What is vLLM? The open-source inference server that ate the inference stack
The open-source inference server that ate the inference stack. What PagedAttention actually does, how continuous batching works, performance versus TGI / TensorRT-LLM / SGLang, when to pick it, and the LF AI governance that made it vendor-neutral.

By Daniel Park, Insightful AI Desk
In 2023, the dominant problem in serving large language models was simple to state and hard to solve: an A100 or H100 GPU with 80 GB of memory could comfortably fit a 13-billion parameter model — but the moment you tried to serve real traffic, GPU memory ran out long before GPU compute did. The bottleneck was not the matrix multiplications; it was the KV cache, the tensor that grows linearly with each token generated for each active request. Memory fragmentation made the situation worse: a server might have 30 GB of unused KV-cache space and still refuse new requests because that 30 GB was split into a hundred unusable holes.
In June 2023 a team at UC Berkeley released an open-source implementation called vLLM, accompanied by a launch blog post explaining its central idea, PagedAttention. The formal paper — Efficient Memory Management for Large Language Model Serving with PagedAttention, Kwon et al. — was posted to arXiv in September 2023 and presented at SOSP that October. Two years later, vLLM is the inference server that runs most non-trivial open-weight LLM deployments. It is what enterprises self-host. It is what cloud providers use under the hood. It is, in 2026, the default answer to "we want to serve an open-weight model in production."
This post explains what vLLM actually is, the technical idea (PagedAttention) that made it different, how the rest of the architecture works, who uses it and why, and how it compares to the other inference servers you will see in an enterprise stack.
1. What vLLM is, in one paragraph
vLLM is an open-source LLM inference and serving engine, originally from UC Berkeley and now governed as a vendor-neutral project under the Linux Foundation umbrella — accepted as an LF AI & Data incubation project in October 2024. It accepts incoming LLM requests over an HTTP API (OpenAI-compatible by default), batches them dynamically, runs them through a transformer model on one or more GPUs, and returns the streamed output to each caller. The model can be any of dozens of open-weight architectures it supports — Llama, Mistral, Qwen, DeepSeek, Mixtral, Gemma, Phi, Yi, the Stable LM family, and so on.
What makes vLLM significant is not the API (which is mundane) but the throughput. On the same hardware running the same model, vLLM typically serves 2–24× more requests per second than the naive implementation that ships with a model's reference code, depending on workload shape. That gap is the engineering substance of the project, and it is mostly the consequence of two ideas — PagedAttention and continuous batching — that we walk through next.
2. PagedAttention — the core technical idea
To understand PagedAttention, you have to understand the problem it solves.
When an LLM generates output token by token, each new token's computation requires the model to "attend to" every previous token in the conversation. To do that efficiently, the keys and values from earlier tokens are cached in GPU memory — the KV cache. For each request, the KV cache grows with every output token. For a 13B-parameter model serving a 4,000-token conversation, the KV cache for that single request can be hundreds of megabytes. Multiply by hundreds of concurrent requests and the KV cache is what owns the GPU's memory.
In pre-vLLM inference servers, the KV cache for each request was allocated as one contiguous block at the start of the request, sized to the maximum sequence length the model supports. This had two problems. First, most requests don't use the maximum sequence length, so the over-allocation wasted memory. Second, when a request finished and freed its block, the freed memory was useless unless a new request happened to need exactly that size — classical external fragmentation. The result was that a GPU could be sitting on 30% unused KV-cache memory while turning new requests away.
PagedAttention applies the operating-systems insight that paged virtual memory solved this exact problem for CPU processes in the 1960s. Instead of allocating one contiguous block per request, vLLM divides KV-cache memory into fixed-size blocks (typically 16 tokens worth of KV per block). A request is assigned blocks lazily, one at a time, as it generates tokens. Each block can live anywhere in physical GPU memory — the model is told "here are the block addresses for this request" and the attention computation reads from those non-contiguous blocks.
The wins from this design are substantial:
- No over-allocation. A short conversation uses three blocks, not the full 1,000-block worst-case allocation.
- No external fragmentation. A freed block is the same size as any other freed block, so it can be re-used immediately for any incoming request.
- Memory sharing across requests. If two requests start with the same system prompt, they can share the blocks holding that prompt's KV cache — a feature called prefix caching. In a customer-support bot where every conversation starts with the same 500-token instruction, prefix caching halves or better the KV-cache memory pressure.
- Cheap copy-on-write for parallel sampling. Generating multiple candidate completions of the same prompt (n=4 beam search, n=8 best-of) can share the prompt KV blocks until the candidates diverge, then fork only the blocks that differ.
The original vLLM paper reported that PagedAttention reduced wasted KV-cache memory from roughly 60–80% down to under 4%. That number is the headline. Once you have 60–80% more usable KV-cache memory, you can run 60–80% more concurrent requests on the same hardware, and the throughput numbers follow directly.

The systems-research lineage of the idea is worth pausing on. Paging is one of the oldest tricks in operating systems — virtual memory in the 1960s solved exactly the fragmentation problem for CPU processes that vLLM solves for LLM KV cache. The new contribution was recognising that GPU memory management for LLM inference looked structurally identical to a problem the OS community had already solved. A surprising fraction of high-impact ML systems work in 2023–2026 follows this shape: borrow a well-understood OS or database technique, port it to GPU code, get a 10× win. Continuous batching is the same story (it is essentially fair-share scheduling). Speculative decoding is the same story (it is branch prediction). Anyone who knows operating systems has free leverage in ML systems work right now.
3. Continuous batching — the second idea
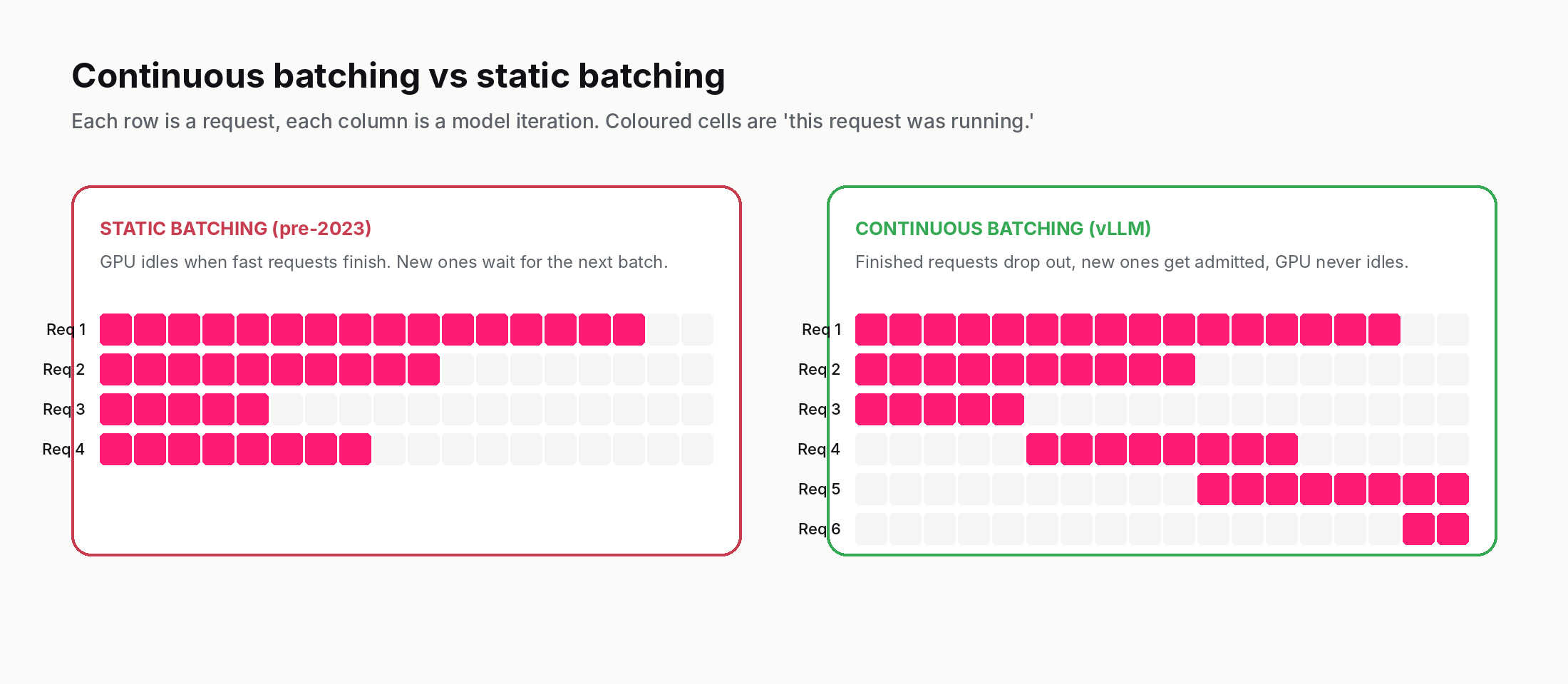
The other improvement vLLM is responsible for popularising — though they were not first to it — is continuous batching, sometimes called iteration-level scheduling.
Pre-2023 inference servers batched requests at the request level: take N requests, run them through the model together, return all N results when the last one finishes. This wasted GPU time. If one request was generating 2,000 tokens and another was generating 50, the GPU spent most of its time waiting for the long request while the short one was already done.
Continuous batching schedules at the iteration level (each model forward pass) rather than the request level. After every iteration, the server can:
- Remove requests that have just generated their EOS token.
- Admit new requests that just arrived from the queue.
- Run the next iteration with whatever requests are currently active.
The GPU never idles waiting for a slow request to finish. New requests are admitted within milliseconds of arriving. The aggregate effect is that GPU utilisation goes from typically 30–40% under static batching to 70–90% under continuous batching, for the same hardware and the same incoming traffic pattern.
Continuous batching was first published in the Orca paper from Seoul National University in 2022, but vLLM was the first widely-adopted open implementation. Today, every serious inference server uses some form of iteration-level scheduling.
4. The architecture, walked through
Underneath the abstractions, a vLLM deployment is a layered system. From top to bottom:
HTTP server. By default vLLM exposes an OpenAI-compatible HTTP API — the same `/v1/chat/completions` and `/v1/completions` endpoints. This was a deliberate design choice. Most LLM-using applications already speak the OpenAI dialect; making vLLM a drop-in replacement is what lets a company switch from a hosted API to self-hosted inference without rewriting client code.
Scheduler. The component that decides, every iteration, which requests run next and which wait in the queue. It enforces priority, preemption (if a high-priority request arrives, lower-priority ones can be paused and their KV blocks evicted), and admission control under memory pressure.
Block manager. The KV-cache memory allocator. It owns the pool of fixed-size physical blocks, hands them out to requests, tracks reference counts for shared blocks, and reclaims blocks when requests complete.
Model executor. The actual model forward pass. vLLM ships hand-tuned CUDA kernels for the attention path that work with the paged KV layout. For the rest of the model (MLPs, normalisation, etc.), it uses PyTorch with custom optimisations.
Distributed runtime. For models that don't fit on a single GPU, vLLM supports tensor parallelism (slicing each layer across multiple GPUs) and, in newer versions, pipeline parallelism (assigning different layers to different GPUs).
The interesting design choice is the separation between scheduler and block manager. In simpler inference servers these two are tangled together — the scheduler implicitly knows about memory and the block manager implicitly knows about request priority. vLLM separates them with a clean interface, which is why adding features like prefix caching and preemption did not require rewriting the scheduler.

5. Performance — what you actually get
The performance numbers depend heavily on workload shape, so any single number is misleading. With that disclaimer, a rough survey of published benchmarks from late 2024 to early 2026:
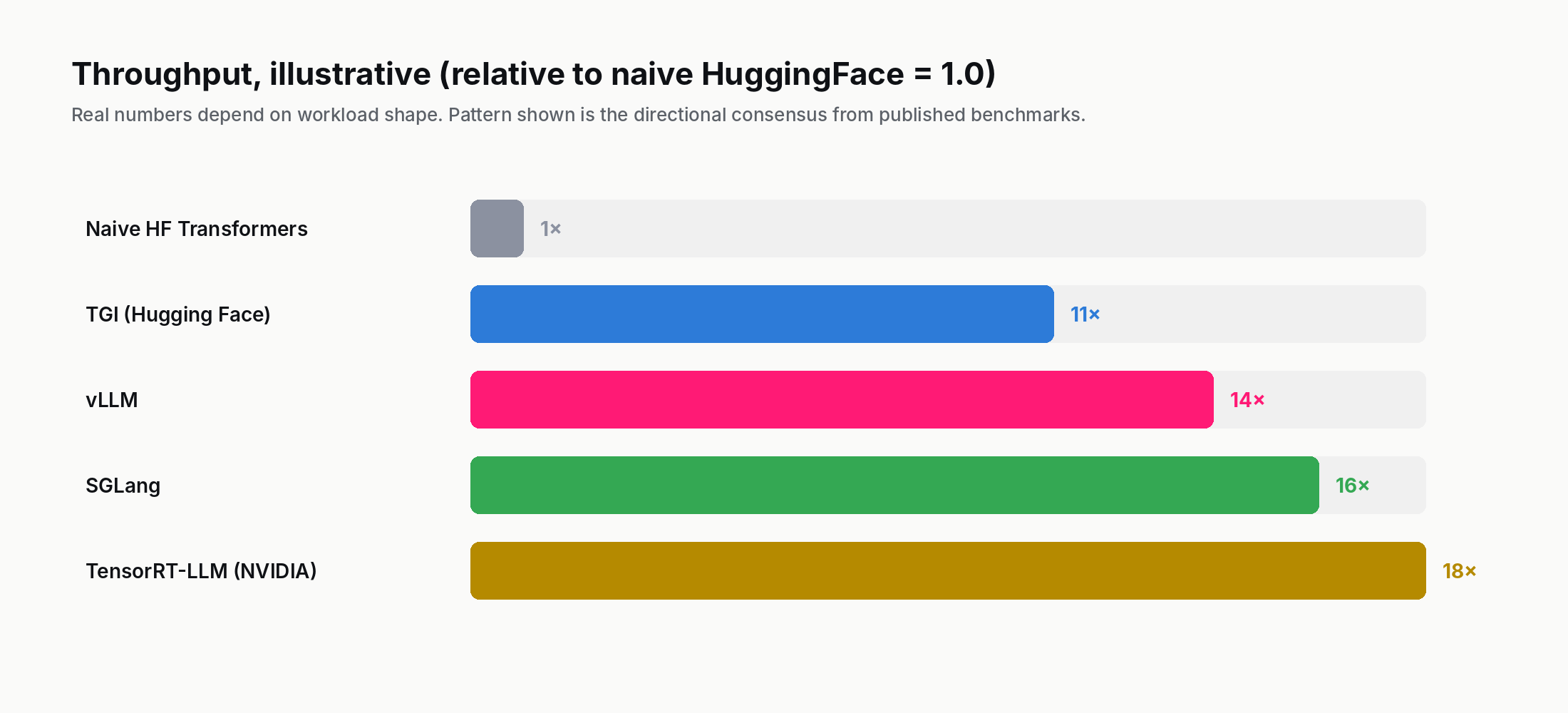
vs naive HuggingFace Transformers: vLLM is typically 8–24× higher throughput on the same hardware, depending on model size and request shape. The naive HF implementation does no continuous batching and no paged KV cache, so this comparison is unfair but is also what an unprepared team often starts with.
vs TGI (Hugging Face's Text Generation Inference): TGI was a strong competitor through 2023 but is now broadly comparable to vLLM on raw throughput, with vLLM typically winning by 10–30% on workloads with long contexts (where PagedAttention's fragmentation savings matter most). TGI has historically been ahead on production-readiness features (multi-LoRA, JSON-mode constraints, queue management); vLLM has narrowed those gaps in 2024–2025.
vs TensorRT-LLM (NVIDIA's native server): TensorRT-LLM is faster on NVIDIA-specific hardware, typically 10–30% above vLLM on identical workloads, because NVIDIA can compile the attention path against the exact silicon. The price is that TensorRT-LLM only runs on NVIDIA GPUs, requires per-model compilation, and is harder to deploy. Most teams that use TensorRT-LLM accept the operational overhead because they care about the last percent of throughput; teams that prefer simplicity stay on vLLM.
vs SGLang: SGLang (a Berkeley-led collaboration with contributors from Stanford and others, first posted in December 2023) targets workloads with complex control flow — branching prompts, structured generation, agentic loops — using a technique called RadixAttention. It outperforms vLLM by significant margins on those specific patterns. For straight request-response generation, vLLM and SGLang are close.
vs proprietary cloud APIs: Direct latency comparisons between self-hosted vLLM and OpenAI / Anthropic / Google APIs are not apples-to-apples because the model is different. The relevant comparison is cost: self-hosting a 70B-parameter open-weight model on vLLM costs roughly 0.10 USD–0.30 USD per million output tokens at 70% GPU utilisation, versus 5 USD–15 USD per million for comparable frontier API access. For workloads that fit open-weight quality, the cost arbitrage is the reason vLLM exists.
One important caveat on all of these comparisons: throughput is not the only metric. Latency under load matters as much for interactive use cases. vLLM's median time-to-first-token is excellent (typically 50–200 ms at moderate concurrency), but its p99 time-to-first-token can spike under heavy queue depth. If your application is conversational and users are watching tokens stream in, a server with worse mean throughput but lower tail latency can feel better. Some teams run vLLM with deliberately low concurrency limits and accept the throughput hit to keep tail latency tame. The decision is workload-specific; the right metric to track is whatever your users actually feel.
6. When to pick vLLM (and when not)
Pick vLLM when:
- You are serving an open-weight model in production and need throughput beyond what a naive implementation gives you.
- You need an OpenAI-compatible API so you can drop it in behind existing application code.
- You care about vendor neutrality — vLLM has first-class support for NVIDIA CUDA and AMD ROCm, with plugin-based support for Google TPU, AWS Neuron, Intel Gaudi, Huawei Ascend, and a growing list of accelerators. (The non-CUDA/ROCm backends are generally build-from-source rather than pre-built images.)
- You want the option to swap models without re-deploying the serving layer — vLLM's model registry covers most popular open-weight families.
- You expect heavy prefix re-use (same system prompt across many conversations), where prefix caching produces a major memory win.
Pick something else when:
- Maximum NVIDIA-only throughput is the only goal. TensorRT-LLM will edge vLLM by 10–30% if you can afford the per-model compile cycle.
- Complex generation patterns are the workload. SGLang's RadixAttention beats vLLM for branching and structured generation.
- Edge / single-user inference on a laptop. Use llama.cpp or Ollama. vLLM is over-engineered for one request at a time on commodity hardware.
- You need a managed offering and don't want to operate the cluster yourself. Use Anyscale, Together, Fireworks, or another vLLM-hosting provider — most of them run vLLM under the hood, but you pay for the operations.
7. Practical deployment notes
A few things teams trip on when deploying vLLM:
KV-cache memory is the first thing to tune. vLLM reserves a configurable fraction of GPU memory for KV cache; the default is 90%. If you are running out of memory at low concurrency, that's usually the dial to turn. If you are leaving throughput on the table at high concurrency, increasing the KV-cache fraction lets the server admit more concurrent requests.
Tensor parallelism is fast on the same node, slow across nodes. Slicing a model across 8 GPUs on one node uses NVLink and is essentially free. Slicing across two nodes adds a network hop between every layer and can cut throughput in half. If your model fits on one node, keep it there.
Quantisation works but matters less than you'd think. vLLM supports AWQ, GPTQ, and FP8 quantisation. For a memory-bound deployment, going from FP16 to FP8 roughly doubles the model count you can fit per GPU. For a compute-bound deployment (small batch, long generation), quantisation buys less throughput than the marketing suggests.
Speculative decoding is a free 1.5–2× throughput win — when it works. vLLM supports speculative decoding (use a small draft model to propose tokens, verify with the big model). On compatible workloads this is the highest-leverage feature added to vLLM in 2024–2025. The catch is that the draft model must be aligned closely enough with the target model that its proposals are accepted most of the time; mismatched drafts produce a net slowdown.
Monitoring matters. vLLM exposes Prometheus metrics for queue depth, KV-cache utilisation, scheduler iteration latency, and per-request token throughput. In a production deployment, "the inference server is slow" almost always traces to one of these metrics being saturated. The dashboard is the first thing to wire in.
8. Governance and the open-source story
vLLM started as a UC Berkeley research project, and for its first 18 months was a Berkeley-led open-source effort with corporate contributors. In 2024–2025 the project went through a governance transition: it was contributed to the LF AI & Data Foundation, an umbrella under the Linux Foundation, with a technical steering committee drawn from Berkeley, AMD, IBM/Red Hat, Roblox, NVIDIA, Snowflake, Meta, Anyscale, and others.
The practical implication is that vLLM is now vendor-neutral in a stronger sense than most "open" inference servers. A model architecture's support in vLLM is unlikely to be removed for commercial reasons; a hardware vendor cannot unilaterally drop another vendor's support. For enterprise procurement, the LF AI governance is the answer to "what happens to vLLM if its corporate backer changes direction" — the answer is "no single corporate backer can change vLLM's direction."
The licence is Apache 2.0, which permits commercial use, modification, and redistribution. Several commercial offerings build on vLLM directly — Anyscale's Ray Serve integration, Red Hat's AI Inference Server, NVIDIA NIM, Modal, RunPod, and IBM watsonx are visible examples. Other inference providers (Together AI, Fireworks AI) run their own proprietary engines and explicitly benchmark against vLLM rather than build on it. The pattern is typical for successful open-source infrastructure: the project is free, several distinct paid offerings layer on top, and a parallel set of competitors implements something different that defines itself relative to it.
The size and shape of the contributor community is itself a useful signal. As of late 2025, vLLM has more than 1,000 contributors with merged commits, double-digit weekly pull requests merged, and active code review from multiple chip vendors. The contributor concentration that worries open-source-procurement teams (one company contributing 80% of commits) does not apply: contributions are distributed across UC Berkeley, AMD, IBM/Red Hat, NVIDIA, Meta, and a long tail of independent contributors. This is the kind of distribution that survives any one corporate sponsor walking away.
A related point: vLLM's release cadence is fast. Major releases ship roughly every 2–4 weeks. New open-weight model architectures typically land support within days of their public release — the team's reputation is that if a Llama 5 or Qwen 4 ships on Monday, vLLM has a working implementation by Wednesday. For a team standing up self-hosted infrastructure, that responsiveness is the difference between "we can ship this week" and "we have to wait a quarter."
9. Where to read next
The primary source is the original PagedAttention paper: Kwon et al., SOSP 2023. Forty pages, technically detailed, and surprisingly readable for a systems paper. The most useful 10 minutes you can spend if you want to understand the project's technical foundations.
The project's home is github.com/vllm-project/vllm and the documentation site at docs.vllm.ai is well-maintained. The "Quickstart" page gets a single-GPU deployment running in about ten minutes; the "Production" section is where the operational nuance lives.
For the broader inference-stack picture, our explainer on FinOps for AI covers the cost-side considerations, and Model routing covers the layer that sits in front of multiple inference servers in a real enterprise deployment.
If you want the full curriculum, the entry point is the AI Encyclopedia — 130 phases, 2,600 concepts. Inference serving sits in Phase 108 (AI Inference and Serving).
The one-line takeaway, if you keep one thing: vLLM made open-source LLM inference cost-competitive with proprietary APIs, and PagedAttention is the operating-systems idea that did it.
Further reading: Efficient Memory Management for Large Language Model Serving with PagedAttention (Kwon et al., SOSP 2023), Orca: A Distributed Serving System for Transformer-Based Generative Models (Yu et al., OSDI 2022), vLLM documentation.
How we use AI and review our work: About Insightful AI Desk.