AI vs Machine Learning vs Deep Learning vs LLMs — the actual differences
Four layers everyone conflates — AI, Machine Learning, Deep Learning, and Large Language Models. What defines each, what each can and cannot do, where production systems use them in 2026, and how to tell which layer a system actually is. With a paired lab.

By Kenji Tanaka, Insightful AI Desk
Almost every conversation about AI in 2026 collapses four very different things into one word. Someone says "AI is going to change healthcare," and they might mean a hand-coded rule engine flagging drug-interaction conflicts (which has existed for decades), a statistical model spotting anomalies in radiology scans (recent but settled), a deep neural network predicting protein structures (genuinely new), or an LLM drafting clinical notes (very new and not entirely settled). All four are described in the press as "AI." All four work in fundamentally different ways. All four belong on the page when you are choosing which one is right for a problem.
This post is the layer-by-layer breakdown. Each of the four — AI, Machine Learning, Deep Learning, Large Language Models — sits inside the previous one. We walked through the nested-circle picture briefly in our What is artificial intelligence? explainer; this post is the deep version. For each layer we look at what defines it, what it can do, what it cannot, where production systems use it in 2026, and how to tell when a system is operating at that layer rather than another.
🎯 Companion lab: Same problem, four AI layers — pick a real-world task (spam detection, image classification, customer chat, fraud detection), and see how each of the four layers attacks the same problem differently. The mechanical differences land harder when you can switch between them on the same task.
1. The nested picture, more carefully
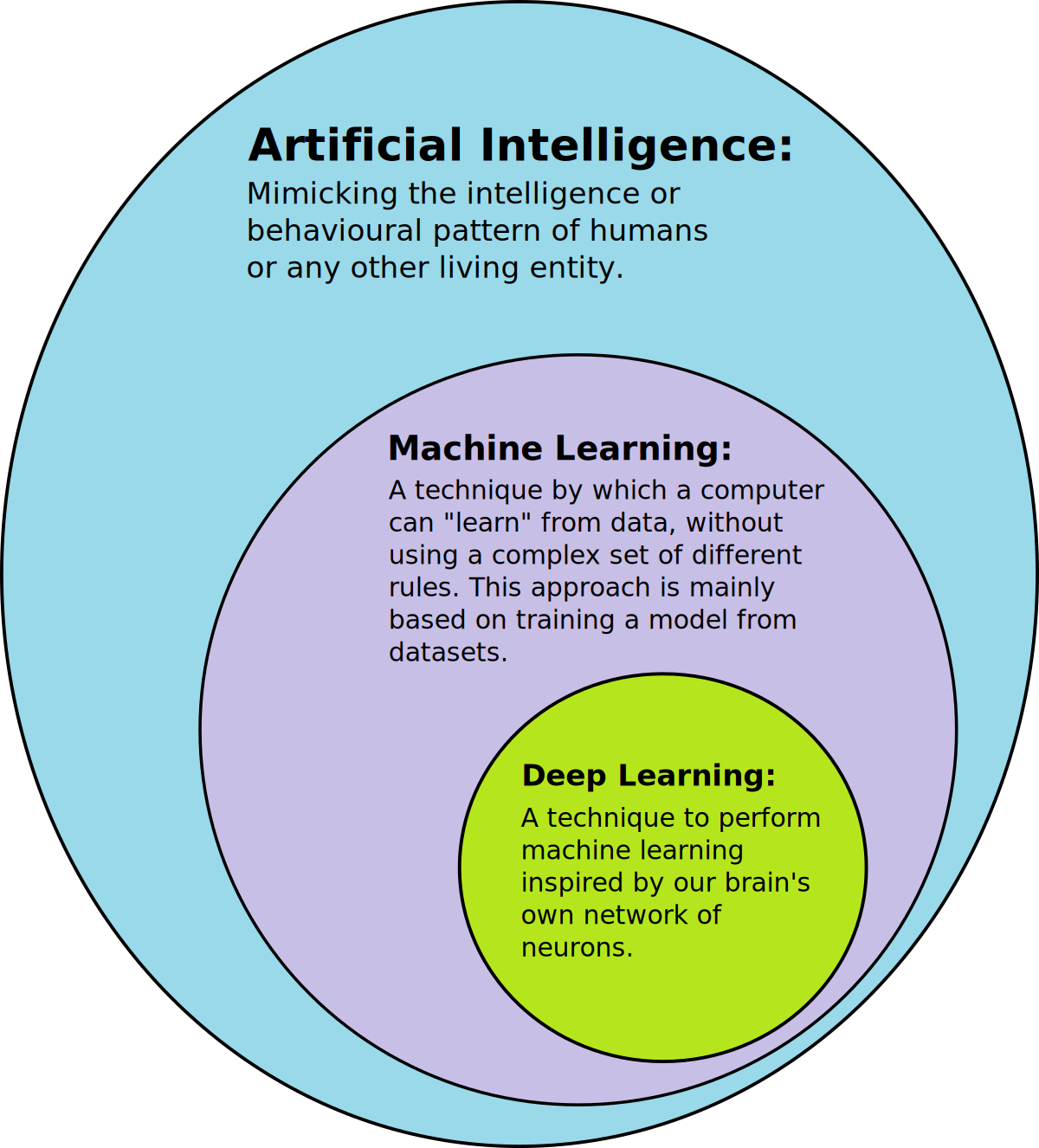
Before the per-layer breakdown, a moment with the picture itself. AI is the outer ring — the field, defined behaviourally, encompassing any computer system performing tasks we would call intelligent if a human did them. Machine Learning is a strict subset of AI: those AI systems whose behaviour was learned from data rather than written by hand. Deep Learning is a strict subset of ML: those ML systems built on multi-layer neural networks. Large Language Models are a particular kind of deep network — specifically, deep transformer networks trained on text — and they are now the most-discussed subset of deep learning by a wide margin.
The subset relation is strict in one direction and not the other. Every LLM is a deep network. Every deep network is ML. Every ML system is AI. But not every AI is ML (some AI systems are hand-coded), not every ML system is deep learning (linear regression, random forests, gradient boosting are all ML but not deep), and not every deep network is an LLM (image classifiers, speech recognisers, AlphaFold are all deep learning but not LLMs).
This matters because the press uses "AI" as shorthand for "the most exciting layer of the moment," which is currently LLMs. In 2018 the shorthand meant deep learning broadly. In 2010 it meant statistical ML. In 1985 it meant expert systems. The word survives, the referent moves. Reading "AI is taking over X" usefully means asking which layer.
2. AI that is not Machine Learning — the often-forgotten layer
The cleanest way to feel the AI / ML boundary is to look at AI systems that are not ML. These are systems whose intelligent behaviour comes from rules a human wrote, or from algorithms that search through possibilities without learning. The category is sometimes called symbolic AI or good old-fashioned AI (GOFAI), and it is much more present in production than the press suggests.
Rule-based expert systems. A medical decision-support tool that encodes "if patient takes warfarin and is prescribed ibuprofen, flag for bleeding risk" is doing AI — it is performing a task that requires intelligence in a doctor — but it is not learning. The rules were written by clinical experts and live in a database. The system applies them. The reasoning is fully inspectable, predictable, and bounded by what the experts wrote down. Hospitals run thousands of these rules every minute in 2026.
Search algorithms. Stockfish, the strongest open-source chess engine, plays at super-grandmaster level. Most of its strength comes from a hand-coded alpha-beta search procedure that explores millions of possible positions per second and evaluates them. Stockfish 12 (released September 2020) introduced a neural-network evaluator (NNUE) alongside the classical hand-tuned evaluator, and Stockfish 16 (mid-2023) removed the classical evaluator entirely — but the alpha-beta search underneath is still classical AI, not learned. The line between "AI" and "ML" runs straight through this engine.
Planning systems. Logistics software that plans the route a delivery van takes through 200 stops is using AI — it is solving a problem that requires careful sequencing — but it is typically an algorithm from operations research, not a learned model. The intelligence is encoded in the algorithm's structure.
Theorem provers, constraint solvers, optimisation engines. A SAT solver checking whether a circuit design has any race condition is doing AI in the original 1956 sense. It does not learn. It searches a logical space with clever heuristics.
The reason this layer matters: when you can solve a problem with hand-coded rules, doing so usually produces a system that is more interpretable, more deterministic, easier to debug, and cheaper to operate than the ML alternative. Modern AI deployments routinely mix all four layers — an LLM might call a rule-based safety filter, which calls a search procedure, which queries a deep-learning embedding store. Treating "AI" as synonymous with "machine learning" misses half the toolbox.
3. Machine Learning that is not Deep Learning — the workhorse layer
Once we move inside the ML ring, most production AI systems in the world still live outside the deep-learning sub-ring. The reason is simple: for many problems, simpler ML methods are accurate enough, train in seconds rather than weeks, run on CPU rather than GPU, and produce models you can explain to a regulator.
Linear and logistic regression. The most-used predictive model in industry, by an enormous margin. A logistic regression with a few dozen features predicts loan default, ad click-through, customer churn, equipment failure, and dozens of other binary outcomes well enough that the simpler model is the right tool. The coefficients are interpretable; you can tell why the model predicted what it did, claim by claim. For most regulated industries (banking, insurance, healthcare), this is not optional — it is the law.
Decision trees and random forests. A random forest trained on 50,000 examples with 30 features will reach near-state-of-the-art accuracy on most tabular classification problems, train in a minute on a laptop, and run inference in microseconds. For credit scoring, fraud detection, predictive maintenance — anywhere the data lives in rows and columns — gradient-boosted trees (XGBoost, LightGBM, CatBoost) are still the default in 2026, and frequently outperform deep learning on the same problem.
Naive Bayes, k-nearest neighbours, support vector machines. Older but still useful for specific problems: spam filtering, text classification with limited data, similarity search.
Clustering (k-means, DBSCAN), dimensionality reduction (PCA, t-SNE, UMAP). Unsupervised ML — finding structure in data without labels. Used everywhere from market segmentation to anomaly detection.
What unites these methods, beyond being ML, is that the models are shallow: typically one or two stages of computation between input and output, with parameter counts in the thousands to low millions. They cannot do what deep networks can do for perception (vision, speech) or for language fluency at LLM scale. They can do almost everything else, and they do it on rounding-error compute compared to deep learning.
A useful heuristic in 2026: if your data fits cleanly into a spreadsheet, try a gradient-boosted tree before reaching for a neural network. The deep-learning solution is more impressive in a slide deck. The boosted-tree solution is usually what ships.
4. Deep Learning that is not an LLM — the perception layer
Inside the deep-learning ring, before we get to LLMs, sits an enormous body of work: deep networks that do not work with language, or do not work as language models, but that depend on the same gradient-descent-plus-multi-layer recipe.
Convolutional Neural Networks (CNNs). The breakthrough family from 2012 onward — AlexNet, VGG, ResNet, EfficientNet — built for image recognition, detection, and segmentation. CNNs power face-unlock on phones, object detection in self-driving stacks, medical-image classification, and a long list of other visual tasks. In 2026 some of this has shifted to vision transformers (a transformer-family network applied to image patches), but the underlying paradigm is the same: deep networks trained end-to-end to extract hierarchical features from images.
Speech and audio models. Deep recurrent networks (LSTMs, GRUs) historically, and transformer-family models now (Whisper, Wav2Vec, AudioLM). Speech-to-text in your phone's dictation, the wake-word detector in your smart speaker, the noise-cancellation in your headphones — all deep networks, none of them LLMs.
AlphaFold and the scientific-discovery family. A custom transformer-family architecture trained on protein-structure data; AlphaFold 3 (2024) extended to broader biomolecular complexes. Deep learning, not an LLM, with capability that has reshaped structural biology in five years.
Recommender systems at scale. Netflix, YouTube, TikTok, Spotify all run deep recommender systems — multi-layer networks that learn user/item embeddings and predict engagement. These typically blend a deep component with simpler statistical ML in production.
Diffusion models. Stable Diffusion, Imagen, DALL-E 2/3 for images; Sora for video; AudioCraft for music. (The original 2021 DALL-E was autoregressive, not diffusion — the family switched with DALL-E 2 in 2022.) Deep generative networks, distinct architecture from LLMs (they iteratively denoise rather than autoregress over tokens), and powering the entire image-and-video generative-AI sector.
The defining property of deep learning is multi-layer feature extraction: each layer of the network transforms the input into a more abstract representation, and the model learns what abstractions to extract by gradient descent through the layers. This is the property that lets a CNN learn "edge, then corner, then eye, then face" without anyone telling it to, and it is what makes deep learning qualitatively different from the shallower ML family even when the same gradient-descent algorithm runs underneath both.
5. Large Language Models — the special case at the centre
LLMs are the innermost ring and the source of most current AI hype. They are deep neural networks of a particular architecture (the transformer, introduced in Vaswani et al. 2017's "Attention Is All You Need"), trained on enormous corpora of text using a self-supervised objective — typically next-token prediction.
The features that distinguish LLMs from other deep networks:
The transformer architecture. Self-attention (covered in detail in our attention explainer) replaces recurrent processing with a mechanism that lets every token "look at" every other token in the input. This turned out to be the right inductive bias for language and, increasingly, for many other modalities.
Pretraining at internet scale. An LLM is trained on a corpus of trillions of tokens drawn from public text. Llama 3 was documented at 15 trillion training tokens; closed-weight frontier models (GPT-4, Claude 3.5 series) are believed to be in the same range, though their numbers are not officially disclosed. Most of the model's apparent capability comes from this pretraining stage, not from any task-specific fine-tuning that comes after.
Self-supervised learning. The training objective is "predict the next token given the previous ones." This is self-supervised because the right answer is always available — it is the next token in the source text — so no human labelling is required for pretraining. (Later stages, called supervised fine-tuning and RLHF, do use human labels, but the bulk of the learning happens before that.)
In-context learning. A trained LLM can adapt its behaviour to new tasks given only examples in its prompt, with no parameter updates. This emergent capability — present in GPT-3 and stronger in every frontier model since — is what separates LLM-based systems from the explicit-retraining cycles of earlier deep learning.
Scale. Frontier LLMs in 2026 have hundreds of billions to single-digit-trillions of parameters. The number of parameters is not the point on its own — what matters is the joint scaling of parameters, training data, and compute — but the capabilities tend to grow predictably with scale in ways that smaller models do not exhibit.
What LLMs can do well: generate fluent text in many languages, summarise long documents, answer questions when the answer is in the training data or the prompt, write code, translate, do basic reasoning when guided with chain-of-thought prompting, use tools when wired up to do so.
What LLMs do not do well: solve novel multi-step reasoning problems that fall outside their training distribution, recover from their own errors without external scaffolding, handle truly long-horizon agentic tasks autonomously, give reliable confidence estimates, respect numerical accuracy without external tools.

6. The capability ladder — what each layer adds
Walking from the outside in, each layer adds capability that the layers outside cannot deliver, and pays for it in cost, data, and complexity.
AI (rule-based) gives you: reliable, interpretable, deterministic behaviour for problems that can be specified by experts. Cost: low. Data needed: none. Limitation: only as good as the rules; brittle outside them.
ML adds: the ability to generalise to cases the rules-writer did not anticipate, provided you have labelled examples that cover the relevant distribution. Cost: moderate. Data needed: thousands of examples. Limitation: largely tabular; cannot do perception or fluent language.
Deep Learning adds: perception (vision, speech, audio) and complex pattern recognition that shallow ML cannot perform well. Cost: high (GPUs, larger datasets). Data needed: tens of thousands to millions of examples. Limitation: opacity (you cannot easily explain why the model produced a specific output), data hunger, energy.
LLMs add: fluent natural-language behaviour, in-context learning across many tasks without retraining, broad zero-shot competence on tasks adjacent to training data. Cost: very high to train, moderate per query. Data needed: internet-scale pretraining corpus, much less for fine-tuning. Limitation: hallucination, brittle reasoning outside training distribution, expensive inference, regulatory grey areas.
Choosing a layer is choosing a point on this trade-off curve. The systems that ship in production are usually the ones where the outermost adequate layer was used — rule-based when rules work, ML when data was available and rules were not, deep learning when perception was needed, LLMs when fluent language was the requirement. Outermost adequate is the operative phrase: every step inward buys you capability at real cost, and the cost is often not visible from a demo.
7. How to tell which layer a system is — a diagnostic checklist
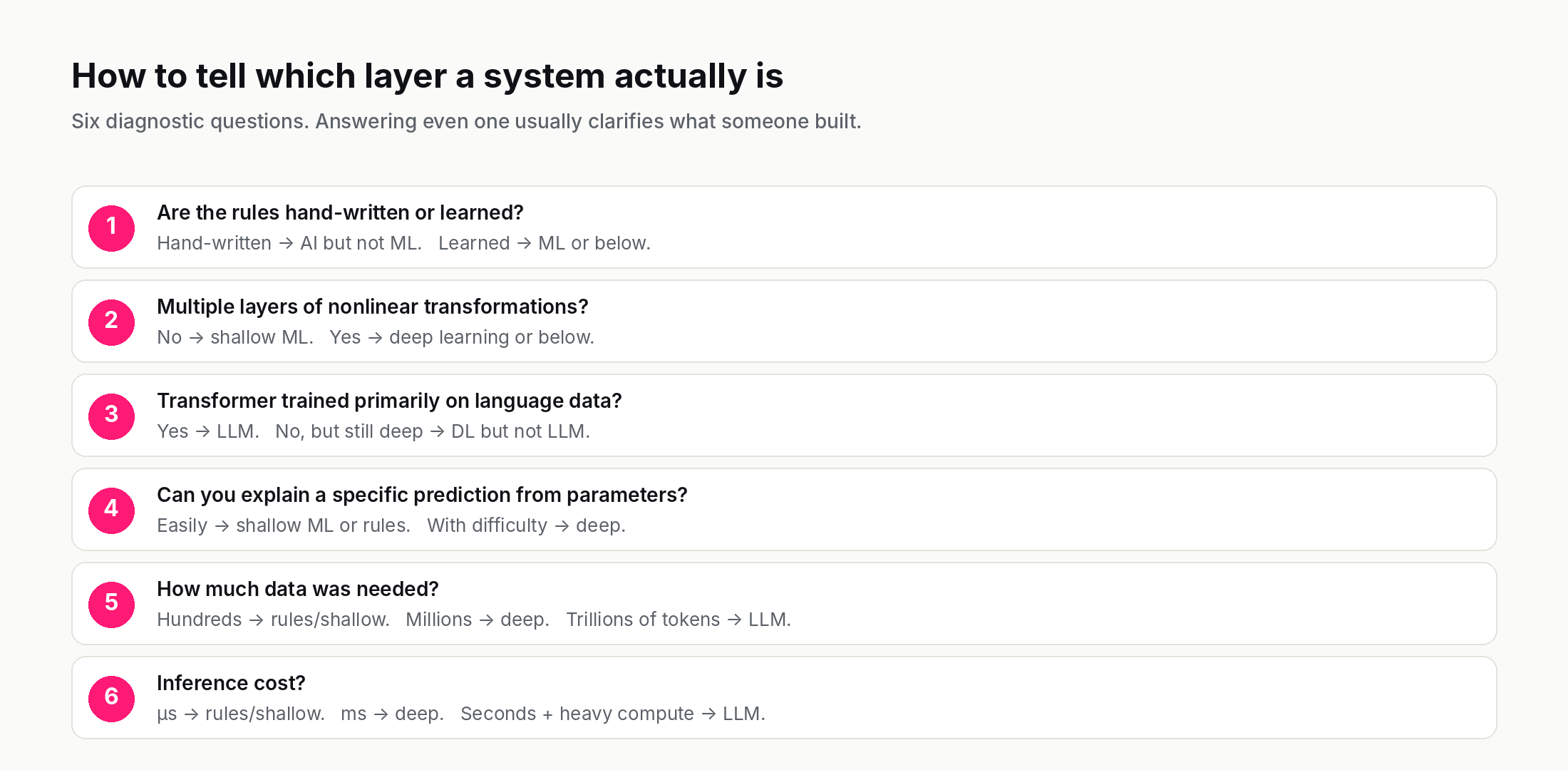
Given a system someone describes as "AI," six diagnostic questions to locate it on the four-layer picture:
- Were the rules written by hand, or learned from data? Hand-written → AI but not ML. Learned → ML or below.
- Does the model have multiple layers of nonlinear transformations? No → shallow ML. Yes → deep learning or below.
- Is the model a neural network of the transformer architecture, trained primarily on language data? Yes → LLM. No, but still deep → deep learning, not an LLM.
- Can you explain a specific prediction in terms of the model's parameters? Easily → likely shallow ML or rule-based. With difficulty → likely deep learning.
- How much data was needed to train it? Hundreds → likely rule-based or shallow ML. Millions to billions → likely deep. Trillions of tokens of text → likely LLM.
- What does it cost to run a single inference? Microseconds → rule-based or shallow ML. Milliseconds → likely deep learning. Seconds with high compute → likely LLM.
The questions are not perfectly orthogonal — many real systems mix layers — but they will correctly place the dominant component of most systems in seconds. When someone says "we are using AI to do X," asking even one of these questions usually clarifies what they actually built.
8. Where the four layers blur in 2026
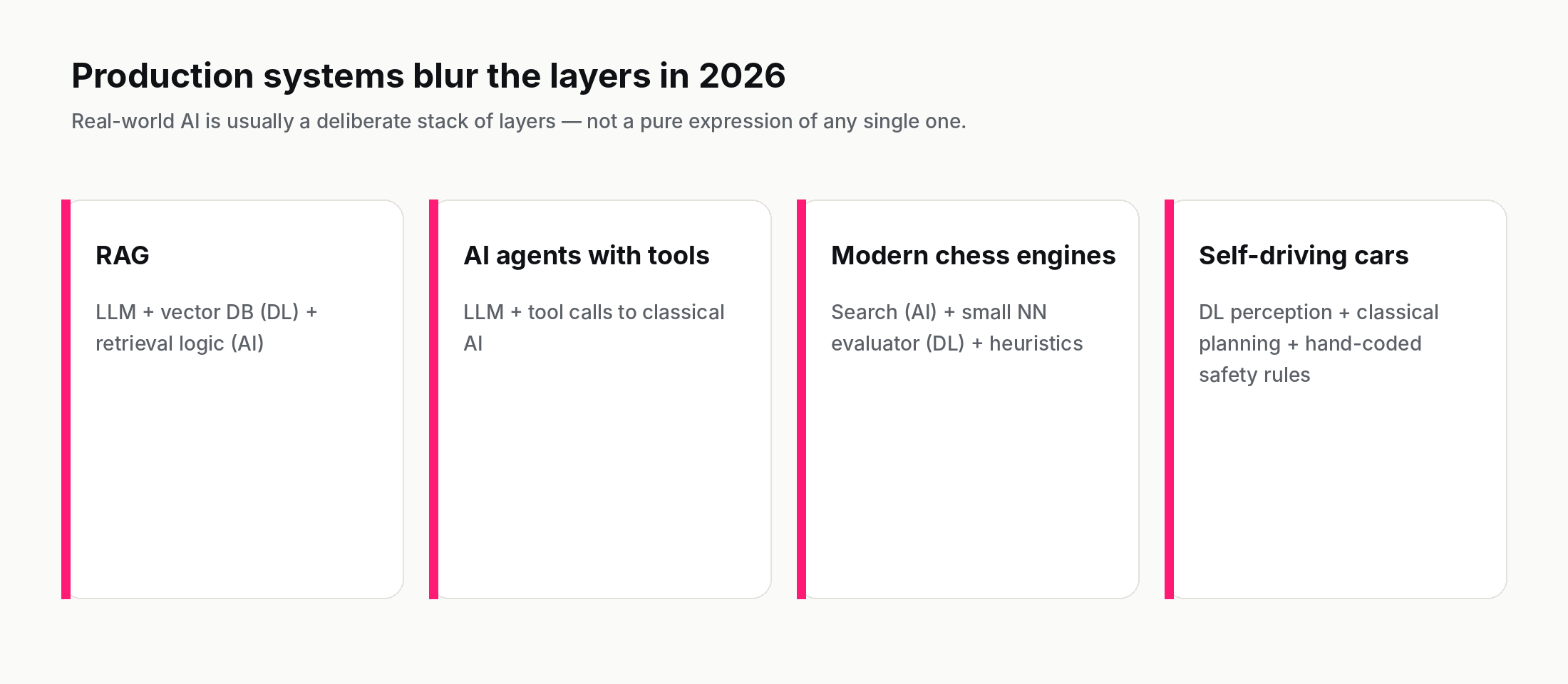
The clean nested picture is a useful starting point and a partial fiction. In production AI in 2026, the four layers routinely combine in ways that resist clean classification.
Retrieval-augmented generation (RAG). An LLM that retrieves relevant documents from a vector database and answers based on them. The LLM is deep learning. The vector database is built with deep-learning embeddings. The retrieval logic is often hand-coded (classical AI). The final system is all four layers stacked.
AI agents with tools. An agent that uses an LLM as its reasoning engine but calls external tools (calculators, search engines, code interpreters, custom APIs) is mixing LLM capability with classical AI for the parts the LLM is bad at. The agent is reliable because of the classical components; it is general because of the LLM.
Chess engines. Stockfish now uses a small neural network (NNUE) for position evaluation, alpha-beta search for move generation, and hand-tuned heuristics throughout. A single binary, three of the four layers.
Self-driving stacks. Deep learning for perception (CNN-based image segmentation), classical AI for planning (search over future trajectories), hand-coded rules for safety constraints, sometimes an LLM for natural-language interaction with the human passenger. All four layers in one moving vehicle.
The 2026 production reality: the four-layer picture is the right starting point for understanding any system, but the systems that work are usually deliberately layered, not pure expressions of any single layer.
9. Where to read next
The Same problem, four AI layers lab is the companion to this post — pick a real-world problem and see how each layer attacks it. Spend five minutes there for a much stronger intuition than the prose alone provides.
This post sits in a chain. Topic 0001 — What is artificial intelligence? — set up the broad behavioural definition. Topic 0002 — What is intelligence? — examined what "intelligence" itself means. Topic 0003 — Human vs machine intelligence — compared the two. This post zooms in on the machine side, naming the four sub-categories the press conflates.
If you want to follow the chain forward, the next posts in Phase 001 cover Symbolic AI, Statistical AI, and Connectionist AI — the three historical paradigms that produced these layers in the first place.
If you want the full curriculum, the entry point is the AI Encyclopedia — 130 phases, 2,600 concepts.
And the one-line takeaway, if you keep one thing: "AI" in any sentence usually refers to a specific layer; ask which one, and the rest of the conversation gets sharper.
Further reading: Attention Is All You Need (Vaswani et al., 2017), Deep Learning (Goodfellow, Bengio, Courville), Hands-On Machine Learning with Scikit-Learn (Géron).
How we use AI and review our work: About Insightful AI Desk.