Human vs machine intelligence: where they actually differ
How humans and machines actually differ in 2026 across five axes — data efficiency, embodiment, transfer, common sense, energy — where they're surprisingly similar, and why the productive frame is complement, not replicate. With a 4-challenge lab.

By Kenji Tanaka, Insightful AI Desk
Once you accept that intelligence has several real definitions, the next obvious question is how human intelligence and machine intelligence actually differ. The popular version of the answer is well-worn and mostly wrong. Computers are fast at math, humans are good at creativity. Computers are logical, humans are emotional. Computers do not "really" understand anything; humans do. Each of these contrasts has a grain of truth and a structural error. They were all assembled before frontier AI systems existed and have not been updated for what those systems can and cannot do in 2026.
This post is the updated version. We walk through the five axes on which humans and machines actually diverge today — data efficiency, embodiment, transfer, common sense, and energy — note where the two are surprisingly similar, and finish with the open question at the bottom of the comparison: is there anything humans do that machines fundamentally cannot?
🎯 Companion lab: Where humans and machines diverge — four mini-challenges that ask you to do what current AI is good at, then what it is bad at, then compare scores side-by-side. The gap between the two axes is the actual subject of this post.
1. Why this comparison is harder than it sounds
Before any axis, two genuine difficulties. First, "human intelligence" is not a single thing. A four-year-old learning a new card game from two demonstrations, a chess grandmaster reading thirty moves ahead, an emergency-room nurse triaging an unfamiliar case — these all count as human intelligence and they share almost nothing operationally. Comparing "human intelligence" to a model is comparing one specific human capability to one specific model capability, with the wide distribution of either left implicit.
Second, "machine intelligence" in 2026 is wildly heterogeneous. A frontier large language model, a protein-structure predictor, a self-driving stack, a hand-crafted chess engine — every claim about "what AI can do" is really a claim about one of these and rarely transfers to the others. The nested AI / ML / DL / LLM hierarchy we walked through previously matters here: a comparison between humans and "AI" without naming the kind of AI is almost always going to mislead.
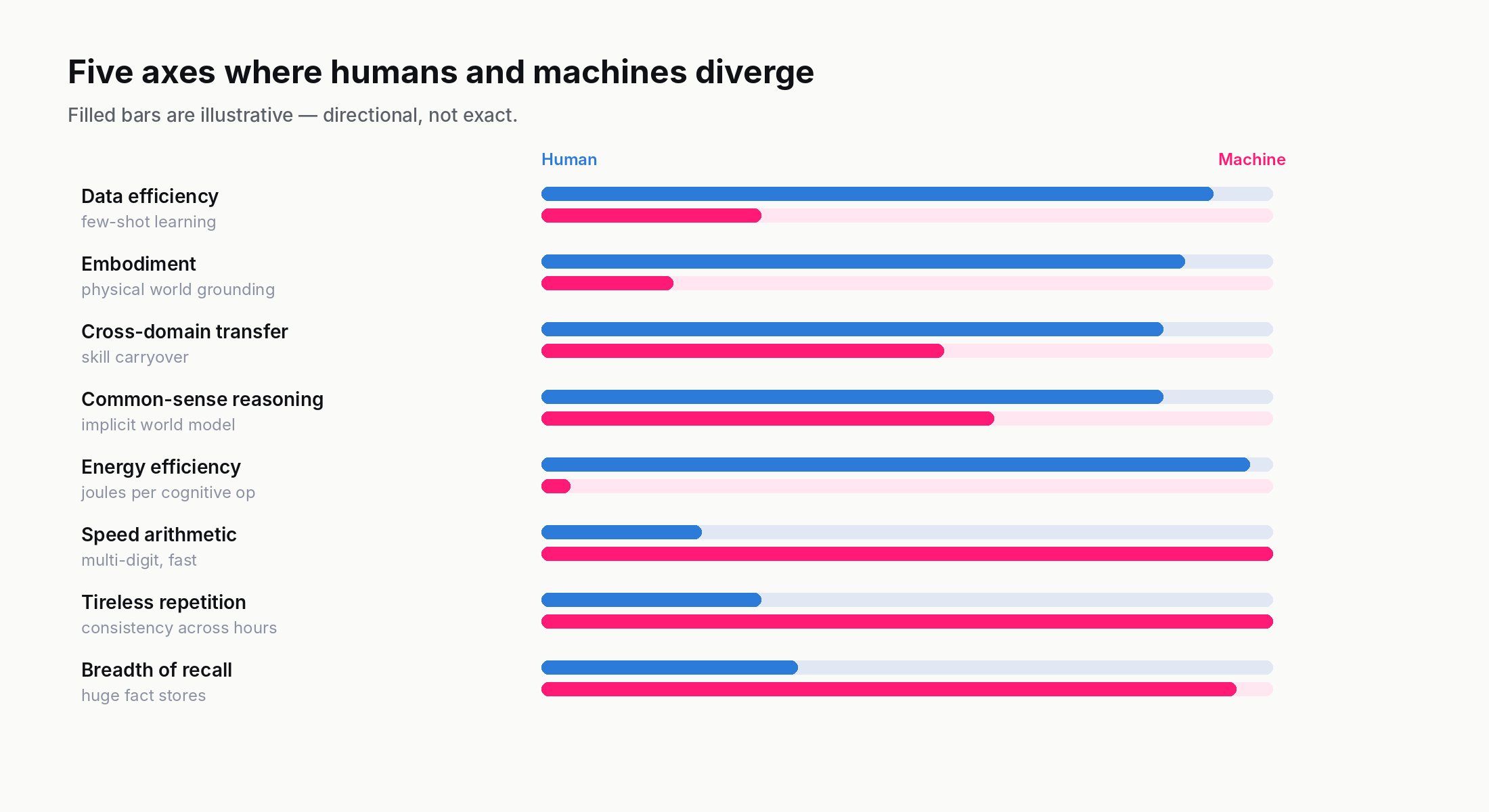
The honest comparison fixes a task and a definition of intelligence, then asks how humans and a specific machine system perform on it. With that discipline, the differences in 2026 cluster into five recurring axes.
2. Axis one: data efficiency
This is the cleanest and most-cited difference. Humans learn new skills from a handful of examples. Machines, especially current deep neural networks, need many orders of magnitude more.
A four-year-old shown two photos of an unfamiliar animal (a tapir, say) can usually recognise the next tapir they see, even one in a different pose, lighting, or environment. A modern image classifier trained from scratch typically needs thousands of labelled examples to reach the same recognition reliability. The gap closes for frontier LLMs in narrow ways: a model with a few hundred billion parameters can "few-shot learn" a task by being shown five examples in its context window, and often does quite well. But the prerequisite for that performance is having pretrained on the equivalent of the entire public internet first. The few examples are not actually doing the learning; the trillion-token pretraining is.
This is the gap that Chollet's ARC benchmark was constructed to expose. ARC puzzles are visual pattern problems that look easy to humans because they require very little prior knowledge — a school-aged child can solve most of them after seeing two or three examples. Until 2024, frontier LLMs scored near chance. OpenAI's o3, released in late 2024, scored about 76% on ARC-AGI-1 in low-compute mode and around 87% in high-compute mode — a leap that closed a previously enormous gap. The 2025 follow-up, ARC-AGI-2, has reopened it; on the harder benchmark frontier models again sit far below the human ceiling. The pattern matters: given enough compute and the right scaffolding, machines can climb a few-shot benchmark — but the human baseline keeps moving up as benchmarks get harder, because human few-shot learning generalises in ways the current methods do not.
For practitioners: the data-efficiency gap is why teaching a system a new task in production typically takes thousands of labelled examples, or — increasingly in 2026 — careful prompt engineering plus a smaller fine-tuning set. If you ever find yourself wanting an AI system to "just learn from a few examples like a human would," recognise that the technology to do this reliably is still a research target, not a product.
3. Axis two: embodiment and sensorimotor grounding
Humans have bodies. Almost all human intelligence was shaped, over evolutionary time and within each individual life, by acting in a physical world that pushes back. We learn that ice is slippery by sliding; that hot objects burn by touching; that we cannot occupy the same space as a wall by attempting to. By the time a human can talk, they have a deeply integrated model of how the physical world behaves, and this model is the foundation on which they later build abstract reasoning.
LLMs do not have any of this. They were trained on text — descriptions of the world, never the world itself. When a frontier LLM answers a physics question correctly, it is matching patterns in text written by humans who do have embodied knowledge; the LLM's correctness is borrowed, not first-hand. This is why LLMs surprise people in two opposite directions. They are sometimes much better at physical-reasoning questions than expected (because so much text describes physical situations), and sometimes much worse (because edge cases that no human bothered to write down are exactly the cases where the model has no source to draw from).
Embodied AI — robotics, self-driving, manipulation — is the other branch of the field. A self-driving stack does have something like sensorimotor grounding: it receives sensor input from the physical world and produces actions that affect the world, and learns from the feedback. By the embodiment axis, a self-driving system is closer to human intelligence than a text-only LLM is, even though the LLM is vastly more capable in other ways. This is part of why robotics and LLM research can produce such different intuitions about "how far we are from AGI" — they are measuring different axes.
The lesson: if you want a system that understands the physical world the way a person does, an LLM is not the right tool, no matter how clever the prompting. Bodies matter.
4. Axis three: transfer and generalisation across domains
A skilled musician who picks up a sport tends to get good at it faster than a non-musician would. A mathematician moving to economics does not start from zero — the abstraction skills transfer. Humans appear to extract structure at a level that survives the change of subject matter. This cross-domain transfer is striking once you notice it; it is also one of the things humans do that frontier AI systems do not do well.
Current machine systems are exquisitely good at the task they were trained for and dismal at adjacent tasks they were not. Stockfish, the strongest open-source chess engine, plays chess at super-grandmaster level and would lose to a beginner at Go because it has no Go module. AlphaFold predicts protein structures (and, in AlphaFold 3, broader biomolecular complexes) at superhuman level and cannot do anything outside that domain. Even within language, LLM performance degrades along the gradient of resource availability: English and a handful of other high-resource languages get most of the training data, mid-resource languages perform meaningfully worse, and low-resource languages (Swahili, Yoruba, many indigenous languages) perform dramatically worse, with documented gaps of more than 20 percentage points on multilingual benchmarks. The transfer is partial, and the partition lines fall along data availability rather than linguistic kinship.
The wrinkle in 2026: LLMs are partly an exception to this rule. A single frontier LLM trained on diverse internet data displays meaningful zero-shot competence on tasks it was never explicitly trained for — tax-form analysis, legal contract review, scientific paper summarisation, code generation in dozens of languages — without any task-specific fine-tuning. This breadth was a surprise; nobody predicted in 2018 that the same pretraining recipe would yield so many emergent capabilities. So the picture is not "machines don't transfer" — it is "machines transfer along the axis their training data covers, and the breadth of that axis is now substantial but not human-shaped."
The honest framing: machines have wide partial transfer along the dimensions of their training distribution, and very narrow transfer outside it. Humans have something closer to true cross-domain abstraction. The latter is more useful for novel problems; the former scales much further with compute.
5. Axis four: common sense and implicit world models
The single property of human intelligence that AI researchers have been chasing the longest, and have made the least clean progress on, is common sense. Humans hold a vast implicit model of how the everyday world works — physical objects, social interactions, intentions, plausible futures — and apply it without conscious effort. Most of what makes us competent in unfamiliar situations is this background model, not deliberate reasoning.
Machines have something different. A frontier LLM has been exposed to enough text describing common-sense situations that it produces fluent common-sense-sounding responses to most prompts. But the model's apparent common sense breaks in characteristic ways. Ask a model to solve a puzzle that requires reasoning about a physical situation a human would model effortlessly — say, "a block sits on a table, and you tilt the table 30 degrees, what happens?" — and it usually gets the answer right because that exact scenario is in the training data thousands of times. Ask a slight variation it has not seen — "a block sits on a table, and the floor under the table tilts 30 degrees, what happens?" — and you often get a wrong or inconsistent answer.
The pattern matters: LLMs simulate common sense well within the distribution of cases their training data covered, and fail outside it. Humans simulate common sense well everywhere it applies, including in situations they have never encountered, because the model is genuinely about the world rather than about descriptions of the world. This is the gap that interpretability research is trying to characterise, and that ARC-style benchmarks are designed to expose.
Be cautious about claims that AI has "achieved common-sense reasoning" — they are usually based on benchmarks that the model has effectively seen during training, and the most consequential common-sense failures happen in cases the model has not.
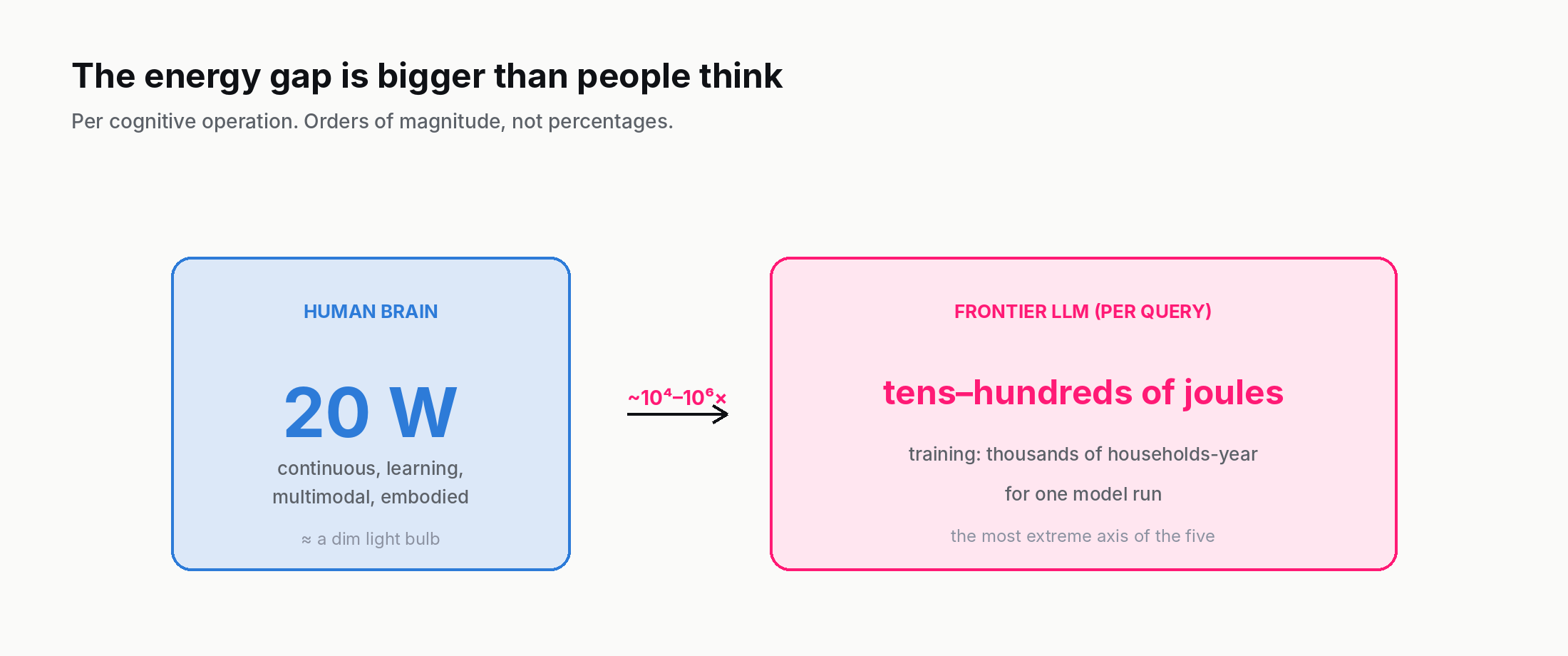
6. Axis five: energy and compute
The least-discussed difference is also one of the largest. A human brain runs on about 20 watts. That is roughly the power draw of a dim light bulb. On this 20-watt budget, the brain learns continuously, integrates multimodal sensory input, runs the body, and produces all the cognition described in this post.
The energy cost of frontier machine intelligence is several orders of magnitude higher. Published estimates (Patterson et al., 2021) put GPT-3's full training at about 1,287 MWh — roughly 120 US households' annual electricity use. GPT-4-scale training has not been disclosed officially, but analyst estimates land in the 10-25 GWh range, equivalent to one to a few thousand household-years per model. Inference per query is much cheaper than training but still substantial: a single complex frontier-model query uses on the order of hundreds of joules per response (a few joules per output token, times a few hundred tokens), compared to brain energy spent on the same cognitive task that is hard to measure cleanly but indisputably orders of magnitude lower.
The order-of-magnitude framing is the part that matters here. Even with the most aggressive efficiency improvements between 2024 and 2026, no published calculation puts silicon-based frontier inference within a couple of orders of magnitude of brain-equivalent efficiency on the cognitive operations both can perform. This is the axis on which the gap is most extreme and shows the least sign of closing — algorithmic improvements compete against the physical reality that current silicon does not yet learn as efficiently as biological tissue.
This matters practically because it sets a ceiling on how widely AI can be deployed without large infrastructure spend, and shapes the long-term research direction (neuromorphic computing, sparser networks, mixture-of-experts, all motivated partly by closing this gap).
7. Where they're surprisingly similar
Stating the differences honestly forces us to acknowledge the similarities, which are often overlooked.
Both have biases from their training data. A human raised in one culture will hold beliefs and reactions shaped by that culture, often without recognising them as cultural. An LLM trained on internet text holds whatever average-of-the-internet biases the corpus encoded. The mechanism is different — neuronal versus parametric — but the surface phenomenon is the same: judgements that look universal turn out to be statistical residues of training experience.
Both confabulate when uncertain. Humans famously fill in memory gaps with plausible inventions, and report the inventions with the confidence of memory. LLMs generate plausible text in response to prompts whose answers they do not actually have, and do so with the same fluency they use for things they do know. The mechanisms are different; the failure mode is recognisable. Anyone evaluating either humans or LLMs needs a calibration test that does not rely on the system reporting its own confidence.
Both fail under distribution shift. A doctor competent on the patient population they trained against may be miscalibrated on a different population; the same is true of a medical-AI system fitted on one hospital's data and deployed at another. Distribution shift is the problem in deploying both humans and machines outside their training environment.
Both are statistical pattern matchers, partly. Saying "LLMs are just pattern matchers" is a popular dismissal that overlooks how much of human cognition is also pattern matching, executed on neural hardware. The cleanest current framing is that both humans and modern AI systems are doing pattern recognition + abstraction, but the proportions differ, the substrate differs, and the operating envelope differs. Pretending they share nothing is a bigger error than pretending they share everything.

8. The big open question — is there a thing humans do that machines fundamentally cannot?
The honest answer is: we do not know, and the people who are most certain in either direction have the least visibility into the actual research.
The strong position that machines will eventually do everything humans do, and likely more, rests on the observation that no fundamental physical or computational argument has ever been made for why a sufficiently large and well-trained machine could not replicate any specific human capability. Every claim of "machines will never do X" in the history of AI has eventually been overturned (chess, then Go, then natural conversation, then theorem proving, then protein folding). The pattern is so consistent that betting against it is statistically unwise.
The strong position that machines cannot replicate human intelligence in some fundamental way rests on more philosophically loaded claims about consciousness, subjective experience, embodiment, or the role of evolutionary history. These claims are not refutable on engineering grounds, but they are also not testable by engineering means, which makes them difficult to make progress on. The cleanest empirical version of the position is that narrow systems will continue to outperform humans at narrow tasks indefinitely, and human-breadth flexibility will continue to be hard to reach by scaling. That position is supported by some 2026 evidence (the gap between frontier benchmarks and ARC-AGI-2-style generalisation tasks) and undermined by other 2026 evidence (the breadth of zero-shot capability in frontier LLMs).
The serious answer in 2026 is that we are running the experiment. Every year of frontier model development is a data point on the question. Anyone telling you the answer with certainty in either direction is selling you a position, not reporting an observation.
9. The practical takeaway — complement, do not replicate
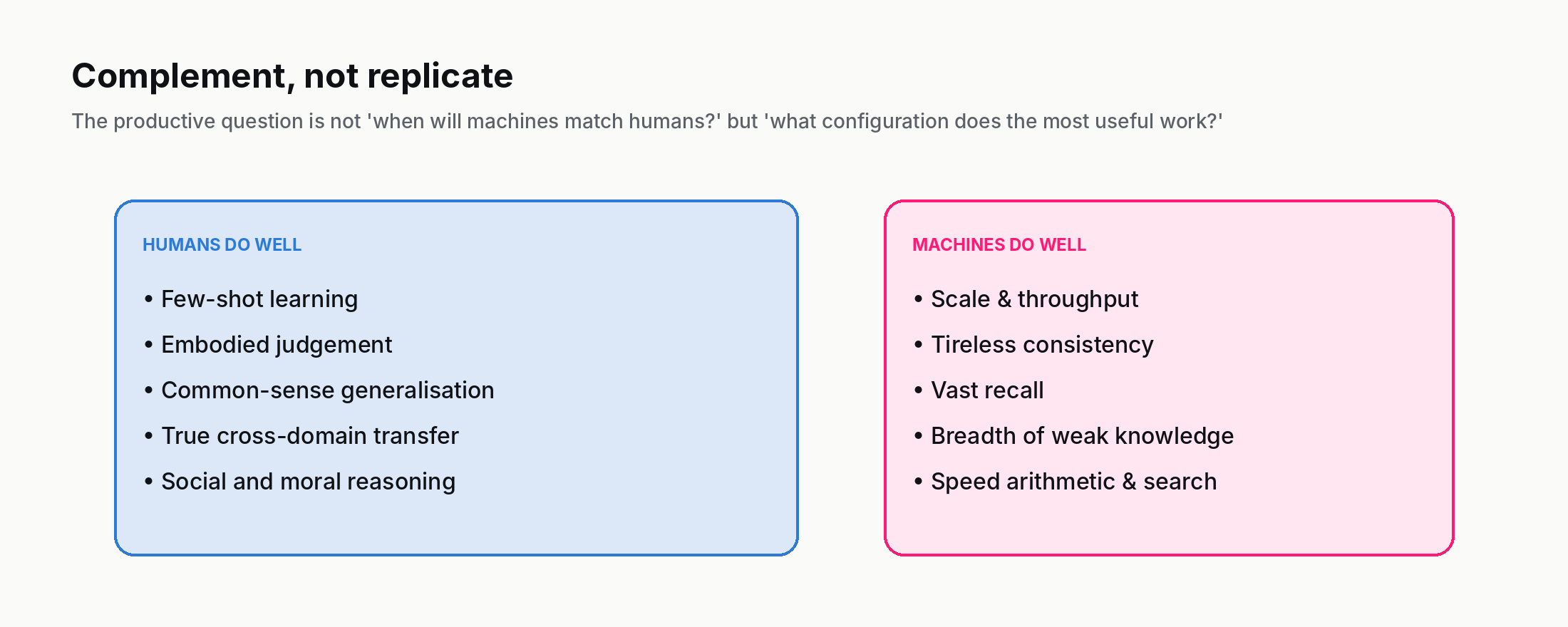
Even with all five axes mapped honestly, the practical conclusion is simple. The most productive uses of AI in 2026 are not trying to build "AI as a human." They are building AI that does the things machines are now good at, and leaves the things humans are still good at to humans.
Machines: scale, recall, computational consistency, breadth of weakly-related knowledge, tireless repetition.
Humans: data efficiency, embodied judgement, common-sense generalisation, true cross-domain transfer, social and moral reasoning.
A doctor reading 200 patient files supported by AI that flags anomalies in each is using machines well. An AI system asked to diagnose without a doctor in the loop is being asked to operate where its data efficiency, common sense, and embodiment limits are most exposed. A coder using an LLM to draft boilerplate they then review is using machines well. An autonomous coding agent operating on production code without review is being asked to operate where its lack of contextual judgement is most expensive.
The deepest practical insight from the five axes is that complement is a more productive frame than replicate. The interesting question for AI in 2026 is not "when will machines match humans on every axis?" but "what configuration of human + machine produces the most useful work on this task?" That question has different answers in different settings, and is the one most worth asking.
10. Where to read next
The Where humans and machines diverge lab lets you try four short challenges yourself and compare your scores against frontier AI performance on the same tasks. Spend five minutes there — the gut feel for the five axes is much sharper after the lab than after the article alone.
For the conceptual chain: this post built on What is intelligence? The definition AI inherits (Topic 0002), which established that "intelligence" is not a single thing — and on What is artificial intelligence? (Topic 0001), which set up the AI / ML / DL / LLM hierarchy. The next post in Phase 001 is AI, Machine Learning, Deep Learning — how they differ, which we already covered in the Topic 0001 explainer; after that comes Symbolic AI and the three flavour history.
If you want the full curriculum, the entry point is the AI Encyclopedia — 130 phases, 2,600 concepts.
And the one-line takeaway, if you keep one thing: humans and machines have different strengths, and the productive frame is complement, not replicate.
Further reading: On the Measure of Intelligence (Chollet, 2019), The Bitter Lesson (Sutton, 2019), Sparks of AGI (Bubeck et al., 2023).
How we use AI and review our work: About Insightful AI Desk.