve different problems. The most expensive mistake in this space — for both buyers evaluating products and engineers building them — is choosing the wrong one for the job, and the second most expensive mistake is forcing one technique to do work the others would do better.
This piece is the decision frame I wish I had been given the first time I sat in a meeting about “making the model better at our use case.”
The three techniques in one sentence each
Prompting is shaping what the model does by what you write in the prompt. You change nothing about the model itself; the model stays exactly as the provider trained it. You are using a fixed instrument; the choice is what to play.
Retrieval-augmented generation (RAG) is letting the model look something up before answering. Documents you control sit in a search system; relevant passages get pulled into the prompt at query time; the model answers based on what was retrieved. The model is unchanged; the context it sees is different for every request. (For a longer treatment, see the earlier piece on what RAG is.)
Fine-tuning is updating the model’s weights on additional training data. The standard definition: “the process of adapting a model trained for one task (the upstream task) to perform a different, usually more specific, task (the downstream task).” After fine-tuning you have a different model. Its responses to the same prompt will be different from the original’s.
These three operate at different layers of the system. Prompting changes the input. RAG changes the input and adds retrieved context. Fine-tuning changes the model. That layering is the entire decision frame.
What each technique actually changes
An analogy helps if you do not already have intuition for what these techniques do to a model.
Imagine a new colleague you have just hired. They are competent, well-read, and able to do many things. Three different ways of getting them to do useful work for your team:
- You can write them a clear briefing for each task. That is prompting. They are unchanged; you are just communicating better.
- You can hand them your team’s internal documents at the moment they need them. That is RAG. They are unchanged; the information available to them when answering a specific question is now your team’s, not just their general knowledge.
- You can send them on a training course about your team’s topic area. That is fine-tuning. They have come back changed; they think and respond differently than they did before, in ways that persist across all future tasks.
You can do any of these. You can do all three. Each addresses a different gap.
When prompting is the right answer
If the model already knows what you need it to know, and the only question is how to communicate the task clearly, prompting is enough. This is more often the case than people assume.
You probably need only prompting when:
- The task is something a general-purpose model can do well out of the box.
- You need different behaviour in different situations and a single prompt template covers the cases.
- You can express the format and style of the answer you want by example.
- The information needed is small enough to fit comfortably in the prompt itself.
The cost of prompting is the lowest of the three: zero training time, zero infrastructure beyond the API call, immediate iteration. The trap is that prompting alone can plateau on hard tasks; if you find yourself writing prompts that are thousands of tokens long with many edge-case carve-outs, something else is probably the right tool.
When RAG is the right answer
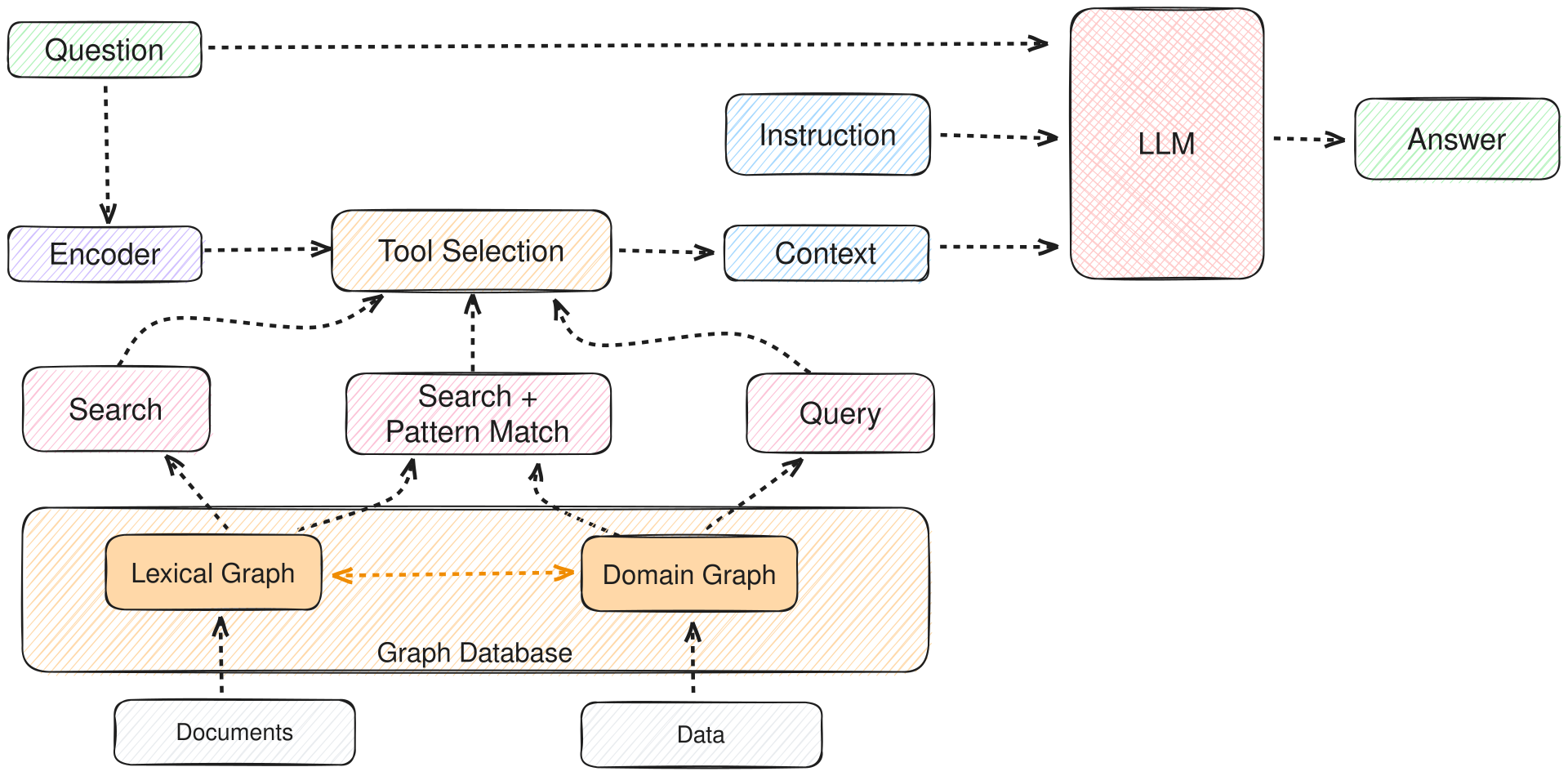
If the model does not know what you need it to know — because the answer lives in documents the model was never trained on — RAG is usually the right tool.
You probably need RAG when:
- The answers live in a body of documents you control (a knowledge base, internal wiki, product manual, regulatory text).
- Those documents change often enough that retraining a model is impractical.
- Citation matters — you want the user to be able to verify where an answer came from.
- The body of documents is too large to fit in a single prompt, even with a long context window.
The cost of RAG is higher than prompting: you have to build and maintain a retrieval system, chunk documents thoughtfully, choose an embedding model, and evaluate whether the retriever is finding the right passages. The trap is assuming RAG will fix what is actually a skill or behaviour problem — if the model is bad at writing in your company’s tone, adding a tone guide to its retrieval corpus will not reliably fix that. RAG is for fact recall, not style transfer.
When fine-tuning is the right answer
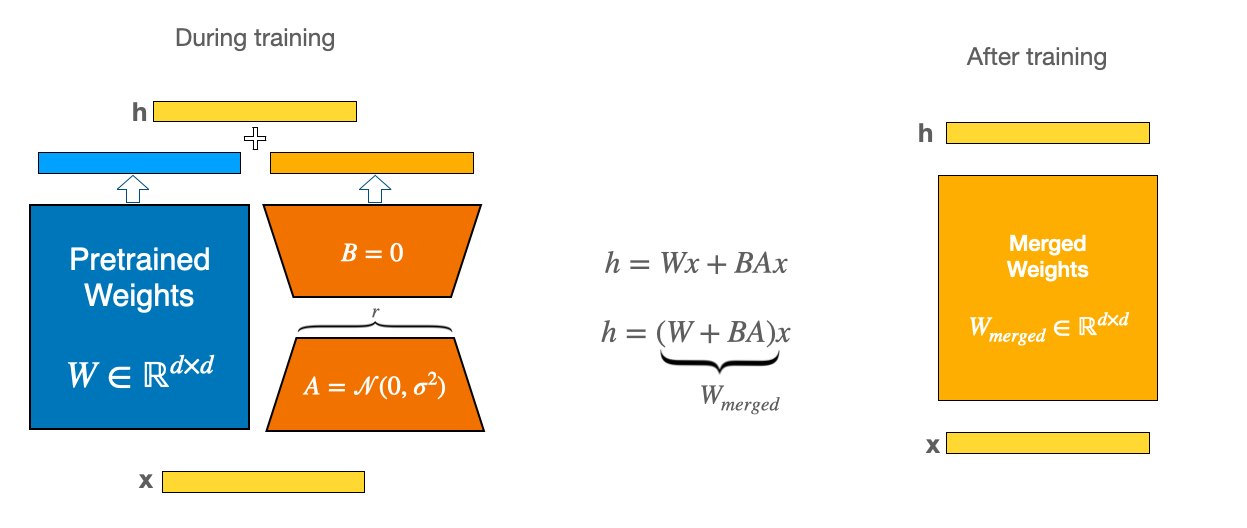
If the model needs to behave differently — in tone, format, decision-making style, or task-specific reliability — fine-tuning is usually the right tool. The Wikipedia article on fine-tuning lists several approaches you may encounter named in vendor pitches:
- Full fine-tuning. All parameters of the model are updated. Powerful and expensive.
- Low-Rank Adaptation (LoRA). A small set of low-rank matrices are added alongside the original weights and trained. The original weights stay frozen. Far cheaper than full fine-tuning, often with comparable results.
- Parameter-Efficient Fine-Tuning (PEFT). An umbrella framework that includes LoRA and similar lightweight techniques.
- Representation fine-tuning (ReFT). A newer, more targeted method that modifies less than 1 percent of model representations.
You probably need fine-tuning (or one of its variants) when:
- You need a consistent voice, tone, or output format that prompting cannot reliably enforce.
- The task is narrow enough that you can collect a good training set.
- Inference latency matters and you want a smaller fine-tuned model to do the job a larger general model is currently doing.
- The model needs to perform a specific skill reliably, in many contexts, without you having to write a long prompt for every call.
The cost of fine-tuning is the highest of the three: data collection, training infrastructure, evaluation, and ongoing maintenance as the upstream model changes. The trap is using fine-tuning to teach facts. As the RLHF and InstructGPT literature has documented, fine-tuning is unreliable for fact memorisation — you may end up with a model that sounds like it knows your product manual but is just as wrong as the base model on specific questions, only now with more confident phrasing.
Combining them
Real production systems usually combine at least two of the three, often all three.
A typical pattern in a corporate AI assistant: the system runs a fine-tuned model that produces responses in the right company voice and format; a RAG pipeline retrieves relevant passages from internal documents for every query; a carefully written system prompt sets the rules of behaviour and grounds the response in the retrieved passages.
Each layer does work the others cannot do well. The fine-tuned model handles voice and reliability. The RAG layer handles fact recall and up-to-date information. The prompt handles per-call instructions, guardrails, and structure.
When you read “our AI is fine-tuned on your data and uses retrieval-augmented generation,” the vendor is describing this layered architecture, not picking one technique over the others.
A decision frame
For a non-builder evaluating an AI product or pitch, the relevant questions are simpler than the technical taxonomy suggests.
Is the model good enough at this task already, with the right prompt? If yes, do not pay for the rest.
Is what you need from the model a specific fact, or a specific behaviour? Facts point to RAG; behaviours point to fine-tuning.
Do the facts you need change? If yes, RAG is necessary (fine-tuning will go stale; the documents won’t).
Do the behaviours you need need to be consistent across many calls without long prompts? If yes, fine-tuning is the cleanest path.
Are you trying to do both at once? Then you need both, and the question is which layer to start with.
If you can answer those five questions before reading a vendor’s technical architecture page, you will spend less time confused by it and more time evaluating whether the architecture matches your actual problem.
A short glossary
Prompting. Shaping a model’s output by what you write in the input. The cheapest, fastest, lowest-commitment intervention.
Retrieval-augmented generation (RAG). Looking up relevant passages from a controlled corpus and pasting them into the model’s prompt at query time. The standard pattern for “ask my documents” products.
Fine-tuning. Updating the model’s weights on additional training data. Produces a different model with persistent new behaviour.
LoRA / PEFT. Lightweight families of fine-tuning that update only a small portion of the parameters. Most production fine-tuning uses one of these rather than full fine-tuning.
System prompt. The application’s instructions to the model, prepended to the user’s message. Part of prompting; often the highest-leverage prompt to invest in.
Style transfer. Getting a model to produce output in a particular tone, voice, or format. Generally a fine-tuning problem, not a RAG problem.
Fact recall. Getting a model to answer with specific information from a particular source. Generally a RAG problem, not a fine-tuning one.
Further reading: the RAG explainer on this site covers the retrieval side in depth. Wikipedia’s Fine-tuning article walks through the LoRA / PEFT / ReFT lineage.
How we use AI and review our work: About Insightful AI Desk.


