Model routing is the quiet control layer behind enterprise AI
Model routing decides which AI model should answer each request. It is how enterprises cut inference cost without blindly sacrificing quality.
By Marcus Wong, Insightful AI Desk
Every company that deploys AI eventually discovers the same uncomfortable fact: there is no single best model. There is a best model for a particular task, at a particular latency target, with a particular privacy constraint, under a particular budget. That is a different problem from picking a favourite model in a benchmark table.
The control layer that handles this problem is called model routing. A router looks at an incoming request and decides which model should answer it. Sometimes the cheap model is enough. Sometimes a specialist model is better. Sometimes the request needs a frontier model. Sometimes the safest answer is not to call any model until the request is rewritten, filtered, or sent to a human.
This is not a theoretical concern. AI budgets are now large enough that using the strongest model for every request is wasteful, but quality risk is high enough that using the cheapest model for every request is reckless. Model routing is the compromise: use the least expensive model that can satisfy the job, and escalate when the job demands it.
What model routing is
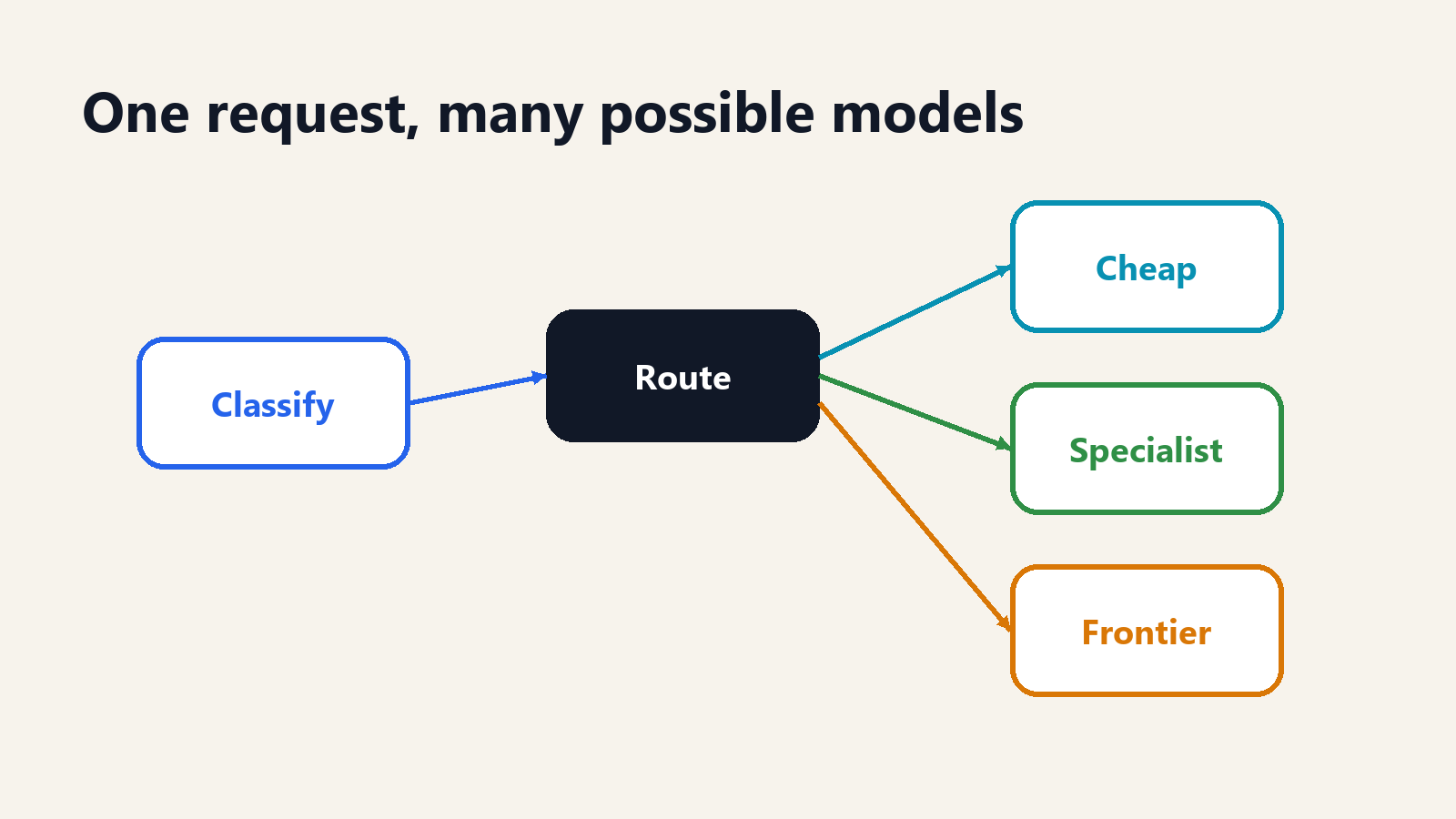
Model routing is the practice of sending different AI requests to different models based on the request's needs. The router may be a few rules, a classifier, an embedding search, a learned model, a benchmark-driven policy, or a full orchestration layer that measures cost and quality over time.
The simplest router is a rule. If the request is classification, send it to a small model. If the request contains legal text, send it to the legal model. If the request is longer than a threshold, send it to a long-context model. This works when the categories are clear and the cost of a mistake is low.
A more advanced router estimates difficulty. It asks whether the question is easy enough for a cheaper model or difficult enough to justify a stronger one. This can be done with heuristics, small classifiers, or learned routers trained on preference data and historical outcomes. The academic literature has been moving in that direction for several years. FrugalGPT, published in 2023, framed the problem around cascades that reduce inference cost while preserving or improving quality. RouteLLM, released in 2024, learned to route queries using preference data. The implementation details differ, but the economic point is the same: not every request deserves the expensive model.
For enterprise buyers, the definition can be even simpler. Model routing is the part of the AI stack that decides when to spend more.
Why one model is not enough
The one-model strategy is attractive because it is simple. Pick the model that performs best in public rankings, connect it to the product, and move on. That strategy works for prototypes. It becomes expensive and fragile in production.
It is expensive because many requests are routine. A support chatbot does not need a frontier reasoning model to classify “where is my invoice?” A coding assistant does not need the strongest model to format a changelog. An internal knowledge assistant does not need maximum reasoning depth to answer a policy question whose answer is retrieved from a handbook. These tasks need reliability, not maximal intelligence.
It is fragile because the strongest general model is not always the best operational choice. A smaller model may be faster. A local model may be required for sensitive data. A specialist model may handle code, tables, or extraction more consistently. A cheaper model may be easier to scale during traffic spikes. A provider-specific model may be unavailable during an outage. A router gives the system options.
The real production question is not “which model is smartest?” It is “which model should handle this request under today's constraints?” That question changes by task, customer, geography, data sensitivity, and budget.
The routing signals that matter
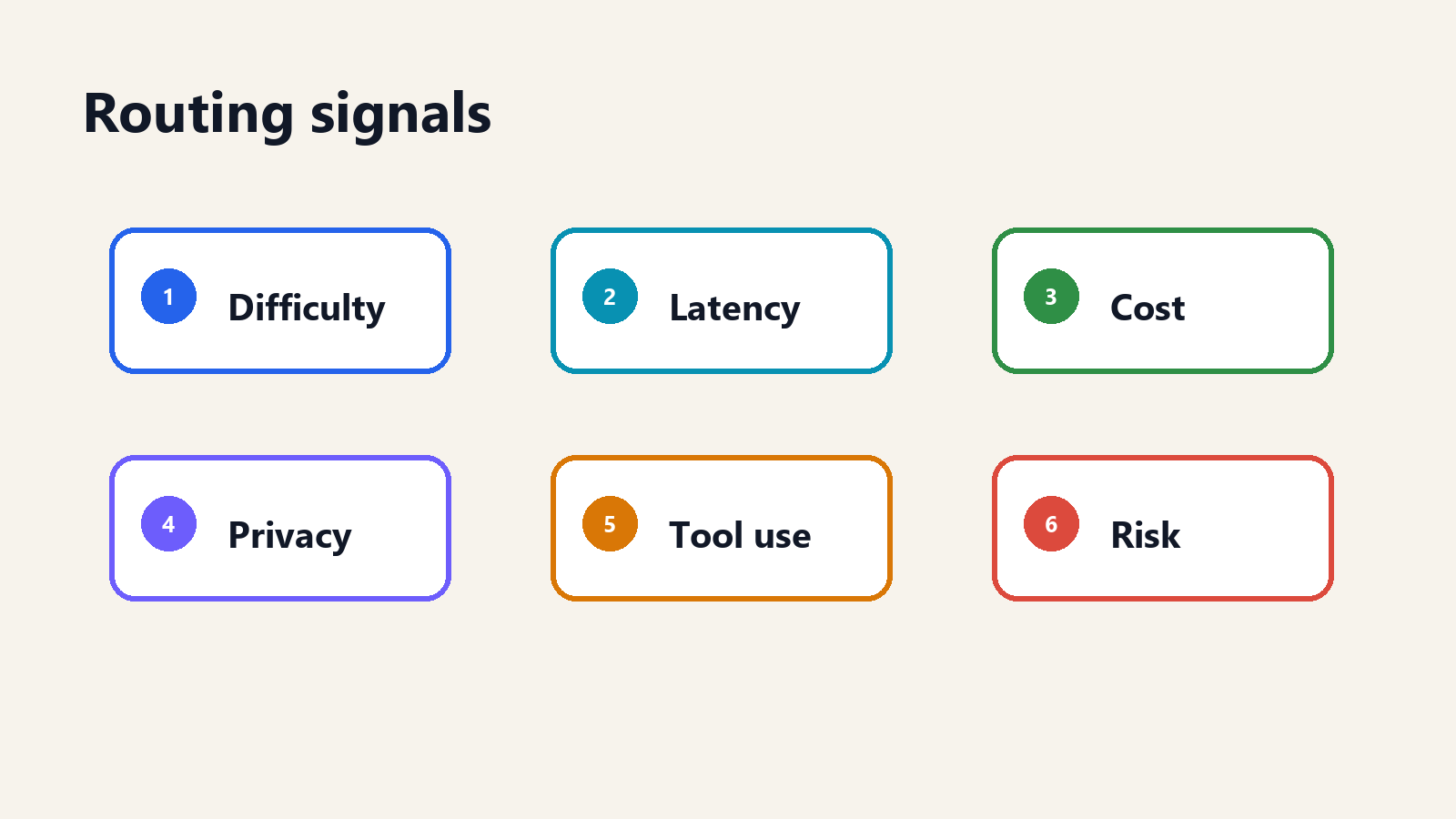
A useful router needs signals. The most common ones are difficulty, latency, cost, privacy, tool use, and risk.
Difficulty is the obvious one. Some requests require multi-step reasoning, ambiguous judgment, or long-context synthesis. Others are simple classification, extraction, or rewriting. The router's job is to avoid overpaying for the latter and underpowering the former.
Latency matters because a model that gives the best answer too slowly may not be the best product choice. Real-time user interfaces often prefer a slightly weaker model that responds quickly. Back-office workflows may tolerate slower but stronger models.
Cost is not just price per token. The full cost includes prompt size, output length, retries, tool calls, cache misses, and escalation rate. A model with cheaper tokens can be more expensive if it fails more often and forces retries.
Privacy determines where data is allowed to go. Some requests can be sent to any approved provider. Others must stay in a specific region, run on a private endpoint, or use a self-hosted model.
Tool use matters because not all models are equally reliable at structured output, function calling, or multi-step agent loops. A router may send tool-heavy requests to the model that follows schemas best rather than the model with the highest general benchmark score.
Risk determines escalation. A wrong answer in a game hint is different from a wrong answer in a medical triage workflow, procurement approval, or security alert. High-risk tasks may need stronger models, human review, or both.
Routing versus cascading
Routing and cascading are related but not identical.
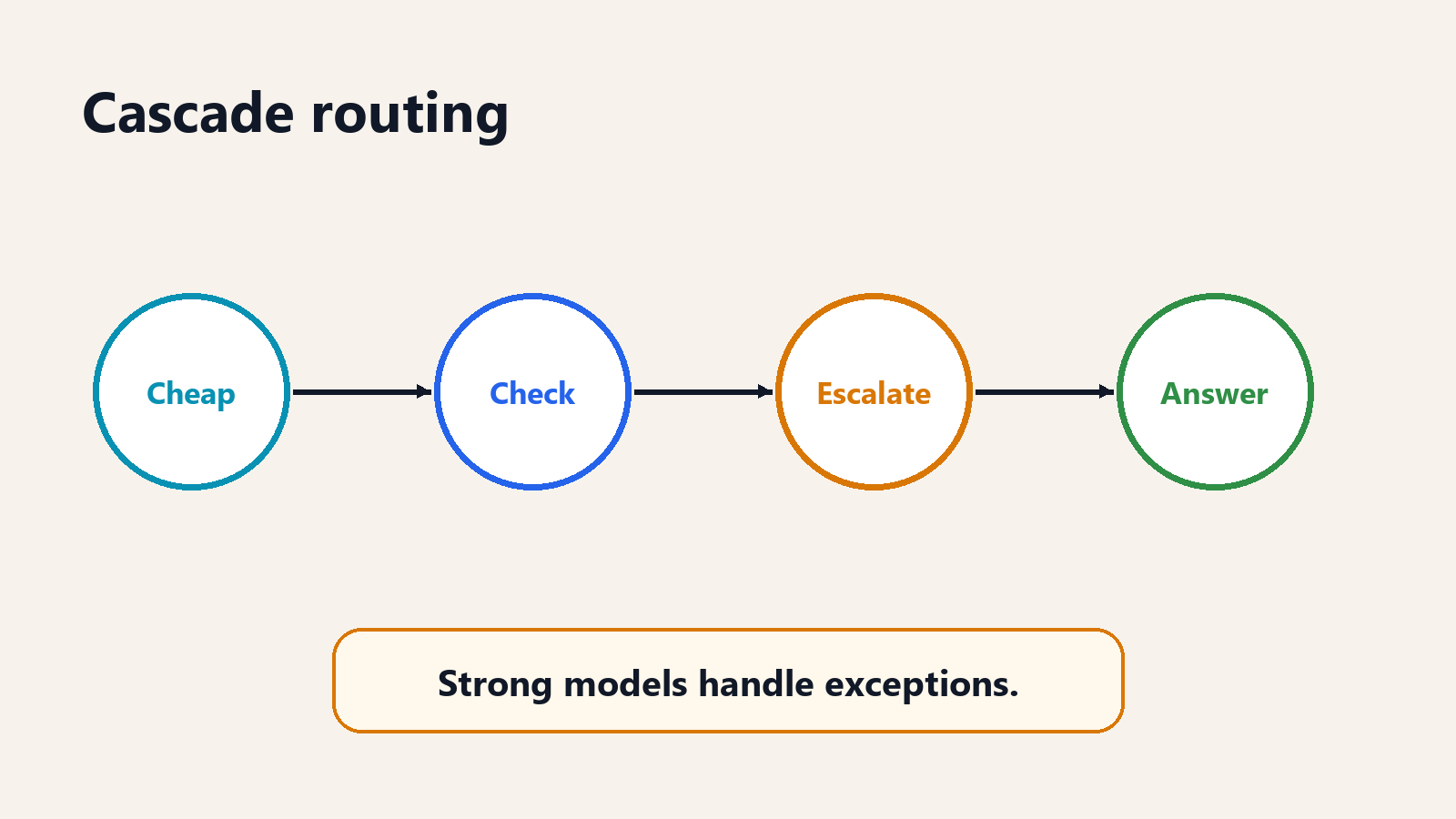
In simple routing, the system chooses one model before generation. It looks at the request and decides: send this to the cheap model, the specialist model, or the frontier model. This is fast and clean, but it depends on the router being right upfront.
In cascading, the system may try a cheaper model first, then check whether the result is good enough. If the answer fails a confidence test, policy check, evaluator, or user threshold, the system escalates to a stronger model. Cascading is often easier to reason about because it creates a quality gate: cheap first, strong when needed.
The tradeoff is latency. A cascade can be cheaper on average but slower on difficult cases because the system spends time trying the cheap path before escalation. That may be acceptable for document processing and batch workflows. It may be unacceptable for real-time chat. The right pattern depends on the product.
The four routing patterns
Most production routers combine four patterns.
Rule-based routing is the starting point. It is explicit, explainable, and easy to audit. Send personally identifiable information only to approved private endpoints. Send translation to the translation model. Send image prompts to the vision-language model. Send low-risk classification to the small model. Rules are blunt, but blunt is sometimes good. A compliance team can understand them.
Classifier routing uses a small model or traditional classifier to predict request type or difficulty. This is useful when rules become too numerous. A support system might classify requests as billing, cancellation, technical issue, complaint, or regulated advice, then send each class to a different path. The classifier does not need to solve the user problem. It only needs to choose the lane.
Evaluator routing checks an answer after generation. The system asks a cheaper model first, then runs a judge, verifier, unit test, policy checker, or human-review trigger. If the result fails, it escalates. This is common in code, extraction, and structured workflows because outputs can often be tested.
Learned routing trains a router on historical performance. It may learn that a particular model handles spreadsheet questions well, that another model is better at legal summaries, or that a small model fails on specific edge cases. This can outperform hand-written rules, but it creates a new model to govern. The router itself now needs monitoring.
The practical path is usually staged: start with rules, add classifiers where traffic grows, add evaluators where quality is testable, and learn from production traces only after the organization has enough data to make learning meaningful.
Where routing saves money
Routing saves money where request difficulty varies. If every request is hard, routing adds little. If every request is easy, a single cheaper model may be enough. The opportunity appears when the workload contains a mix.
Customer support is a common example. Password-reset questions, invoice lookups, order-status requests, and policy summaries can often run on cheaper models. Complaint escalation, ambiguous policy exceptions, high-value customers, or regulated advice may need stronger models or humans. A router can separate routine from sensitive work.
Developer tools are another example. Formatting, search summarization, simple refactors, and test-name generation may not need the strongest model. Architecture changes, subtle bug diagnosis, security review, or cross-file reasoning often do. A coding assistant that routes every step to the strongest model may feel good in a demo and look ugly on a bill.
Document workflows have the same shape. Extraction from a standard form is different from legal interpretation of a novel clause. Summarizing meeting notes is different from comparing a contract against a policy. The model portfolio should reflect that variation.
What a router needs to log
A router that cannot explain its own decisions is hard to trust.
At minimum, it should log the request category, selected model, rejected alternatives, estimated cost, actual cost, latency, escalation decision, and quality signal. The quality signal may be a user rating, human review, verifier result, unit-test outcome, policy-check result, or downstream acceptance metric. Without a quality signal, the router is optimizing blind.
The logs should also preserve why a request was routed. If the request went to a private model because it contained sensitive data, the log should say that. If the request went to a frontier model because difficulty was high, the log should say that. If the request escalated because the cheap model failed a schema check, the log should say that. These explanations do not need to be verbose. They need to be structured.
This matters during incidents. Suppose a customer receives a bad answer. The team needs to know whether the router chose the wrong model, whether the selected model failed, whether the evaluator missed the failure, or whether the policy allowed an unsafe path. Those are different fixes. Without logs, every routing failure becomes a blame cloud.
It also matters during procurement. If a vendor says its routing layer saves 40 percent, the buyer should ask 40 percent compared with what baseline, on what traffic, under what quality floor, and with what escalation rate. A router's savings claim is not meaningful without the traffic mix.
Where routing can go wrong
Routing fails when it hides quality risk behind cost savings.
The first failure is under-routing. The system sends a hard request to a cheap model, the answer looks plausible, and no one notices the mistake until later. This is especially dangerous in workflows where the user does not have enough expertise to judge the answer.
The second failure is over-routing. The system sends too much to the expensive model because the router is conservative or poorly calibrated. Quality is fine, but the economic benefit disappears. This is safer than under-routing but defeats the purpose.
The third failure is unstable routing. Small wording changes send similar requests to different models, producing inconsistent user experiences. Users do not care that the router had a confidence threshold. They care that the product seems arbitrary.
The fourth failure is provider coupling. A company thinks it has a multi-model strategy, but the routing layer is hard-coded around one provider's features, pricing, or tool-call format. When the provider changes terms or suffers an outage, the router is not portable.
The fifth failure is evaluation leakage. The router is trained or tuned on benchmarks that do not match production traffic. It saves money in tests and disappoints in the product. This is why production traces, shadow traffic, and human review remain important.
How to roll it out safely
The safest rollout is not to flip all traffic to a router on day one.
Start with shadow routing. The production system continues sending requests to the current model, while the router quietly records where it would have sent each request. This reveals the proposed traffic split without changing user experience. If the router wants to send 80 percent of traffic to the cheap model, the team can inspect whether that is plausible before risking it.
Next, run offline replay. Take historical requests with known outcomes and simulate the router's decisions. This is not perfect because historical traffic may not represent future traffic, but it catches obvious mistakes. If the router sends high-risk cases to a cheap path, the team sees that before launch.
Then move to canary routing. Send a small percentage of low-risk traffic through the router. Compare cost, latency, user feedback, human corrections, and fallback rate against the baseline. The canary should have rollback controls. The team should know exactly how to disable the router if quality drops.
After that, expand by segment. Do not route everything at once. Route one product area, one geography, one task type, or one internal workflow. Each segment teaches the router team where the assumptions hold and where they break.
Finally, set review cadences. Model prices change. Model capabilities change. Provider reliability changes. User traffic changes. A routing policy that was rational in January may be wasteful or risky by June. Routing is not a set-and-forget feature. It is an operating practice.
What buyers should ask
Model routing sounds technical, but the buyer questions are straightforward.
What percentage of traffic goes to each model? If the vendor cannot answer, it does not have a routing strategy; it has a black box.
What triggers escalation? The answer should include quality thresholds, risk categories, fallback rules, or evaluator outputs, not just “the system decides.”
What is the quality floor? A router should never save money by letting unacceptable answers through. The quality floor is the minimum standard that cheaper paths must meet.
How often does the router change its mind? If similar inputs bounce between models, user experience and debugging become difficult.
What happens during provider failure? A router should not only optimize good days. It should degrade gracefully when one model is down, slow, or rate-limited.
How is cost allocated? If routing saves money for one team but increases risk for another, the governance model needs to make that visible.
A practical example
Consider an internal support assistant for a 5,000-person company.
The assistant receives questions about passwords, benefits, expenses, procurement, security policy, travel, and legal approvals. A one-model design sends every question to the strongest general model. It works, but the bill is high and sensitive requests leave more infrastructure than necessary.
A routed design separates the traffic.
Password and access questions go to a small model with retrieval over IT documentation. Benefits questions go to a model approved for HR content. Expense-policy questions go to a cheap model unless the amount is large or the user asks for an exception. Security-policy questions go to a stronger model with stricter citation requirements. Legal-approval questions do not produce final answers; they prepare summaries for a human reviewer.
The system is not only cheaper. It is clearer. Each lane has a different risk profile, evaluation method, and owner. IT owns password accuracy. HR owns benefits policy. Security owns security-policy escalation. Legal owns legal-review boundaries. The router becomes a governance map.
This is the enterprise value of routing. It is not only that fewer requests hit the expensive model. It is that the organization stops pretending every AI request is the same kind of work.
The FinOps connection
Model routing belongs inside AI FinOps because it connects usage to business value. Token price alone is a weak signal. Cost per resolved support ticket, cost per reviewed pull request, cost per contract summary, or cost per qualified sales lead is more useful. A router that reduces token spend while increasing human rework has not saved money. It has moved the cost.
The mature version of routing is therefore not just a technical policy. It is a feedback loop. The system routes a request, observes cost and quality, records whether the answer was accepted, and updates thresholds over time. Cheap paths should earn more traffic when they perform well. Expensive paths should remain available when the cheap path fails.
This is also where routing connects to procurement. A company that uses only one model provider has limited leverage. A company with a router can compare providers on real workloads, shift traffic gradually, and negotiate from usage evidence rather than benchmark claims.
The human override
Good routing systems leave room for human judgment.
Users should be able to escalate when they believe the answer needs a stronger model or human review. This does not mean every user gets unlimited premium-model access. It means the product should expose a controlled override path. If users constantly override the router, the router is miscalibrated. If users never can, the product may trap them in a low-quality lane.
Human override data is also useful training data. When users repeatedly escalate a category of request, the router team has found a mismatch. Maybe the request looks easy to the classifier but is hard in practice. Maybe the cheap model produces fluent but incomplete answers. Maybe the user is asking a high-stakes question that the system should have recognized.
The override should therefore be logged as a signal, not treated as an annoyance. Routing improves when the system learns from the moments people distrust it.
Where this goes next
The next phase of enterprise AI will not be one model replacing another. It will be portfolios of models behind routers. Large general models will remain important, but they will increasingly sit alongside small models, specialist models, local models, and evaluation systems.
That changes the buying conversation. The question moves from “which model should we buy?” to “what model portfolio should handle our work?” The portfolio needs routing rules, observability, fallback paths, and governance. Without those, adding more models creates complexity without control.
For builders, routing is a product feature. Users should not need to choose models manually for every task. They should be able to set priorities: fastest, cheapest acceptable, highest quality, private only, or human-reviewed. The system should make the routing decision and expose enough information to earn trust.
For executives, routing is a budget discipline. The strongest model is no longer the default answer to every AI problem. It is a scarce resource to deploy where it matters.
The bottom line
Model routing is not a trick for shaving a few cents off an API bill. It is the control layer that makes multi-model AI operational.
Used well, routing lowers cost, improves resilience, and lets teams match model capability to task risk. Used poorly, it hides quality failures behind an optimization story. The difference is auditability.
The enterprise AI stack is moving from model selection to model allocation. The companies that learn to route well will spend less, fail more gracefully, and understand their AI systems better than companies that send every request to the same expensive endpoint and call it simple.
Further reading: the FrugalGPT paper introduced a practical cascade framing for reducing LLM inference cost. RouteLLM explores learned routing with preference data. The UC Berkeley Sky Computing Lab RouteLLM project page summarizes cost-saving claims and benchmark context.
How we use AI and review our work: About Insightful AI Desk.

