What is FinOps for AI? Managing the GPU bill before it manages you
FinOps is the discipline for putting structure around variable technology spend. AI breaks the cloud cost model in three ways — and this is what the new practice looks like.
By Marcus Wong, Insightful AI Desk
Two budget lines have moved disproportionately on every enterprise cloud spend report through 2024 and into 2025. The first is the GPU instance line in the compute category. The second is the AI service line where the bill is denominated in tokens rather than hours. Either is now plausibly the largest single item in a CIO’s technology budget. In some cases the two together exceed every other category combined.
The discipline that has emerged for putting some structure around this kind of spend has a name. FinOps. The framework was originally built for cloud and is now being adapted to the AI cost shape, which is meaningfully different. This piece walks through what FinOps actually is, where the AI variant departs from the cloud original, and what a non-engineering buyer should ask before signing the next purchase order.
What FinOps actually is

The FinOps Foundation, a Linux Foundation project, defines the discipline in one sentence: “FinOps is an operational framework and cultural practice which maximizes the business value of technology, enables timely data-driven decision making, and creates financial accountability through collaboration between engineering, finance, and business teams.”
Three things are doing work in that sentence.
Operational framework. FinOps is a set of practices, not a tool. The Foundation has spent years standardising what those practices are. The framework describes three iterative phases, named Inform, Optimize, and Operate, that any FinOps programme cycles through. There are tools that help (cost-explorer dashboards, tagging strategies, allocation engines, anomaly detectors) but they are means, not ends.
Cultural practice. The framework explicitly insists that FinOps lives in the space between engineering, finance, and the business. Not inside any one of them. An engineering team that picks its own instance types without seeing the unit economics is not doing FinOps. A finance team that issues monthly chargebacks without engineering visibility into what drives them is not doing FinOps either. The discipline assumes both groups are at the same table.
Maturity model. Rather than “before-and-after,” the Foundation describes a Crawl, Walk, Run progression. Most enterprises start in Crawl (reactive, ad-hoc, surprised by the bill) and progress over years toward Walk and Run, where cost is a first-class engineering signal and procurement decisions are made before workloads are committed, not after.
For most of the last decade this was a cloud-specific discipline. The bills came from AWS, Azure, and Google Cloud. The heavy lifting in cloud FinOps was allocating those bills across teams, products, and customers, then optimising each. The arrival of large-scale AI changed the cost shape, and the framework has been catching up.
Why AI is a different cost shape
The cloud cost model FinOps was built for has three predictable axes: compute hours, storage gigabytes per month, and egress bandwidth. Most of the heavy lifting in cloud FinOps is allocating those three across teams and customers, then optimising each.
AI workloads break the model in three ways.
Token economics. When a developer calls a hosted-model API, the cost is denominated in tokens, subword units of input and output. The unit price typically differs between input and output, between model tiers, and between latency-optimised and throughput-optimised endpoints. There is no instance-hour mapping. A single user request can range from a few hundred to several hundred thousand tokens depending on prompt size and response length. The FinOps Foundation has named this out explicitly on its AI Value page: the focus area is “FinOps for AI with Token Economics,” making the token side a first-class category.
Training versus inference are different planets. Training a model is a capital-style expense, large and lumpy with a defined endpoint. Inference is operational, small per-call but scaling with traffic and never stopping. A FinOps practice that treats these the same way will mis-budget both. Training’s natural accounting peer is a hardware purchase; inference’s natural accounting peer is a SaaS subscription priced per seat.
The bill is partly opaque. Hosted-model providers do not always publish the same level of resource detail as cloud vendors. A token-priced API call gives you exactly what the bill says (tokens in, tokens out, dollars charged), with much less visibility than a VM-hour bill into what underlying capacity you are consuming. Self-hosted models invert this: you see every GPU-second, but the cost-per-useful-output is now your engineering team’s problem to compute.
Together, these three changes mean cloud FinOps practices port over partially. The vocabulary survives. The reference activities mostly survive. The specific tactics need rewriting.
The cost categories worth tagging

A FinOps practice begins with seeing the bill. For AI workloads the categories worth separating in the financial ledger are not the same as the ones cloud bills break out by default. The minimum useful taxonomy:
- Hosted-model inference. Per-token charges from API providers. Should be tagged by product, by feature, and ideally by user cohort.
- Self-hosted inference compute. GPU-hour costs for any model served in-house, including HBM-equipped accelerators on cloud rental or on-prem.
- Training and fine-tuning compute. Separate from inference compute even if the underlying instances are similar; training is capital-style and benefits from being capitalised or amortised in the books, not run-rate charged.
- Embedding and retrieval infrastructure. The cost of running a vector database, the embedding-model calls used to populate it, and the storage and bandwidth that supports retrieval-augmented generation pipelines. Often overlooked in early AI budgets and material at scale.
- Data-labelling and human-in-the-loop services. Vendor charges for human annotators or preference-data collection. Tracked alongside training spend.
- Evaluation and red-teaming. Often a sub-line of total cost; worth tracking separately because the right answer is usually “more of it,” and the team that holds the budget will not advocate for it unless they can see it.
If your cloud cost report today buckets all of these under a single “AI” or “ML” line, you are at Crawl. Splitting them out is the first concrete step.
What cloud FinOps practices still apply
Three of the standard cloud FinOps practices carry over almost unchanged.
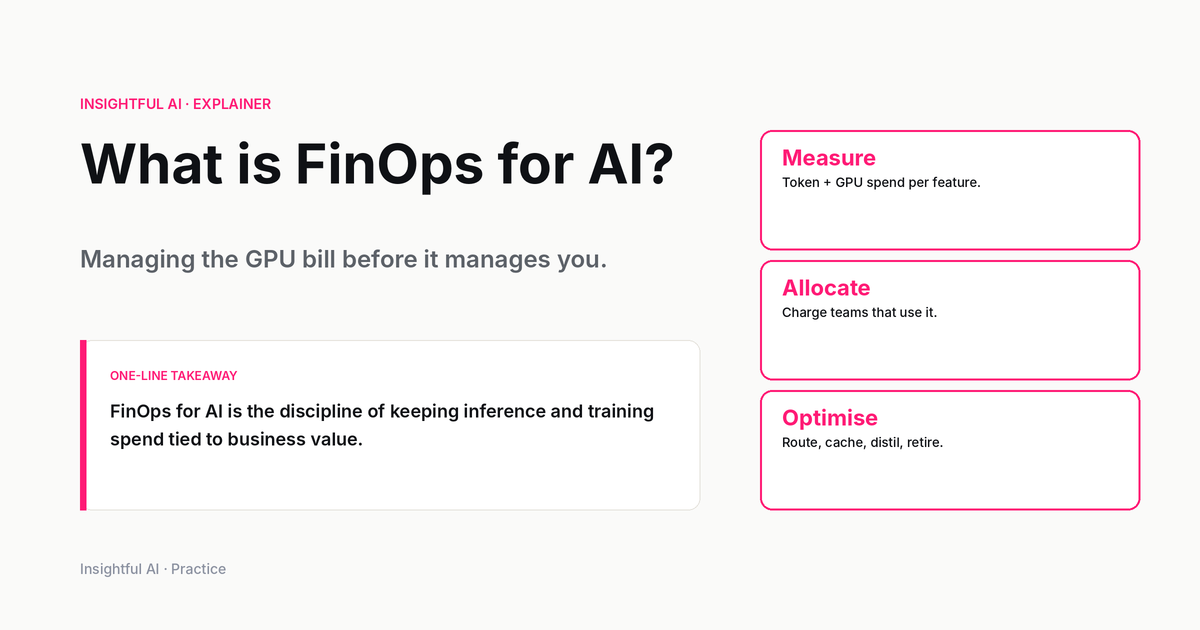
Tag everything. Every API call, every training job, every embedding update should carry a tag identifying the product, the team, and the cost centre. Without this, allocating cost to value is guesswork. Most cloud platforms support tagging on AI workloads; most hosted-model providers support metadata fields on API calls. Use them.
Allocate to the unit of business value. The headline number that matters is not “dollars on the cloud bill” but “dollars per customer interaction” or “dollars per ticket resolved by the AI assistant.” This is the part that requires engineering and finance teams to be in the same room. The engineering team has the usage data, the finance team has the revenue, and the unit economics only emerge when both are joined.
Detect anomalies early. A single bug that doubles the prompt length on a high-traffic feature can put a six-figure dent in the next month’s bill before anyone notices. Production AI systems benefit from the same kind of anomaly detection that traditional FinOps applies to cloud spend, plus AI-specific signals: tokens-per-request distributions, model-tier mix, retry rates.
What the AI variant adds
Three tactics are AI-specific and worth surfacing.
Model-tier routing. Different model tiers from the same provider have order-of-magnitude different per-token prices. A FinOps-mature AI system routes each request to the cheapest tier that produces an acceptable answer. The classification step that does this routing is itself a model call, usually a small cheap one, and its accuracy directly determines the cost saving. Vendor case studies and practitioner reports describe inference cost reductions in the range of 50 to 80 percent from model-tier routing alone, though publicly comparable benchmarks across providers remain scarce. The savings only materialise after a team has built the evaluation infrastructure to know what “acceptable answer” means for their use case.
Prompt and context optimisation. The single biggest controllable cost on a hosted-model call is the size of the prompt. Long system prompts that repeat the same boilerplate on every call, retrieved RAG passages that are not actually being used, conversation histories that are never trimmed: all of these inflate token bills without improving outputs. Practitioner reports of prompt-size audits routinely surface two- to fivefold token reductions in production code paths.
Capacity reservations and committed-use discounts. Hosted-model providers and cloud GPU rental markets both offer reserved-capacity pricing that can cut inference cost meaningfully in exchange for usage commitments. For workloads with predictable baseline traffic, the math nearly always favours some reserved capacity. The question is what percentage. This is straight from the cloud FinOps playbook, applied to a new pricing surface.
From cost management to AI value

The FinOps Foundation’s framing of the AI workstream is striking on a close read. The AI Value page does not lead with “reduce AI costs.” It leads with the observation that “managing AI cost is only the beginning. The real question is whether AI investments are creating measurable business value.”
The reframe matters. AI spend that produces no measurable value is not a cost-optimisation problem; it is a business-case problem. A FinOps practice that focuses entirely on reducing the AI bill, without also instrumenting the value side, can end up cutting the wrong things. Reducing spend on the workload that was actually working while leaving running the experiments that were not.
A mature AI FinOps practice tracks two ledgers in parallel: the cost ledger above and a value ledger that links AI spend to outcomes (tickets resolved, leads qualified, code reviews accelerated, support deflected). The unit-economics ratio between the two is what the framework is ultimately trying to optimise.
What to ask before the next purchase
For a non-engineering leader signing off on an AI procurement, four questions are worth asking before the contract is countersigned.
How is the proposed system priced? Per token, per seat, per request, per GPU-hour? The pricing axis determines which FinOps tactics apply.
What is the expected usage profile, and what does the cost look like at the high end of a plausible adoption curve? Vendor pricing examples are typically based on conservative usage. The interesting number is the spend at the eightieth-percentile usage scenario, not the median.
What is the measurable business outcome this spend is meant to produce, and how will we know whether it has? If the answer is vague, the procurement is a research budget, not an operations budget, and should be treated accordingly.
What does an exit look like? If usage scales faster than expected, or the model tier matures and prices drop, or a competing offering becomes meaningfully cheaper, how locked in are we? Contract terms around data egress, prompt portability, and contractual minimums matter more than the headline rate.
None of these questions require technical depth. They are the questions a competent procurement function would ask about any technology purchase, applied to a category that did not exist three years ago.
Further reading: the FinOps Foundation publishes the canonical definitions and the full FinOps Framework with capability and persona detail. The AI Value topic page is where the AI-specific guidance is being assembled and the FinOps for AI overlay is being developed.
How we use AI and review our work: About Insightful AI Desk.