What is intelligence? The definition AI inherits
Four serious, mutually inconsistent definitions of intelligence — psychometric, biological, generalisation-efficiency, and multiple-intelligences — and why which one you accept silently decides which AI you build. With an interactive yardstick lab.
By Kenji Tanaka, Insightful AI Desk
The word "artificial" in artificial intelligence is the easy half. We can argue about what "artificial" means, but the disagreement is technical and bounded. The other word is the hard one. Sixty-eight years after the field was named, "intelligence" still has no single accepted definition, even among the people whose careers depend on measuring it. Some psychologists call it a single underlying capacity. Others call it a collection of weakly correlated skills. AI researchers, who need a definition concrete enough to engineer toward, have spent the last decade arguing about a third frame entirely.
This matters more than it sounds. The definition of intelligence you accept silently picks the AI you build. Define intelligence as doing well on tests of a fixed set of cognitive tasks, and you get systems like GPT-4 — trained to score high on benchmarks, sometimes at the cost of generalising to anything the benchmark missed. Define it as solving new problems efficiently with little prior exposure, and you get a different research programme, one that values data efficiency over benchmark scores. Define it as adapting flexibly to a changing environment, and you pivot toward embodied robotics and continual learning. Same word; three different fields.
This post walks through the actual definitions in serious use today, where each comes from, what it captures and misses, and why this very abstract-sounding question is the silent foundation under every concrete AI claim you read in the news.
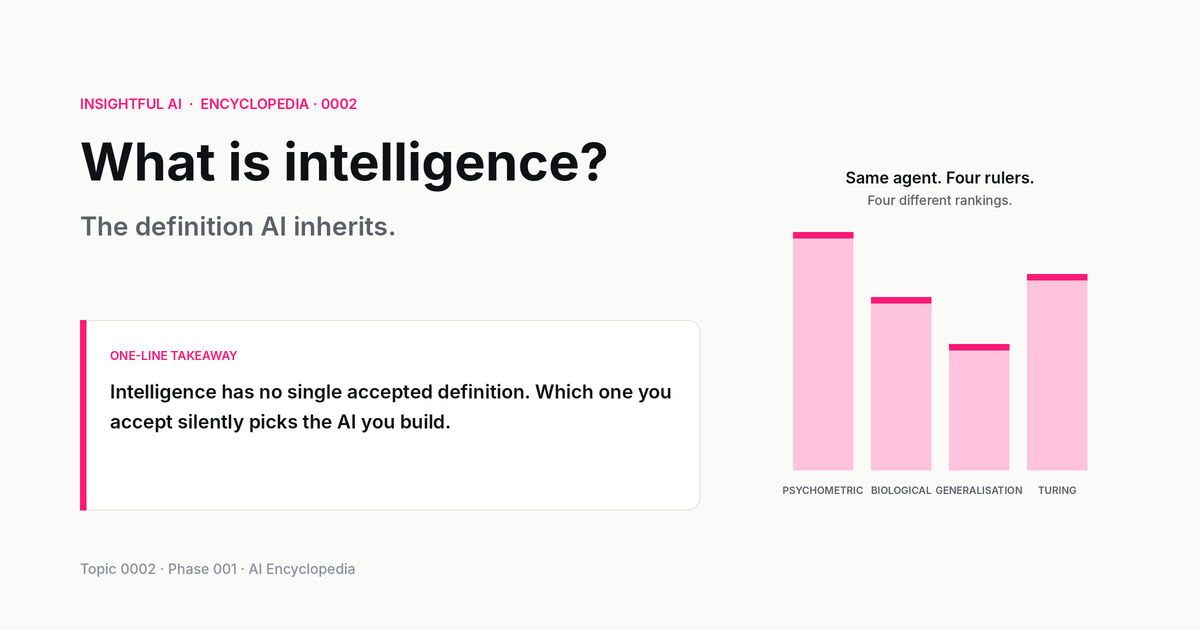
🎯 Companion lab: The Intelligence Yardstick — pick a definition of intelligence, watch eight different agents (human, GPT-4, AlphaFold, octopus, calculator, infant, ant colony, Stockfish) re-rank against each other. The same agents look smarter or dumber depending on which yardstick you apply.
1. Why intelligence resists definition
Most concepts in science get cleaner over time. A century ago "atom" was contested; today the definition is sharp enough that students measure things with it. Intelligence has gone the opposite direction. The more we have studied it, the harder it has become to say what we mean.
Part of the difficulty is that intelligence is what philosophers call a cluster concept. We confidently apply the word to humans, octopuses, language models, chess engines, social-insect colonies, and (some of us) thermostats — but the resemblance between these cases is more like a family resemblance than a shared essence. A few common threads run through most of them: solving problems, adapting to novel situations, learning from experience, using abstraction. No single thread runs through all of them in the same way.
The other difficulty is that we historically defined intelligence by comparison to ourselves. The original IQ tests, developed by Binet in 1905, were designed for one specific purpose — identifying French schoolchildren who needed extra educational support. They worked well for that. They were never validated as a definition of intelligence in general; they became one by drift. For most of the twentieth century, "intelligent" effectively meant "good at the tasks human adults are good at". This was fine until we started building things that were superhuman at one specific human task (chess, then Go, then protein structure prediction, then long-form text generation) while being unable to do the simplest things in any adjacent domain. The 20th-century definition broke.
The current state of the field is that there are at least four distinct, technically respectable, mutually inconsistent definitions of intelligence in active use — and you can tell which one a researcher is using by reading their abstract.

2. The psychometric definition: intelligence as what IQ tests measure
The oldest formal definition is operational: intelligence is what is measured by intelligence tests. E. G. Boring offered this in 1923 as a pragmatic stopgap in response to popular criticism that intelligence testing had run ahead of any underlying theory; the phrasing has stuck ever since, and is now the working definition of much of psychometrics.
Modern IQ tests measure performance on a battery of subtests — vocabulary, pattern completion, working-memory tasks, mental rotation, arithmetic. Statistical analysis of test results across large populations consistently shows that these subtest scores are positively correlated — people who do well on vocabulary also tend to do better than average on pattern completion, and so on. The shared variance across all the subtests is called the g-factor, for "general intelligence", and is the closest thing psychometrics has to a single number for intelligence.
The psychometric definition has two big strengths. First, it is measurable: g-loaded test scores correlate with educational attainment, job performance in cognitively demanding roles, and a number of life outcomes, at correlations that are small-to-medium but robust across hundreds of independent studies. Second, the underlying construct (g) is unusually stable across an individual's adult life — your test score at age 25 is usually a strong predictor of your test score at age 65.
And it has two big weaknesses, both directly relevant to AI. First, the tests are calibrated entirely on human distributions. A system that scored 200 on a vocabulary subtest by memorising every word in every language would not be doing what humans do at score 200; it would be doing something different that happened to produce the same number. (This is why people argue that LLM "performance on the SAT" is at best a weak signal of intelligence — it's optimising for the exact distribution the test draws from.) Second, IQ tests measure a narrow band of cognitive skills and almost no others — they do not measure creativity, social intelligence, motor skill, common sense, or many of the things people most associate with being "smart" in everyday life.
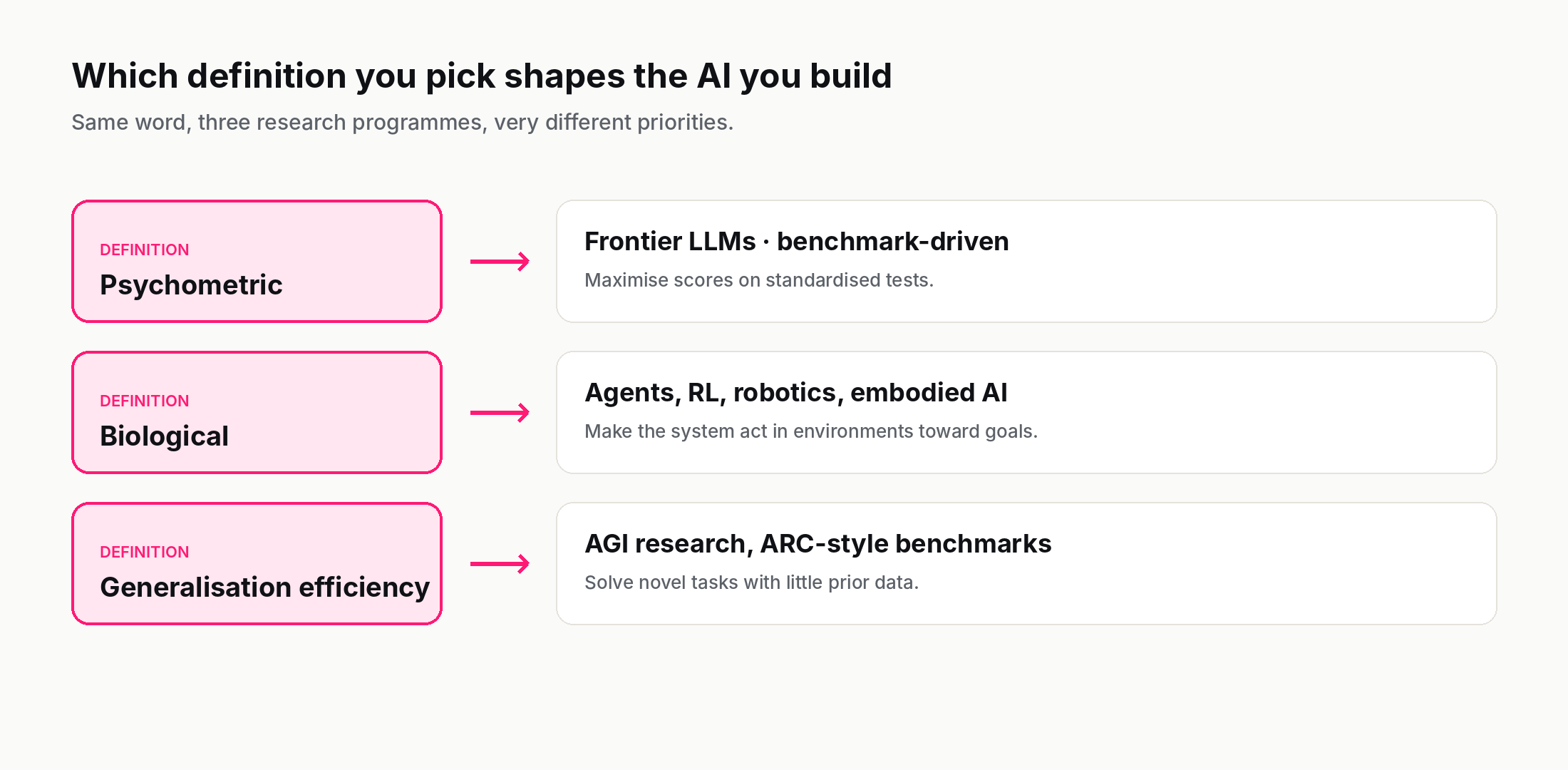
The psychometric definition is dominant in cognitive psychology, controversial in education policy, and irrelevant to almost all of AI research — but it still shapes how the press evaluates AI ("GPT-4 scored 90th percentile on the bar exam"), so it is worth knowing where the framing comes from.

3. The biological definition: intelligence as adaptive information processing
A different tradition, rooted in biology and neuroscience, defines intelligence not by test scores but by what an organism's nervous system does. The classical formulation is something like: intelligence is the capacity of a system to receive information from its environment, integrate that information against internal state, and select actions that increase the system's chance of survival or goal achievement.
This definition has obvious appeal. It is grounded in evolutionary biology — intelligence is whatever the brain was selected for. It applies cleanly to animals other than humans (an octopus opening a jar to retrieve food displays intelligence on this definition without ever taking a test). And it scales naturally to engineered systems: a thermostat is a very mild example of intelligence in this sense, a self-driving car is a much stronger example, and a frontier LLM doing tool-use is somewhere in between.
The weakness of this definition is that it makes "intelligent" a continuous property of almost anything that processes information, which makes the word less useful, not more. If your thermostat counts, so does a bimetallic strip. Most biologists who use this definition implicitly require some threshold — flexible integration of diverse kinds of information, adaptation to novel situations, planning over extended time horizons. But once you start adding those qualifiers, you are partly recovering the everyday notion of intelligence rather than the bare biological one.
The biological definition is dominant in animal cognition and comparative psychology. It also informs much of robotics and embodied AI — a self-driving car evaluated against the biological definition looks much more intelligent than the same car evaluated against a vocabulary test, and that re-ranking is part of why robotics and language-modelling research feel like such different fields.
4. The generalisation definition: intelligence as skill-acquisition efficiency
The most influential definition for modern AI research is much more recent. In 2019, François Chollet — at the time at Google, author of the Keras library — published a paper called On the Measure of Intelligence that explicitly tried to define intelligence in a way that distinguished humans (and other generalising systems) from machines that score well on benchmarks by memorising the answer distribution.
The central claim of Chollet's paper, paraphrased plainly: intelligence is the efficiency with which a system acquires new skills, normalised by how much prior knowledge it brought in and how much experience it consumed getting there.
The formal statement is a ratio: how much skill you gain, per unit of prior knowledge plus experience consumed. A system that scores 90% on a benchmark after seeing a billion examples is not, by this definition, displaying high intelligence — it is displaying high performance, achieved through extraordinary data. A system that scores 90% after seeing five examples is displaying intelligence, because it is generalising. The ratio is what matters.
The intuition lands hard once you see it. A four-year-old human can be taught a new rule for a card game after one or two demonstrations and then play that game competently. GPT-4, given the same two demonstrations in its context, may also play correctly — but in a sense that depends entirely on how similar the new game is to thousands of games it has already seen in training. Strip away those thousands of games (impossible in practice for an LLM; possible in principle with carefully constructed novel tasks) and the four-year-old's lead widens dramatically. Chollet's ARC-AGI benchmark is an attempt to construct exactly such tasks; the human ceiling on it is around 85%, and for years frontier models sat far below that. Progress closed quickly in late 2024 — OpenAI's o3 scored about 76% on ARC-AGI-1 in its low-compute configuration and around 87% in high-compute — which is exactly why ARC-AGI-2, released in 2025 and designed to stretch the same generalisation axis further, has put the human-machine gap back where the framework intended it.
A simplified form of Chollet's measure looks like:
$$\text{Intelligence} = \frac{\text{generalisation difficulty}}{\text{prior knowledge} + \text{experience}}$$
The denominator captures what the system already brought to the problem; the numerator captures how much actual generalisation is required to solve it. A high-priors, high-experience system can score well on tasks with low generalisation difficulty, but the ratio collapses on tasks far from its training distribution. The 2026 research community has not settled on Chollet's exact formulation — many other variants exist — but the shape of his definition has reshaped how rigorous AI labs evaluate progress.
The generalisation definition is the dominant frame in modern AI research, especially among people interested in AGI. It is much less commonly used in psychology, because measuring it on humans is extremely difficult — most human cognitive tasks come pre-loaded with enormous prior knowledge from a lifetime of experience, which makes the denominator very hard to estimate. But for evaluating AI systems, where the priors are knowable (the training data), it is the cleanest definition currently available.

5. The multiple-intelligences view (and why it is more popular than respected)
You may have encountered the idea that there are several distinct kinds of intelligence — linguistic, logical-mathematical, spatial, musical, bodily-kinesthetic, interpersonal, intrapersonal, and a naturalist intelligence added later. The original framework, proposing seven of these, was set out by Howard Gardner in 1983 in his book Frames of Mind; the naturalist intelligence was added in 1995. The theory became enormously popular in educational policy and self-help, and is correspondingly misunderstood.
Gardner's theory has not been embraced by mainstream cognitive science, primarily because the proposed "intelligences" do not show the statistical pattern Gardner's theory predicts. If the eight intelligences were truly independent, scores on tests of each one would not correlate. In practice they do correlate, modestly to strongly, in roughly the same way that g-factor research has documented since the 1900s. Most cognitive psychologists today consider Gardner's framework a useful pedagogical metaphor — it reminds teachers that students differ in their strengths — but not a description of distinct mental capacities that can be measured separately.
For AI specifically, the multiple-intelligences view is mostly irrelevant. Real AI systems are extremely uneven across domains in a way Gardner did not predict — a chess engine has near-infinite "logical-mathematical" intelligence within chess and effectively zero outside it; an LLM has remarkable "linguistic intelligence" and dismal spatial-physical intelligence. The unevenness is real; the eight-buckets framework just doesn't capture it well.
If the multiple-intelligences view comes up in a discussion about AI, what people usually mean is the milder claim that different cognitive skills are partly separable, which is true and unobjectionable. The strong eight-distinct-intelligences claim is contested.
6. A footnote on the Turing Test
Many readers will know intelligence in the context of the Turing Test: Alan Turing's 1950 thought experiment in which a human interrogator chats by text with a hidden interlocutor that is either a human or a computer; the computer is said to "pass" if the interrogator cannot reliably tell which is which.
Turing did not propose this as a definition of intelligence. He proposed it as a deliberate sidestep of the definition question, which he found unproductive. His point: instead of arguing whether a machine "really" thinks, replace the question with whether it can imitate thinking convincingly enough that the difference doesn't matter for any practical purpose. This was a brilliant philosophical move for 1950, when machines were nowhere near plausible imitation; it has aged less well in 2026, when imitation of fluent text is essentially solved but the systems that produce it manifestly do not "think" in many ordinary senses of the word.
The modern verdict on the Turing Test is that it tested something — convincing language production — but not the thing Turing's question was really pointing at. Treat it as a historical milestone, not a working definition.
7. Which definition you use silently picks the AI you build
Here is where the abstract definition discussion suddenly matters for everything else.
If your operating definition is psychometric — intelligence is what tests measure — then AI progress is measured by benchmarks, and the research that gets funded is research that improves benchmark scores. Most of frontier LLM research from roughly 2020 to 2024 sat in this frame, often implicitly. Compute scaling improved benchmarks; benchmarks improved more; the field rewarded both.
If your operating definition is biological — intelligence is adaptive information processing in pursuit of goals — then the natural object of research is an agent in an environment, not a model on a benchmark. Reinforcement learning, robotics, embodied AI, and the recent surge in "AI agents" all sit closer to this frame. This research community has historically been smaller than the benchmarks-and-models community but has grown rapidly since 2024 as agentic systems have moved out of the lab.
If your operating definition is generalisation efficiency — Chollet's frame — then progress is measured by how well systems handle novel tasks they couldn't have memorised, with as little prior data as possible. This community is even smaller numerically but has disproportionate influence on what people mean by "AGI" — the term has been increasingly anchored to "human-level generalisation efficiency" rather than "human-level benchmark performance".
If your operating definition is multiple intelligences — distinct cognitive abilities that don't share a common factor — you mostly don't work on AI, because the framework doesn't translate cleanly into anything you can engineer.
The deepest insight in this whole post is this: almost every disagreement about whether modern AI is "really" intelligent is, underneath, a disagreement about which definition the speakers are silently using. "GPT-4 is brilliant at writing essays so of course it's intelligent" reflects a psychometric/behavioural frame. "GPT-4 fails simple variations of problems in its training data so it's not intelligent at all" reflects a generalisation frame. Both speakers are correct under their own definition. Neither is talking about quite the same thing.
Consider one concrete case: GPT-4 reported in March 2023 as scoring in the 90th percentile on the Uniform Bar Exam, widely covered at the time as evidence of human-level legal reasoning. A subsequent 2024 re-analysis by Eric Martínez found that the 90th-percentile figure compared GPT-4 against repeat takers — a lower-scoring cohort — and that against all takers the percentile dropped to roughly 69th, and against first-time takers only ~48th. Even at the lower number, the data point invites three opposite interpretations. On the psychometric frame, scoring above the median of practising would-be lawyers is a strong intelligence signal. On the biological frame, the score is essentially meaningless — the bar exam was never designed as an environmental adaptation challenge, so passing it tells us little about adaptive information processing. On the generalisation frame, the score is actively misleading — the bar exam questions and answers, plus huge amounts of public bar-prep material, are in the training data, and the percentile reflects performance on a distribution the system has effectively seen rather than novel legal reasoning. Same data point, three opposite interpretations, all defensible given their respective definitions. Most popular AI discourse is exactly this kind of argument, played out without anyone naming which definition they are using.
8. A working definition for the rest of the encyclopedia
Across the rest of the Insightful AI World encyclopedia we use a deliberately broad working definition, chosen because it survives most arguments and clearly distinguishes capability from understanding:
Intelligence is the ability to acquire and apply useful behaviour in pursuit of goals in environments the system was not pre-engineered for, with efficiency that increases as the system gains experience.
This definition borrows the goal-directedness of the biological frame, the experience-driven improvement of psychometrics, the novelty-handling of Chollet's frame, and adds a clean test: environments the system was not pre-engineered for. A thermostat fails this test; a chess engine fails it (outside chess); an LLM partly passes it for natural language; an agentic system attempting a task it has never seen before is exactly the kind of case the definition is meant to cover.
It is not the final word. No single definition will be, until either the question gets settled empirically (probably never) or it gets dissolved entirely (possible — many philosophical questions have eventually been replaced by sharper sub-questions). For the purposes of explaining what AI is doing and where it is going, this is the working definition we will assume.
9. Where to read next
If you want to play with how different definitions reshape rankings, the Intelligence Yardstick lab is the companion to this post. Eight agents, five definitions, instant re-ranking. Ten minutes there will give you sharper intuition for the rest of this section.
If you want to follow the conceptual chain forward, the next topic in Phase 001 is Human Intelligence vs Machine Intelligence — what the definitions we just walked through actually predict about the differences between the two. After that comes AI, ML, Deep Learning — what's the difference, which we already covered in detail in our previous explainer: What is artificial intelligence?.
If you want the full curriculum, the entry point is the AI Encyclopedia — 130 phases, 2,600 concepts.
And the one-line takeaway, if you keep only one thing from this post: "intelligence" is not a single thing; it is a family of useful definitions, and which one you adopt silently decides what AI you build.
Further reading: On the Measure of Intelligence (Chollet, 2019), Computing Machinery and Intelligence (Turing, 1950), Frames of Mind (Gardner, 1983).
How we use AI and review our work: About Insightful AI Desk.