What is artificial intelligence? A complete intuitive guide
A complete intuitive guide to what artificial intelligence actually is — the nested AI/ML/DL/LLM hierarchy, the one idea that drives modern AI, narrow vs general vs super, five myths the news still gets wrong, and a 60-second tour from 1956 to 2026. With an interactive lab.

By Kenji Tanaka, Insightful AI Desk
Open your phone right now. The keyboard predicting your next word is artificial intelligence. The face-unlock that just let you in is AI. The email that landed in spam, the photo grouped with other photos of your dog, the route your maps app picked, the song the streaming service queued next — every one of these is a piece of artificial intelligence quietly doing its job. We carry dozens of AI systems in a single pocket and almost never call them by that name.
And yet, when someone asks "so what actually is AI?", even people who use it all day struggle to answer in a way that doesn't dissolve into either marketing slogans or a confused mention of robots from movies. This post fixes that. We will define AI in a way that holds up, look at how today's AI actually learns, separate the four nested ideas everyone confuses (AI / ML / Deep Learning / LLMs), debunk the most common myths, and finish with a 60-second tour of how we got from 1956 to 2026.
🎯 Companion lab: when you reach the section on how AI learns from examples, jump into Teach a Tiny AI — drop coloured dots on a canvas, hit Train, and watch a real classifier learn the boundary between them in real time.
1. The question this post answers
The honest short answer is that artificial intelligence is the field of building computer systems that perform tasks we'd normally describe as requiring intelligence when a human does them — recognising faces, understanding language, planning a route, deciding what to recommend, generating an image from a description, beating a chess grandmaster.
That definition is intentionally about behaviour, not about how the machine works inside. It comes from the founding moment of the field. In the summer of 1956, a fluid group of mathematicians and engineers — the proposal had called for a two-month, ten-person study, though actual attendance over the period included around twenty people with only a handful staying the full session — gathered at Dartmouth College. The proposal had been written the previous summer by John McCarthy together with Marvin Minsky, Nathaniel Rochester, and Claude Shannon. It is the document in which the term "artificial intelligence" first appears, and one of its early sentences makes the founding claim: "Every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it." Seventy years later, that behavioural framing is still the most useful definition we have, because it survives every wave of new technique — symbolic programming in the 1960s, expert systems in the 1980s, statistical learning in the 1990s, deep learning after 2012, large language models from 2018 onward. The underlying machinery has changed beyond recognition. The thing being attempted has not.
Let's unpack what that one-line definition really commits us to, what it deliberately leaves out, and where students typically go wrong when they translate it back into examples.

2. The thing itself: five examples before any theory
Before defining a single new term, look at five concrete pieces of AI you've probably used today.
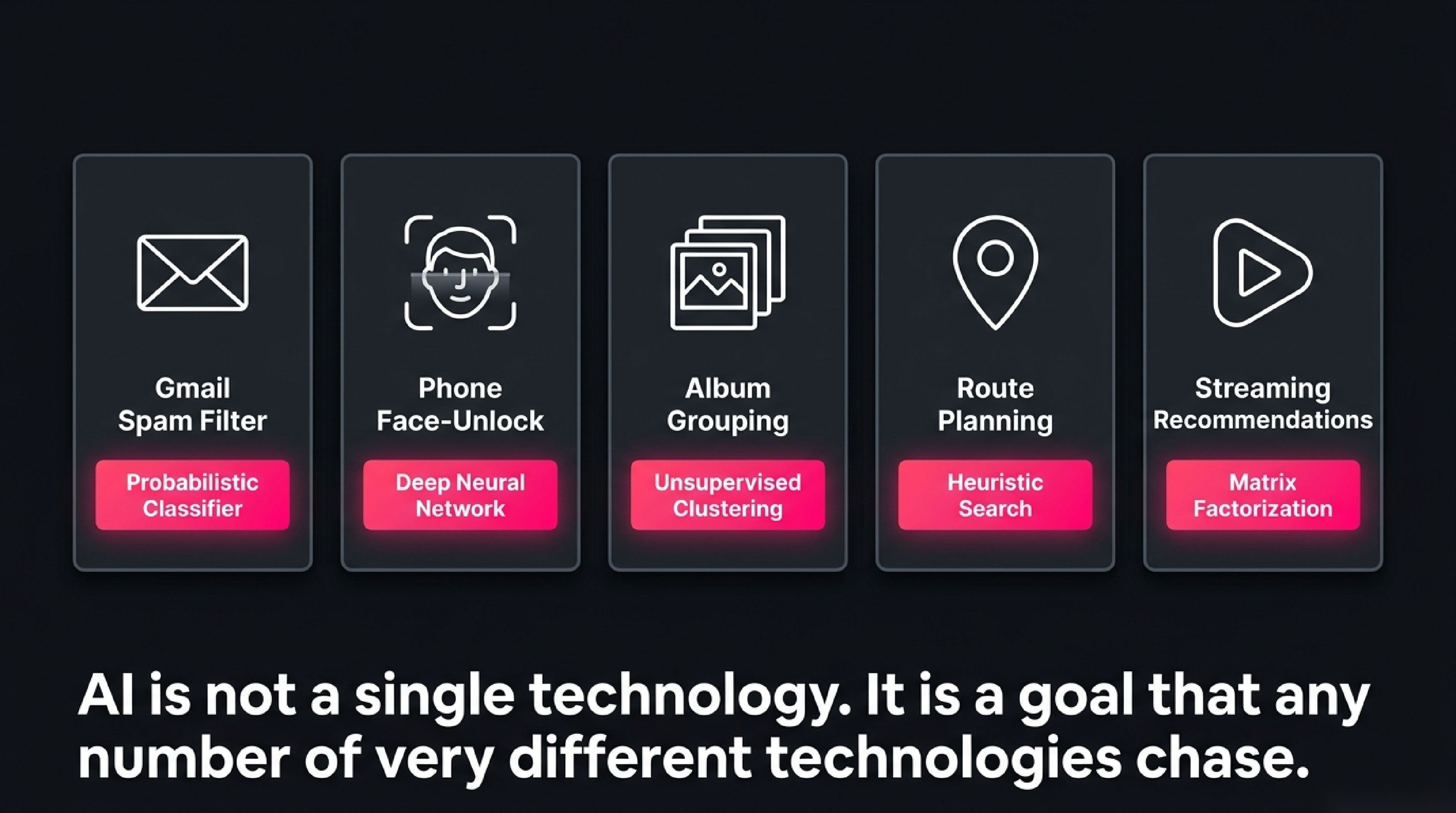
Gmail spam filter. When an email arrives, a model scores it against a learned pattern of what spam looks like — certain words, certain senders, certain link shapes, certain ratios of caps. If the score crosses a threshold, the message goes to the spam folder. The model gets better because every time you mark a message as spam (or rescue one from the spam folder), that becomes a new training example.
Phone face-unlock. When you set up the phone, it captured a few hundred reference images of your face from different angles. Now, every unlock attempt produces an image, and a small neural network computes how close that new image is to your reference. If it's close enough, you're in. The same shape of system runs on the chip in the phone in under a hundred milliseconds, drawing almost no power.
Photo album grouping. Open Photos and look at the People tab. The phone has examined every photo, computed an embedding (a numerical fingerprint) of each face it found, and clustered together the fingerprints that look similar. That's why a person you've never tagged still has their own group. No human labelled anything; the model discovered the clusters on its own.
Maps routing. When you ask for directions, the app doesn't try every possible route — there are billions for a long trip. A search algorithm called A* (read: "A-star") explores routes intelligently, prioritising the ones that look like they're heading toward your destination. The "intelligence" here is the heuristic that tells A* which directions look more promising. AI is not always a learning system; sometimes it's just a smart search.
Streaming recommendations. Netflix knows about 250 million subscribers and millions of titles. It can't directly compare you to all of them. So a model produces a small numerical vector — a "taste profile" — for each user and each title, and recommendations come from finding titles whose vectors lie close to yours. The vectors are learned from the history of who-watched-what, which means the system improves automatically as new viewing data comes in.
Notice what's different across these five. The spam filter is a probabilistic classifier. Face-unlock is a deep neural network. Photo grouping is unsupervised clustering. Maps is heuristic search. Recommendations is a collaborative-filtering matrix factorisation, often dressed up as a neural network. Five fundamentally different techniques, no central "intelligence module" shared between them. And yet we comfortably call all five AI. That tells you something important: AI is not a single technology. It is a goal — making computers do the kinds of things we associate with thought — that any number of very different technologies can chase.
3. The four words people confuse: AI vs ML vs Deep Learning vs LLMs
Here is where almost every newcomer gets lost. The press uses these four words interchangeably; they are not interchangeable. They sit inside each other like Russian dolls.
Artificial Intelligence is the outermost ring — the whole field, including everything from rule-based chess programs to modern multimodal models. It is the original 1956 framing: any system that performs tasks we'd call intelligent.
Machine Learning is a subset of AI. The defining feature: rather than a programmer writing rules ("if word contains 'viagra' then flag as spam"), the system learns the rules from data. You provide examples — emails labelled spam/not-spam — and a learning algorithm produces a model that captures the pattern. Crucially, the model can later be applied to emails the programmer never anticipated. Not all AI is ML — chess engines from the 1990s were not — but most modern AI is.
Deep Learning is a subset of ML. It uses a specific kind of model called an artificial neural network, organised in many layers (hence "deep"), with the layers transforming the input through a cascade of learned numerical operations. The breakthrough year was 2012, when a deep neural network called AlexNet won the ImageNet image-recognition contest by a margin so large that the rest of the field abandoned its old approaches within two years.
Large Language Models are a subset of deep learning. They are specifically deep neural networks of a particular architecture (the transformer, introduced in 2017) trained on enormous quantities of text to predict the next word. GPT-4, Claude, Gemini, Llama — all LLMs. All deep learning. All machine learning. All AI.
If you remember nothing else from this section: every LLM is deep learning, every piece of deep learning is machine learning, every piece of machine learning is AI — but the reverse is not true. A medieval-style hand-coded chess engine is AI but not ML. A spam filter built on linear regression is AI and ML but not deep learning. A photo-classifier convolutional network is AI, ML, and deep learning, but not an LLM.
Calling ChatGPT "an AI" is correct but very imprecise — like calling a smartphone "a tool." The more precise statement is "ChatGPT is an LLM, which is a deep neural network of the transformer family, which is a kind of machine learning, which falls under the broader field of AI." Choose the level of precision the conversation requires.

4. The three flavours of AI under the hood
If you crack open the field of AI and look at how the systems actually work, you find three quite different philosophies. Real systems usually combine them, but each one is worth understanding on its own.

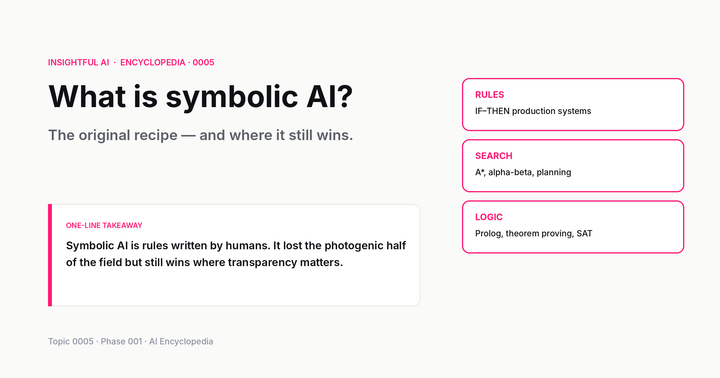
Symbolic AI (also called rule-based or "good old-fashioned" AI). The programmer explicitly writes the knowledge. An expert system for medical diagnosis might contain ten thousand rules of the form "if patient has fever AND cough for more than three days AND no history of asthma, then suspect viral pneumonia." The reasoning is interpretable line by line and the system fails predictably when the input falls outside its rules. Symbolic AI dominated the field from the 1950s through the late 1980s. Today it survives in places where rules must be transparent — tax software, certain legal-compliance tools, theorem provers, parts of every chess and Go engine that aren't the neural network.
Statistical AI. The system models the world as probabilities, often without any deep neural network at all. A spam filter trained with naïve Bayes asks "given the words in this email, what's the probability it's spam, based on how often each word appeared in past spam?" A recommendation engine using matrix factorisation asks "what's the most likely rating this user would give this movie, given the pattern of ratings across all users?" Statistical AI is what powered most production ML systems from roughly 1995 through 2012 and still runs huge swathes of the internet today — search ranking, ad auctions, fraud detection — because for many tasks the simpler statistical model is good enough and cheaper to operate.
Connectionist AI. The system is a neural network — many simple numerical "neurons" connected by weighted links, with the weights adjusted during training. Connectionism was the underdog approach for forty years, dismissed because the math seemed limited and the compute wasn't there. After 2012 it became the dominant paradigm. Modern deep learning, LLMs, image generators, speech recognition, protein-structure prediction — all connectionist. The reasoning is opaque (you cannot easily explain why a 70-billion-parameter LLM produced a specific output), but the performance, for tasks involving perception or language, is unmatched.
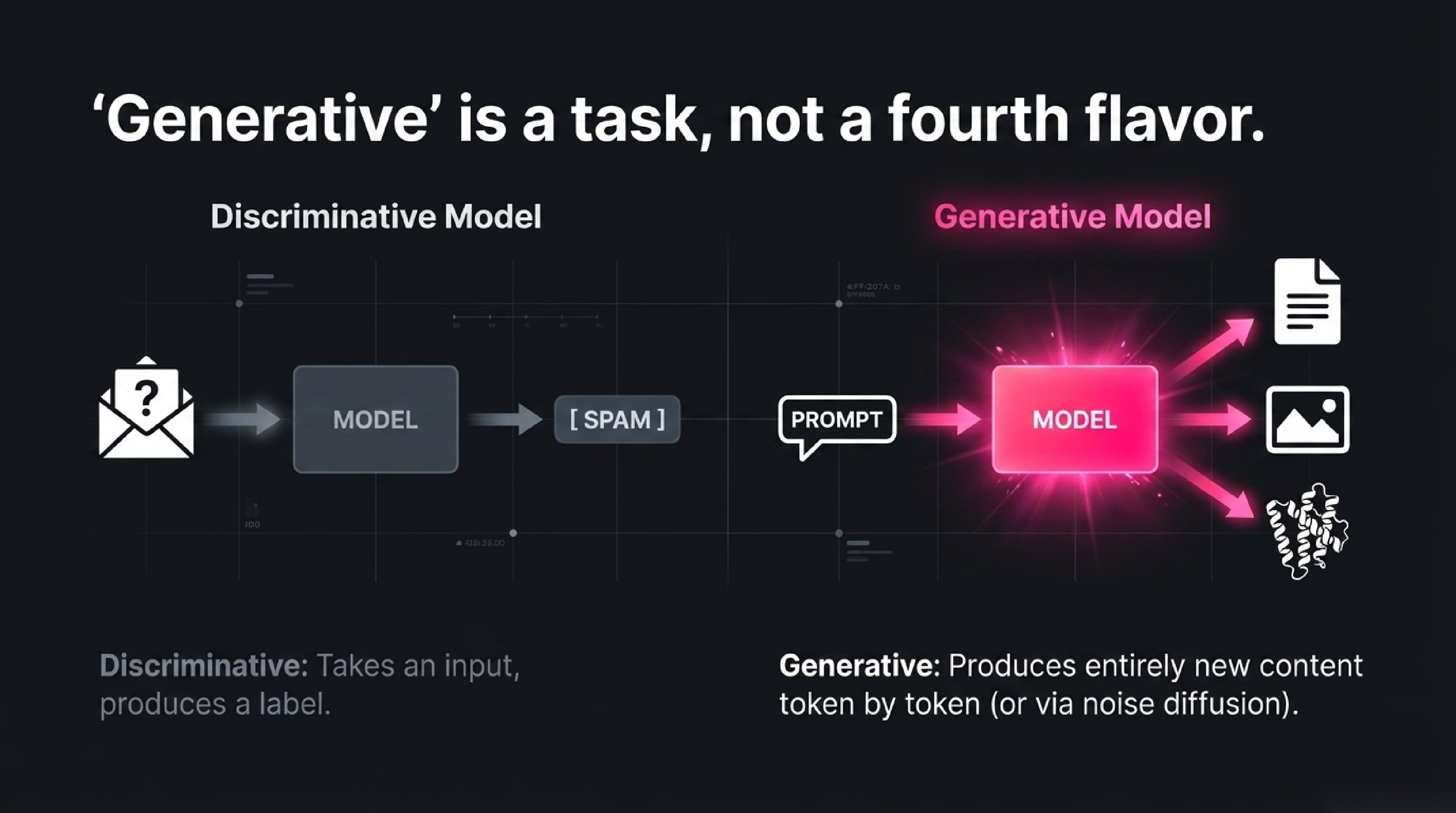
One more useful term, generative AI, is not a fourth flavour but a description of what a system does. A generative system produces new content — text, images, audio, video, code, molecules. Most generative AI in 2026 is connectionist: GPT and Claude generate text token by token; Stable Diffusion generates images from noise; AlphaFold generates protein structures from amino-acid sequences. "Generative" is the opposite of "discriminative" — a discriminative model takes input and produces a label (this email is spam), a generative model produces new content (write me an email).
5. How modern AI actually learns: the one idea that drives everything
Here is the moment when AI stops being mysterious. Modern machine learning, including all the deep learning behind every large language model, runs on one mechanical idea repeated billions of times.
Imagine teaching a child the difference between a dog and a cat. You don't write down rules ("dogs have floppy ears, cats have pointed ears" — counterexamples ruin you in five seconds). Instead, you point at things. "Dog. Dog. Cat. Dog. Cat. Cat." After a few hundred examples the child gets it, and they can classify a breed of dog you never showed them.
That is exactly how modern AI learns. The system starts with a model whose internal numbers (called parameters or weights) are random. You show it an example — a photo — together with the correct label ("dog"). The model makes a prediction with its current weights. Almost certainly the prediction is wrong, because the weights are random. Now you compute how wrong (the "loss"), and you nudge the weights in the direction that would have made the prediction less wrong. Just slightly — by an amount controlled by the learning rate.
Repeat. Millions of times.
That nudging procedure has a name — gradient descent — and it is mathematically the same operation whether you're training a spam filter with 1,000 weights or a frontier LLM with a trillion. After enough examples, the random initial weights settle into a configuration that captures the pattern across the entire training set, and the model can correctly classify (or generate, or translate) inputs it has never seen.
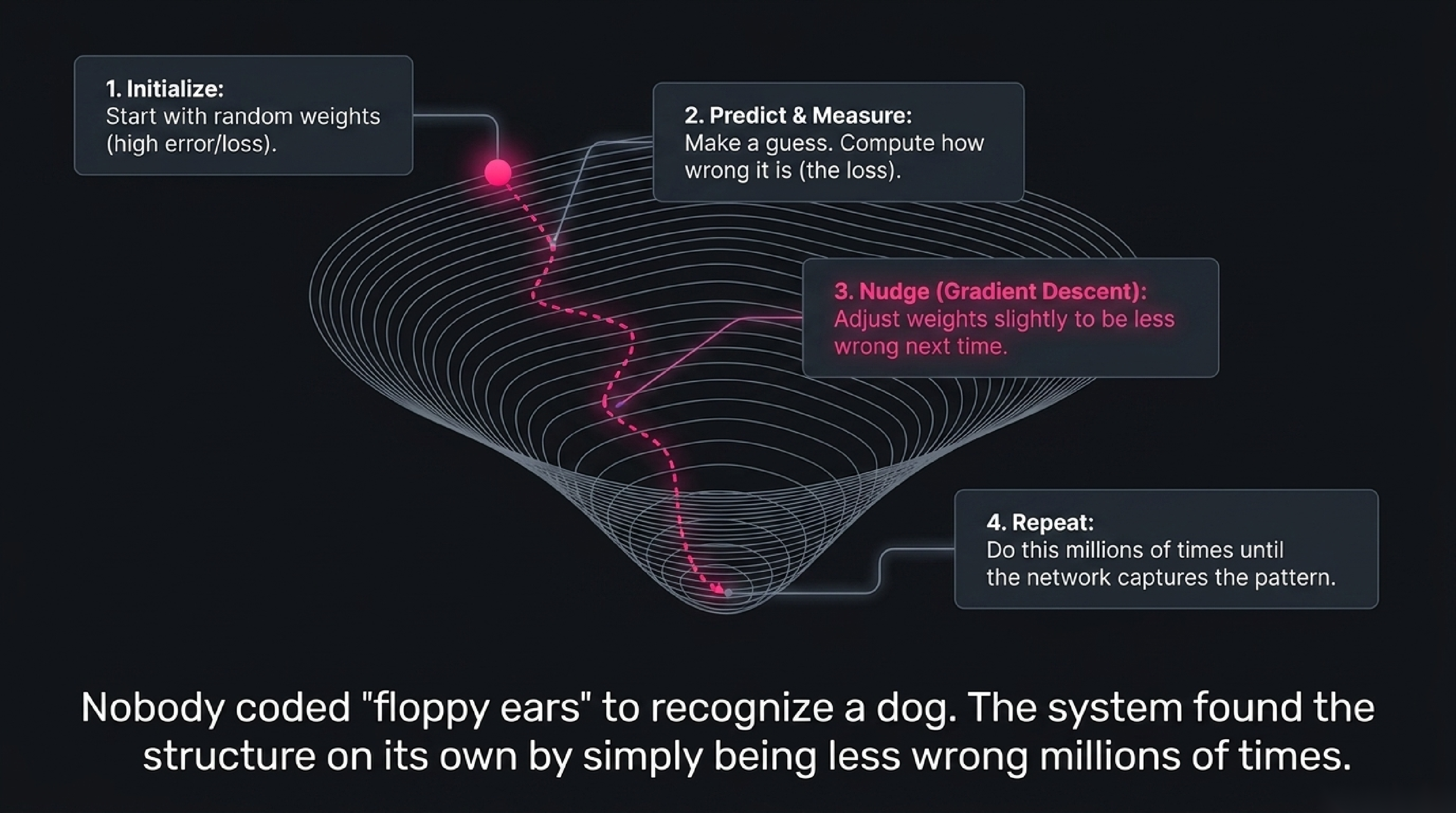
This is the most important idea in modern AI. It is also, philosophically, the most counterintuitive. The model is not told what makes a dog a dog. The model is given examples and a way of being slightly less wrong each time, and over millions of corrections a useful structure emerges in the weights. Nobody coded "floppy ears" into the system. The system found something equivalent on its own — possibly representing it in a way no human would design.
Different problems give the model different kinds of corrections:
- Supervised learning. Examples are paired with correct labels. The loss is "how different is my answer from the label."
- Unsupervised learning. No labels — the model has to discover structure on its own (clusters in the photo album, topics in a set of news articles).
- Reinforcement learning. No labels, but a reward signal. The model takes actions and learns which sequences of actions produced more reward.
- Self-supervised learning. No human labels, but the labels come for free from the data itself. "Predict the next word" is self-supervised: the right answer is right there in the next position of the same text. This is how LLMs are pretrained.
Every one of these is gradient descent under the hood. The only thing that changes is where the correction signal comes from.

▶ Try it yourself — train a tiny AI in 30 seconds
The companion lab strips this down to its absolute minimum: a classifier with two weights, learning to separate red dots from blue dots on a 2D canvas. Click to drop training examples. Click Train and watch the decision boundary rotate as the weights update. Drag the learning rate to break the model with a value that's too high. Add an imbalanced dataset and watch the boundary drift toward the majority class. Forty-five seconds in the lab will give you a stronger gut feel for how modern AI actually learns than a chapter of any textbook.
6. Narrow AI vs General AI vs Superintelligence: where we are, where we're not
One of the most consequential distinctions in the field, and one of the most abused in the press, is the difference between narrow, general, and super AI.
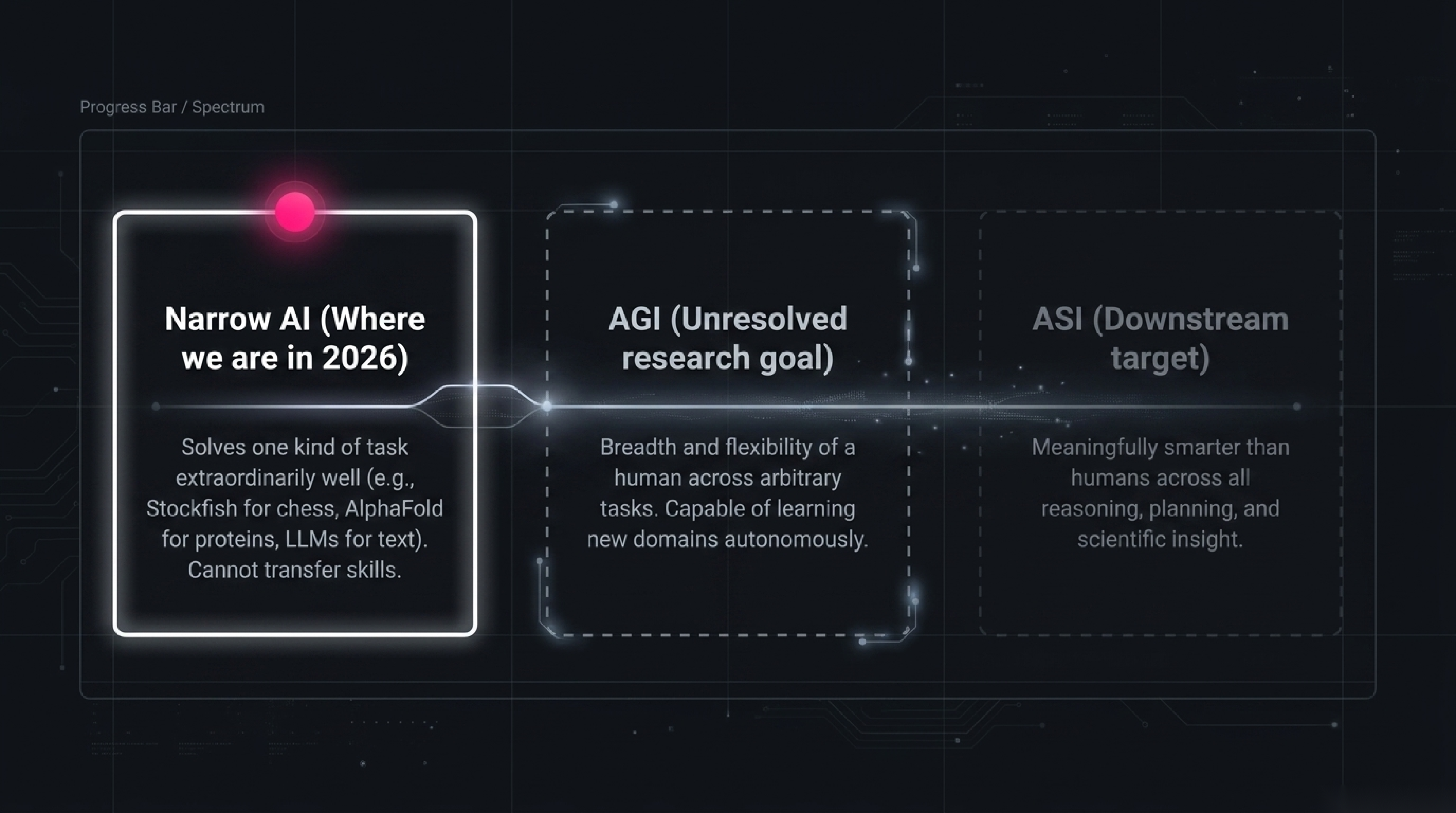
Narrow AI (sometimes Weak AI) is what we have. It is AI that does one kind of task — possibly extraordinarily well — but cannot transfer that capability to fundamentally different tasks without being retrained or redesigned. Stockfish plays chess at superhuman level and would lose to a beginner at Go. AlphaFold predicts protein structures at superhuman level and cannot drive a car. GPT-4 writes essays and code at near-expert level and is bad at three-dimensional reasoning about physical objects. Every single AI deployed in production in 2026 is narrow AI. That is not a complaint — narrow AI is enormously useful and only getting more so — it is a precise description of capability.
Artificial General Intelligence (AGI) is hypothetical AI with the breadth and flexibility of a human across arbitrary tasks. An AGI would not be "an LLM but better." It would be a system that, dropped into a new domain it has never seen — say, running a small bakery in a town it has never visited — would figure out what to do, learn the local quirks, recover from surprises, and operate at human-equivalent competence. AGI does not exist. Whether and when it will is the subject of vigorous debate; estimates from credible researchers in 2026 span "within a decade" to "this century" to "possibly never as defined." Anyone who tells you the answer with certainty is selling you something. (We have a separate post on the AGI definition problem itself.)
Artificial Superintelligence (ASI) is AI that is meaningfully smarter than humans across the board. Faster reasoning, broader knowledge integration, novel scientific insight, strategic planning. ASI is hypothetical, downstream of AGI, and the source of most of the existential-risk concerns you see in the news. Whether ASI is achievable, whether AGI naturally leads to it, and how to ensure such a system is aligned with human values are some of the most important open questions in the field. They are also, today, philosophical rather than engineering questions — we are not close enough to be doing concrete ASI engineering.
The narrow / general / super distinction matters because misreading where a given system sits leads to two opposite mistakes. The first: underrating narrow AI's near-term impact, dismissing it because "it's just pattern matching, not real intelligence." (Tell that to the radiologist whose model now reads scans more accurately than they do.) The second: overrating narrow AI's general capability, projecting from a domain it dominates (LLMs write fluently) to capabilities it doesn't have (LLMs reason about complex multi-step physical situations with extreme unreliability). The mature view: today's AI is a remarkable set of narrow tools; AGI is a distinct, unresolved research goal; ASI is downstream of both.
7. Five myths the news still gets wrong
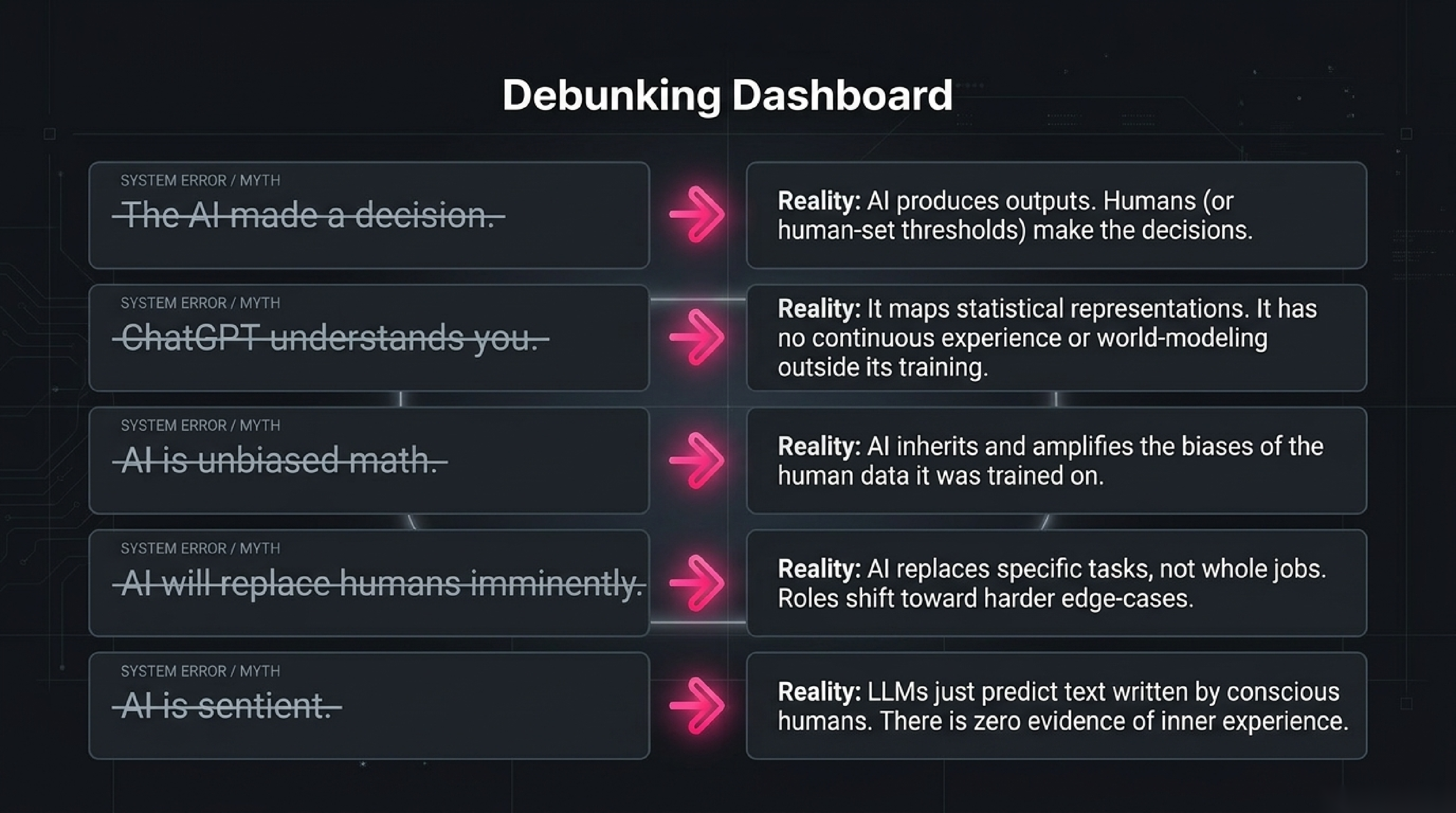
Myth 1: "The AI made a decision." Almost never true in the way it sounds. Modern AI systems produce outputs; humans decide what to do with them. When a credit-scoring model returns 642, a human (or a hard-coded threshold a human picked) decides whether 642 is enough for a loan. Calling the model's output "a decision" obscures who actually made the decision and who is therefore responsible. The technical literature is careful about this; the press almost never is.
Myth 2: "ChatGPT understands what you wrote." Not in the sense most readers mean. The model maps tokens to numerical representations, and those representations capture an enormous amount of statistical structure that lets the model produce fluent, relevant, often correct responses. Whether that constitutes "understanding" is a genuinely open philosophical question. What is not open: the model has no body, no goals, no awareness of being prompted, no continuous experience between conversations. Confusing "produces fluent responses about X" with "understands X" leads to predictable disappointments when you ask the model to do anything that requires actual world-modelling outside its training distribution.
Myth 3: "AI is unbiased — it's just math." Backwards. AI inherits and amplifies the biases of the data it was trained on. A hiring model trained on historical hires reproduces historical patterns, including the discriminatory ones. A facial-recognition model trained mostly on light-skinned faces performs worse on darker-skinned faces. The math is neutral; the data is not, and "the data" reflects the choices of whoever assembled it. Treating AI as objective because it's computer-generated is the single most common pitfall in deploying these systems.
Myth 4: "AI will replace humans imminently." Mostly wrong, but with a sharper version that is partly right. Wholesale replacement of jobs is rare and slow; replacement of specific tasks within jobs is fast and reshapes the work. Coders still have jobs, but the share of the day spent typing boilerplate has dropped sharply. Customer-service agents still have jobs, but the easy tier-1 questions are now handled by chatbots and the agent role has shifted toward harder cases. The mature framing is task-level, not job-level — and even at the task level, deployment moves slower than the demo videos suggest.
Myth 5: "AI is sentient / conscious." The honest current answer is "we have no evidence for this, and we do not have a settled scientific test that could answer it either way." LLMs produce text that sometimes describes the experience of being conscious, because their training data includes a great deal of text written by conscious humans. The presence of such output is not evidence of inner experience any more than a parrot saying "I love you" is evidence the parrot loves you. Be sceptical of anyone claiming proof in either direction.
8. AI in 60 seconds: 1956 to 2026
The whole field, fast, with the moments that actually mattered.
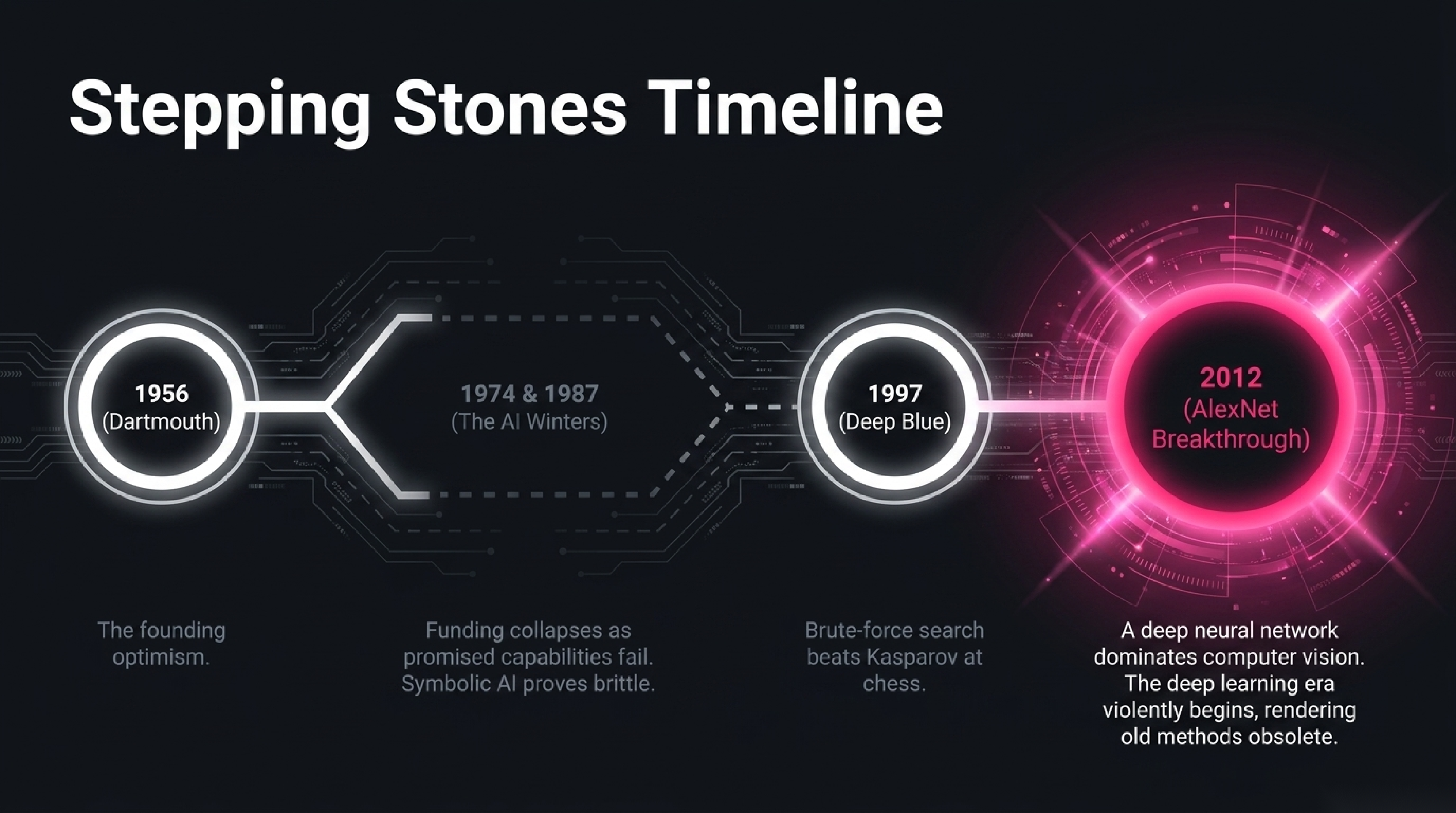
1956 — Dartmouth. John McCarthy organises a two-month workshop and coins the term artificial intelligence. The room is optimistic. They believe major progress is years away.
1960s–70s — Symbolic era. Programs solve algebra problems, prove theorems, play chess at amateur level. In a 1957 prediction (published the following year), Newell and Simon claim "within ten years a digital computer will be the world's chess champion." It actually takes forty.
1974–1980 and 1987–2000 — Two AI winters. Funding collapses twice when promised capabilities fail to materialise. The field learns that overpromising has consequences.
1980s — Expert systems. Rule-based AI finds commercial use in narrow domains. Brief boom, then bust as the systems prove brittle outside their rule sets.
1997 — Deep Blue beats Kasparov. The first time the world chess champion loses a match to a computer. The computer is brute-force search, not learning, but the cultural moment is enormous.
2006 — Deep learning revived. Hinton and colleagues popularise the modern usage of "deep learning" and show that multi-layer neural networks, declared dead for two decades, can be trained successfully with new techniques. The community is sceptical.
2012 — ImageNet / AlexNet. A deep neural network beats the entire computer-vision field at image classification by an enormous margin. Within eighteen months, the entire field of computer vision converts to deep learning. The deep learning era begins.
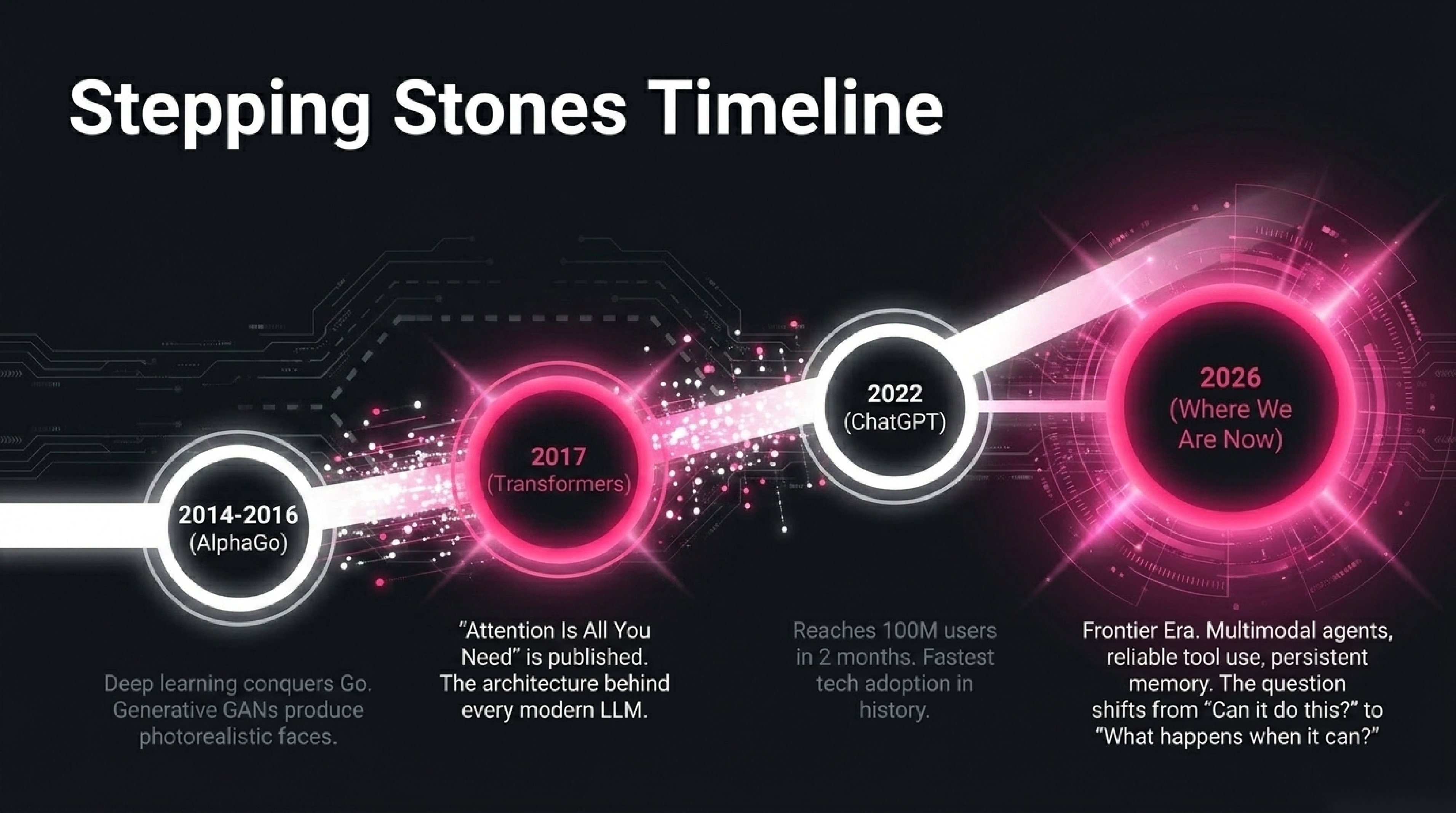
2014–2016 — Generative models, AlphaGo. GANs produce photorealistic faces of people who don't exist. DeepMind's AlphaGo beats world Go champion Lee Sedol 4–1. The breadth of deep learning's capability becomes undeniable.
2017 — Transformers. Vaswani et al. publish "Attention Is All You Need," introducing the transformer architecture. This is the single most consequential architecture paper of the era; every modern LLM is built on it.
2018–2020 — GPT-1, GPT-2, GPT-3. OpenAI demonstrates that scaling the same transformer architecture to ever-larger sizes yields surprisingly general capabilities. GPT-3 (175B parameters, 2020) shocks the field.
2022 — ChatGPT. A chat interface on a fine-tuned GPT-3.5 reaches 100 million users in two months. The fastest consumer technology adoption in history. AI enters the public conversation permanently.
2023–2025 — Frontier era. GPT-4, Claude, Gemini, multimodal models, AI agents that use tools, image and video generators good enough to fool the average viewer. Compute spend per training run crosses one billion dollars.
2026 — Where we are now. Models with reliable tool use, persistent memory, and increasingly autonomous agentic capability. Multimodal interaction (text, image, audio, video) is standard. The question dominating research and policy is no longer "can AI do this?" but "what happens when it can?".
That is seventy years in twelve bullets. Every other thing you'll read about AI history is filling in the spaces between those moments.
9. Where to read next
If this post did its job, you now have a working mental model of what AI is, how today's AI learns, and the four concentric circles (AI / ML / Deep Learning / LLMs) that get conflated. The next steps depend on where you want to go.
If you want to see how a real model actually learns, open the Teach a Tiny AI lab and spend ten minutes there. The intuition you build will carry you through most of the rest of the encyclopedia.
If you want to follow the breadcrumb trail of the underlying ideas, the next two posts in the encyclopedia after this one cover the definition of intelligence itself and how machine intelligence differs from human intelligence. Both are short and necessary before you go deeper.
If you want to jump straight to the modern era, read our explainers on what attention is — the mechanism behind every modern LLM and what mixture-of-experts is — the architecture behind cheaper trillion-parameter models.
If you want the full curriculum, the entry point is the AI Encyclopedia — 130 phases, 2,600 concepts, organised from foundations through AGI.
And if you want to bookmark one thing from this post: modern AI is gradient descent on a lot of data. Everything else is engineering on top of that one idea.

Further reading: Dartmouth Summer Research Proposal (McCarthy, 1955), Attention Is All You Need (Vaswani et al., 2017), Deep Learning (Goodfellow, Bengio, Courville).
How we use AI and review our work: About Insightful AI Desk.