What is symbolic AI? The original recipe — and where it still wins
Symbolic AI was the original AI — rules, search, logic, expert systems. It lost the photogenic half of the field after 2012 but still wins where transparency, hard constraints, and audit trails matter. With a paired expert-system lab.
By Kenji Tanaka, Insightful AI Desk
For the first thirty years of artificial intelligence, "AI" meant only one thing: symbolic AI. The field was founded on the bet that intelligence could be reproduced by writing down enough rules, in a formal language, and letting a machine apply them. From the Dartmouth Workshop in 1956 through the expert-systems boom of the 1980s, this was the dominant programme. Then, in a single decade after 2012, statistical learning ate everything and "AI" came to mean something very different.
Symbolic AI is not dead — it is just less photogenic. Tax software, theorem provers, chess engines, route planners, regulatory-compliance engines, and the safety filters around large language models all use symbolic methods, often as the load-bearing component. This post walks through what symbolic AI is, the three main techniques inside it, why it lost the spotlight, where it still wins in 2026, and why a new generation of "neuro-symbolic" research is bringing it back into the conversation.
🎯 Companion lab: Make your own expert system — edit a small set of IF–THEN rules and watch them classify ten test cases. You will hit the brittleness wall — the moment your rule set encounters a case it cannot handle — yourself, in about thirty seconds. That experience is the entire reason machine learning eventually replaced this approach for most production tasks.
1. The definition that has not changed in 70 years
Symbolic AI is the family of techniques that represent knowledge as explicit symbols and rules, then apply those rules to derive conclusions. The symbols can be words, predicates, mathematical expressions, or any token a programmer chooses; the rules are written by humans, in a formal language the machine can interpret. The intelligence is in the rules. The machine's job is to apply them faithfully.
If you have ever written a tax-return calculation, a unit converter, a SQL query optimiser, or a regex-based spam filter, you have written symbolic AI. The category includes:
- Production systems — collections of IF–THEN rules, executed by a rule engine. The dominant 1970s/80s AI paradigm.
- Search algorithms — alpha-beta in chess, A* in pathfinding, branch-and-bound in optimisation. The intelligence is the heuristic that guides the search.
- Logic programming — Prolog and its descendants. Programs are expressed as logical relations; the engine derives consequences automatically.
- Theorem provers — systems that derive new theorems from axioms by formal proof.
- Constraint solvers — SAT/SMT/ILP engines that find variable assignments satisfying logical constraints.
- Knowledge graphs — structured representations of entities and their relations, queryable with formal queries.
What unites all of these: a human writes down what to do. The machine does not learn from examples. There is no training data; there is a knowledge base, written by a person.
2. The Dartmouth bet — why anyone thought this would work
The founding document of artificial intelligence is John McCarthy's 1955 proposal for the Dartmouth Summer Research Project. Its central claim is one sentence: "Every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it." The implicit method was symbolic. If intelligence reduces to manipulating symbols according to rules, and if humans can describe those rules precisely enough, then a machine can in principle do everything a human mind can do.
Three intellectual currents made this seem plausible in 1956. First, mathematical logic had matured to the point where formal proofs were mechanical processes — Gödel, Church, and Turing had shown that what counts as a proof can be checked by a machine. Second, the digital computer made it physically possible to manipulate symbols at scale. Third, cognitive psychology, then ascendant, framed thinking as information processing — the machine analogy was implicit.
If you accept the framing, the path forward was clear: encode the rules of arithmetic, of language, of medicine, of chess, and the machine would inherit each of those competences. The early successes were striking. The Logic Theorist (designed 1955, completed 1956) proved 38 of the first 52 theorems in chapter 2 of Principia Mathematica. The General Problem Solver (Newell, Shaw, Simon — introduced 1957, full description 1959) could in principle solve any well-formed problem its rules could express. By 1965 a chess program had reached amateur strength. The bet looked like it might pay.
3. The three main symbolic techniques
Inside symbolic AI, three flavours of technique account for almost all of the work that has shipped.
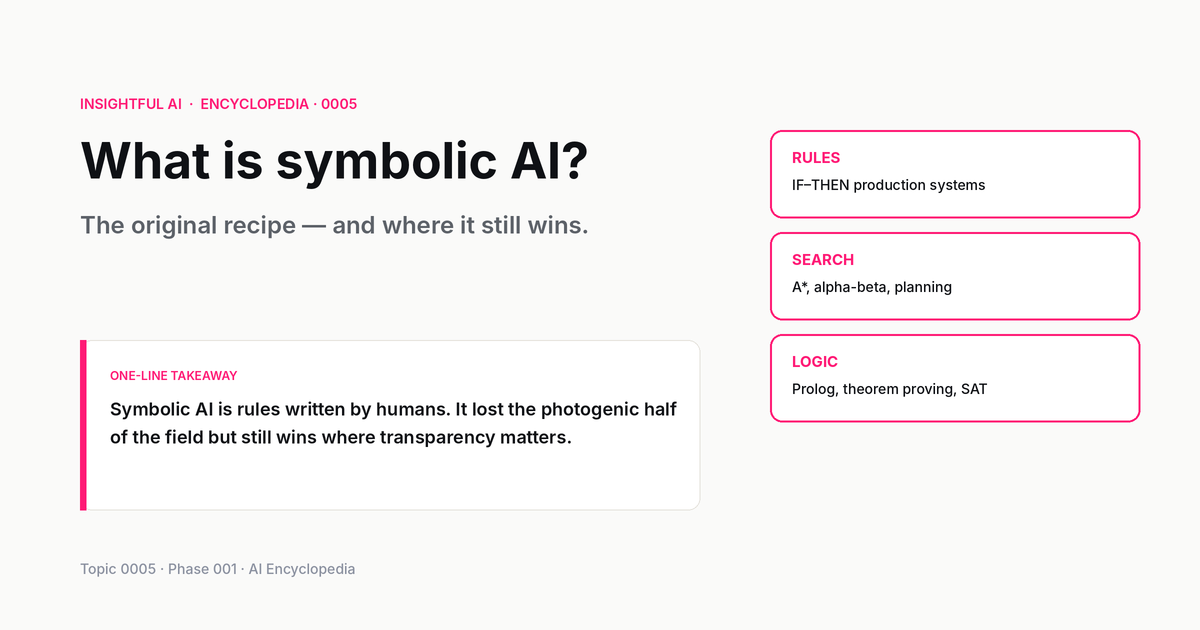
Production systems / rule engines. A production rule has the form IF condition THEN action. A rule engine maintains a database of facts (the "working memory") and a database of rules. On each cycle, the engine finds rules whose conditions are satisfied by the current facts, picks one (often by a hand-coded priority or conflict-resolution policy), and fires it, which adds, removes, or modifies facts. This continues until no rule applies or a goal is reached.
Production systems are the backbone of expert systems — the most prominent symbolic-AI success of the 1970s and 80s. MYCIN (Stanford, 1972–80) diagnosed bacterial infections from roughly 600 rules; a 1979 evaluation found it matched or exceeded Stanford's infectious-disease faculty on ten meningitis cases. XCON (originally built at Carnegie Mellon, deployed at Digital Equipment Corporation from 1980) configured VAX computers from 2,500+ rules and reportedly saved DEC about 25 million USD a year. Hundreds of similar systems shipped in industry.
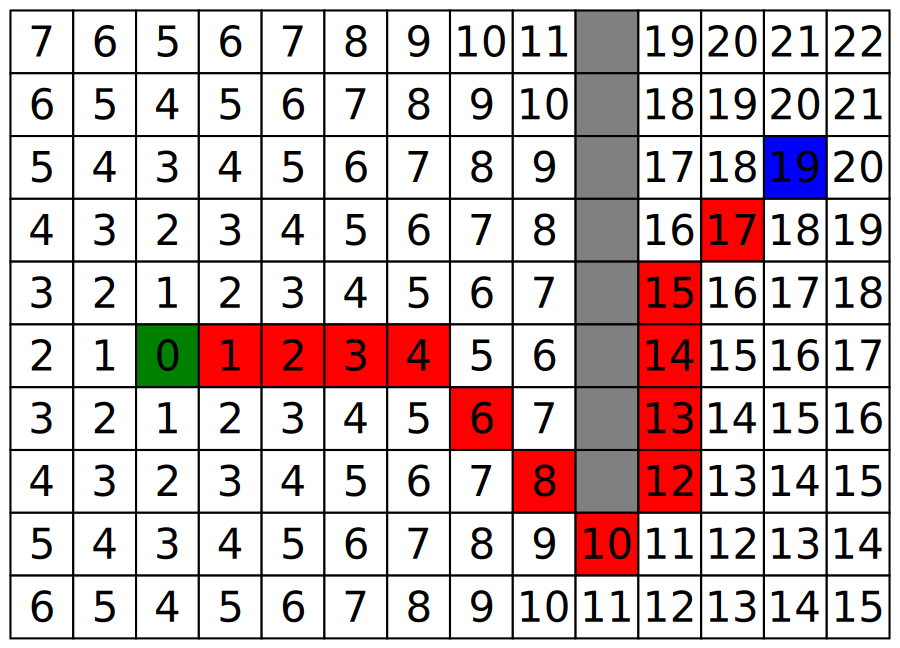
Search. Many problems do not have a closed-form solution but can be solved by intelligently exploring a space of possibilities. Chess, Go, route-finding, theorem proving, planning — all are search problems. The machine examines candidate states, evaluates them, and follows the most promising paths.
The intelligence here is not in the search algorithm itself (the algorithms are simple) but in the heuristic — the function that estimates which states are worth exploring next. A* uses an estimate of remaining cost to a goal; alpha-beta pruning in chess uses a board evaluation that hand-crafted heuristics provided for decades. Stockfish today still does alpha-beta search; only its evaluator has been replaced with a small neural network.
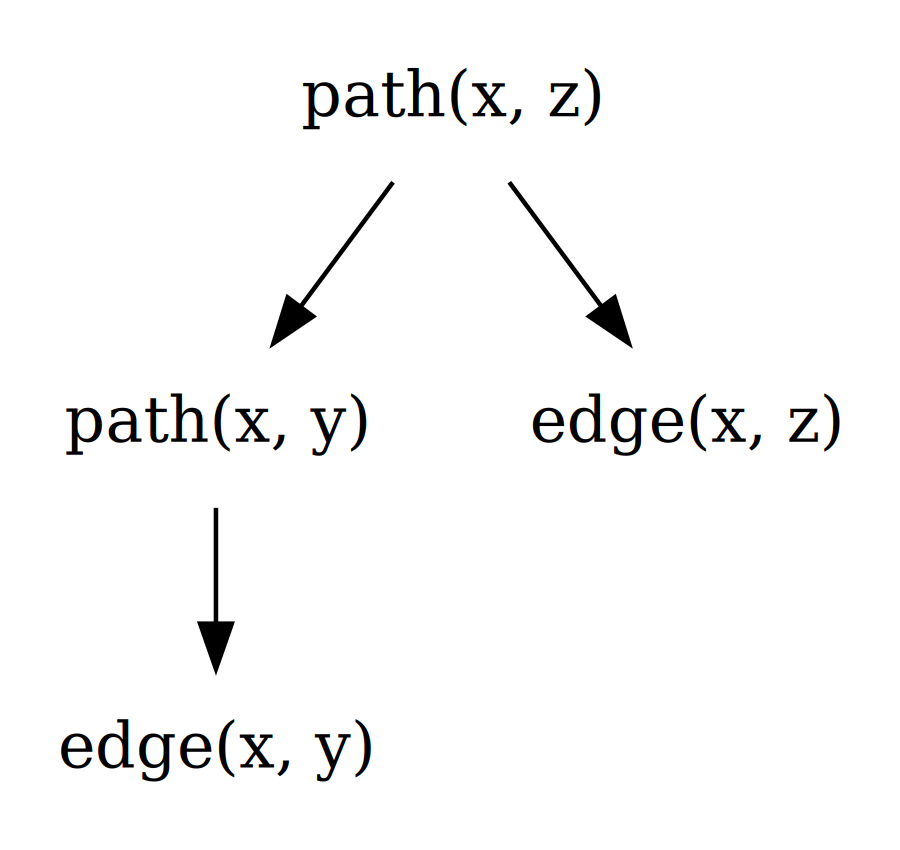
Logic programming. Programs are written as logical relations and rules. The classic example is Prolog (1972). A Prolog program might consist of facts (parent(alice, bob)) and rules (grandparent(X, Z) :- parent(X, Y), parent(Y, Z)). The engine answers queries by searching for ways to satisfy the rules. Logic programming remains in active use for parsing, planning, and rule-heavy domain modelling — though Datalog, a restricted dialect, has had more recent traction than Prolog itself, especially in static analysis and graph queries.
Two more symbolic flavours that deserve a mention. Constraint solvers — SAT, SMT, and integer-linear-programming engines — solve problems by finding variable assignments that satisfy a set of declared constraints. Modern SAT solvers routinely handle problems with millions of variables; they are inside chip-design verification, hardware and software model checking, program synthesis, and certain package managers (Conda's libsolv and openSUSE's zypper use true SAT/SAT-like solvers, while Cargo and NPM use simpler backtracking resolvers). Theorem provers — Coq (recently renamed Rocq), Lean, Isabelle — go further still: they not only check that a logical statement follows from axioms, they construct the proof. Their use in 2026 is concentrated in formal verification of cryptographic protocols, mathematical research, and any safety-critical software where "tested heavily" is not enough and "proved correct" is required.
4. The expert-systems boom and bust
Through the 1970s the technique matured; through the 1980s it commercialised. By 1985 most large companies had at least one expert system in production. There was a thriving ecosystem of shell programs (KEE, ART, ROSIE) that let domain experts encode rules without writing low-level code, and a generation of "knowledge engineers" whose job was extracting tacit expertise from human experts and turning it into rules.
Then it broke. Expert systems were brittle in three ways that compounded.
The knowledge bottleneck. Getting domain experts to articulate every rule turned out to be vastly more expensive than the field had estimated. Experts often did not know the rules they were using; their judgement was tacit, accumulated over years, and could not be fully serialised into IF–THEN form. A typical commercial expert system took 5–10 person-years to build and was obsolete by the time it shipped.
Edge-case brittleness. A rule that covered 80% of cases left 20% uncovered. Adding rules for the 20% interacted badly with existing rules in ways no one could predict in advance. By the time a system had 2,000 rules, no one knew exactly what it did in any given case — the symbolic interpretability that was supposed to be the great virtue of expert systems turned into the opposite at scale.
Maintenance cost. Rules drift as the world changes. A medical-diagnosis system encoded in 1985 was wrong about HIV, MRSA, and a dozen other diseases by 1995. Keeping the rule base current required ongoing expert involvement that companies stopped funding when easier alternatives became available.
By 1990 the commercial expert-systems market had collapsed. The bust contributed to the second AI winter. Symbolic AI did not disappear, but it stopped being the centre of attention.
One concrete illustration of the brittleness problem is worth pausing on. CYC, started in 1984, was the most ambitious symbolic-AI project ever attempted — an effort to manually encode the entirety of human common-sense knowledge as logical assertions. Over four decades, many hundreds of person-years, and well into nine figures of cumulative funding, the project has accumulated roughly 25 million axioms and remains incomplete in any practical sense. CYC is not a failure of intelligence or funding; it is the empirical demonstration that common sense, the thing every five-year-old has, resists rule-based encoding. The implicit knowledge a child uses to figure out that a balloon will float up when released is not 50 rules or 5,000 rules — it is something more like a continuous model of physics that pattern recognition handles better than logical assertion ever did.
5. The bitter lesson — why ML won the photogenic half
In 2019, Rich Sutton wrote The Bitter Lesson, a now-famous essay arguing that across seventy years of AI research, the consistent pattern is that methods that scale with compute beat methods that bake in human knowledge. Chess engines built on hand-coded heuristics were beaten by ones built on search plus learning. Computer vision built on hand-engineered features was beaten by deep learning. Machine translation built on hand-crafted grammars was beaten by statistical methods, then by neural ones.
The pattern repeated everywhere, and the symbolic-AI tradition was the human-knowledge side every time. The deeper reason: human knowledge, however expert, is finite and biased; data is vast and ground-true. A system that learns from billions of examples can pick up regularities no human has the patience to enumerate. As compute became cheap, learning-from-data dominated wherever the data was available.
There is a useful counterfactual worth holding in mind. If the world had less data — or if compute had stayed expensive — symbolic AI would likely still be dominant. The bitter lesson is a statement about the regime we ended up in, not a universal truth about cognition. In domains where data remains scarce (rare-disease diagnosis, novel materials, low-resource languages), symbolic methods continue to outperform learning-based ones, sometimes dramatically. The bet that "more compute and data always wins" holds only as long as both keep arriving.
This is the polite version of why symbolic AI lost the photogenic half of the field after 2012. It is not that symbolic methods are wrong; it is that they top out where the encoded knowledge tops out, and the encoded knowledge is always smaller than the world.
6. Where symbolic AI still wins in 2026
Despite the bitter lesson, symbolic AI is the right tool for several large classes of problem in 2026.
Where rules must be transparent and auditable. Tax law is a rule-based system; tax software is symbolic AI for that reason. The same is true for compliance engines in finance, drug-interaction checkers in pharmacies, eligibility rules in social-benefit systems. Any domain where a regulator can be expected to ask "why did the system decide that?" is a domain where the answer "because the trained weights aligned that way" is not acceptable, and where symbolic rules — explainable line by line — remain the only defensible technology.
Where the rules are short and complete. Many problems have known, finite rule sets. A SAT solver checking whether a CPU design has any race condition does not need to learn anything; the rules of logic are stable. A theorem prover verifying a cryptographic protocol works in this regime. So does a unit-conversion library, a calendar engine, a regex matcher.
Where data is unavailable. When the problem is rare enough that no useful dataset exists — diagnostic systems for very rare diseases, regulatory frameworks newer than any training corpus — handcrafted rules from experts are sometimes the only available approach.
Where the system must compose with other systems. Modern AI deployments routinely mix layers (see AI vs ML vs Deep Learning vs LLMs). A safety filter that calls into a symbolic rule engine to enforce hard constraints on what an LLM-driven agent can do is symbolic AI being used as the trust layer. The neural component handles the open-ended part; the symbolic component handles the part that must not fail.
Inside chess and Go engines. Stockfish still uses alpha-beta tree search; AlphaGo uses Monte Carlo Tree Search. Both are classical search algorithms with learned evaluators on top. The neural network changed which positions look promising; the search algorithm did not change.
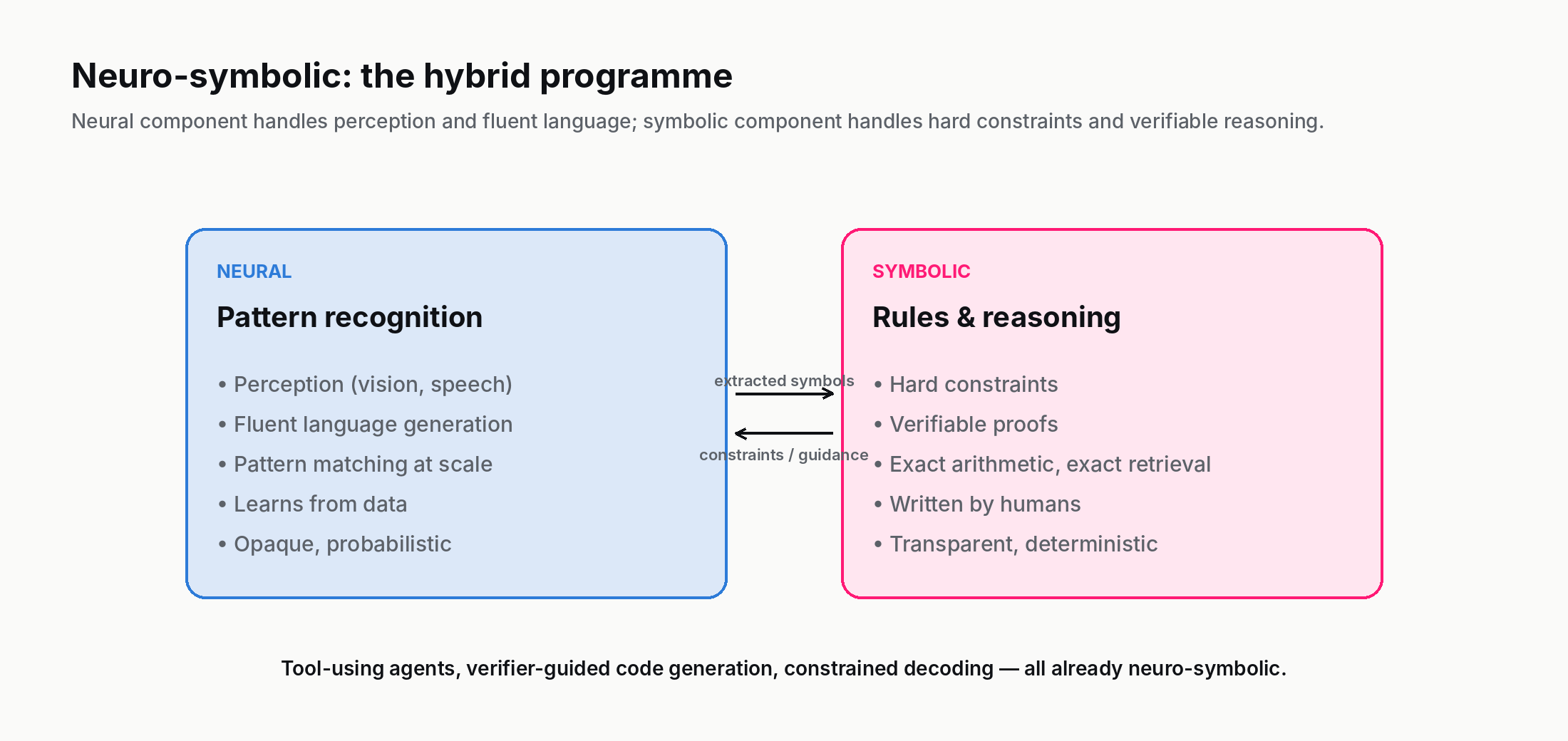
7. The neuro-symbolic renaissance
Since roughly 2020, a research area called neuro-symbolic AI has been growing inside the broader field. The thesis is straightforward: neural networks and symbolic systems have complementary strengths, and the right architecture for many problems mixes both. The neural part handles perception, fuzzy pattern matching, and broad zero-shot competence. The symbolic part handles compositional reasoning, hard constraints, and provable behaviours.
Concrete examples in 2026:
- Tool-using LLM agents. An LLM that calls a calculator, a Python interpreter, or a SQL database for the parts it is unreliable at is a neuro-symbolic hybrid. The LLM does what LLMs do well (language understanding, planning); the tools do what symbolic systems do well (arithmetic, exact retrieval, formal queries).
- Verifier-guided generation. Code-generating LLMs paired with a compiler or test runner that rejects code that does not compile or pass tests. The LLM is neural; the verifier is symbolic.
- Knowledge graphs as LLM grounding. Retrieval-augmented generation against a curated knowledge graph (rather than a free-text vector store) gives the LLM a symbolic backbone of entities and relations.
- Constrained decoding. Restricting an LLM's output to obey a context-free grammar or a JSON schema is a tiny symbolic-AI layer wrapping a neural one.
The mature 2026 view is that neither pure symbolic AI nor pure deep learning is the long-term answer for systems that need to be both general and reliable. The hybrid programme is younger, less photogenic, and more likely to be where the actual frontier work happens over the next decade.
A concrete framing: think of the neural part as the "intuition" of the system and the symbolic part as its "checking work." Humans do something similar — we pattern-match quickly, then verify the answer with deliberate reasoning when stakes are high. The hybrid architectures recreate that split: a fast neural pass produces a candidate, a slower symbolic step verifies or constrains it. In domains where both speed and trustworthiness matter (medicine, law, code generation, scientific reasoning), this is where the most useful 2026 systems are converging.
8. How to tell when a system is symbolic
Given any AI system, six diagnostic questions to locate the symbolic component:
- Were any rules written by a person? Yes → symbolic component present.
- Can you point at a specific rule and trace how an output was produced? Yes → at least partly symbolic.
- Does the system rely on a knowledge base that a domain expert maintains? Yes → symbolic.
- Does the system use a search procedure with a heuristic? The search is symbolic; the heuristic may be learned or hand-crafted.
- Is there a SAT/SMT solver, a theorem prover, a constraint engine, a Prolog/Datalog interpreter, or a regex evaluator anywhere inside? Symbolic.
- Are there hard constraints the system must obey, separately from learned behaviour? Yes → symbolic safety layer.
Most non-trivial production AI systems in 2026 will answer "yes" to at least one of these. The question is rarely "symbolic or learned?" — it is "which parts of this system are symbolic and which parts are learned, and is the boundary in the right place?" A good architect can articulate, for any given system, where each layer's responsibility ends and the next begins, and what would break if a learned component were used where the hard-rule component currently sits, or vice versa.
9. Where to read next
The Make your own expert system lab is the practical companion to this post. Edit rules, see what they catch, watch the system fail on edge cases. Ten minutes there will give you a sharper feel for the strengths and brittleness of symbolic AI than the prose alone provides.
For the conceptual chain: this post built on the four-layer hierarchy in AI vs ML vs Deep Learning vs LLMs (Topic 0004), where symbolic AI was the outer ring. The next posts in Phase 001 cover Statistical AI (the probabilistic-ML side that displaced symbolic AI in the 1990s) and Connectionist AI (the neural-network side that displaced statistical methods after 2012).
If you want the full curriculum, the entry point is the AI Encyclopedia — 130 phases, 2,600 concepts. Symbolic AI is the foundation that Phase 001 spends several topics unpacking, because it is the layer everything else built on top of.
And the one-line takeaway, if you keep one thing: symbolic AI is not obsolete — it is the layer that handles parts of the problem learning cannot, and it is increasingly the trust layer wrapped around modern AI systems.
Further reading: The Dartmouth Summer Research Proposal (McCarthy et al., 1955), The Bitter Lesson (Sutton, 2019), Symbolic AI on Wikipedia.
How we use AI and review our work: About Insightful AI Desk.


