What is mixture-of-experts? The architecture behind cheaper trillion-parameter AI
Mixture-of-experts is how a 671-billion-parameter model can cost less per token than a 70-billion-parameter one. A plain-English guide to MoE, active vs total parameters, routers and experts, and why open-weights frontier labs picked the architecture first.
By Priya Patel, Insightful AI Desk
The most surprising fact about DeepSeek V4 is not how it performs on benchmarks. It is what it runs on. A model in the trillion-parameter neighbourhood should, by the conventional arithmetic of AI inference, demand the kind of hardware footprint reserved for the largest frontier deployments. Instead, it became the open-weights model that small labs, research groups, and even ambitious enthusiasts started self-hosting on a handful of high-bandwidth GPUs. The arithmetic that did not add up has a single answer: mixture-of-experts.
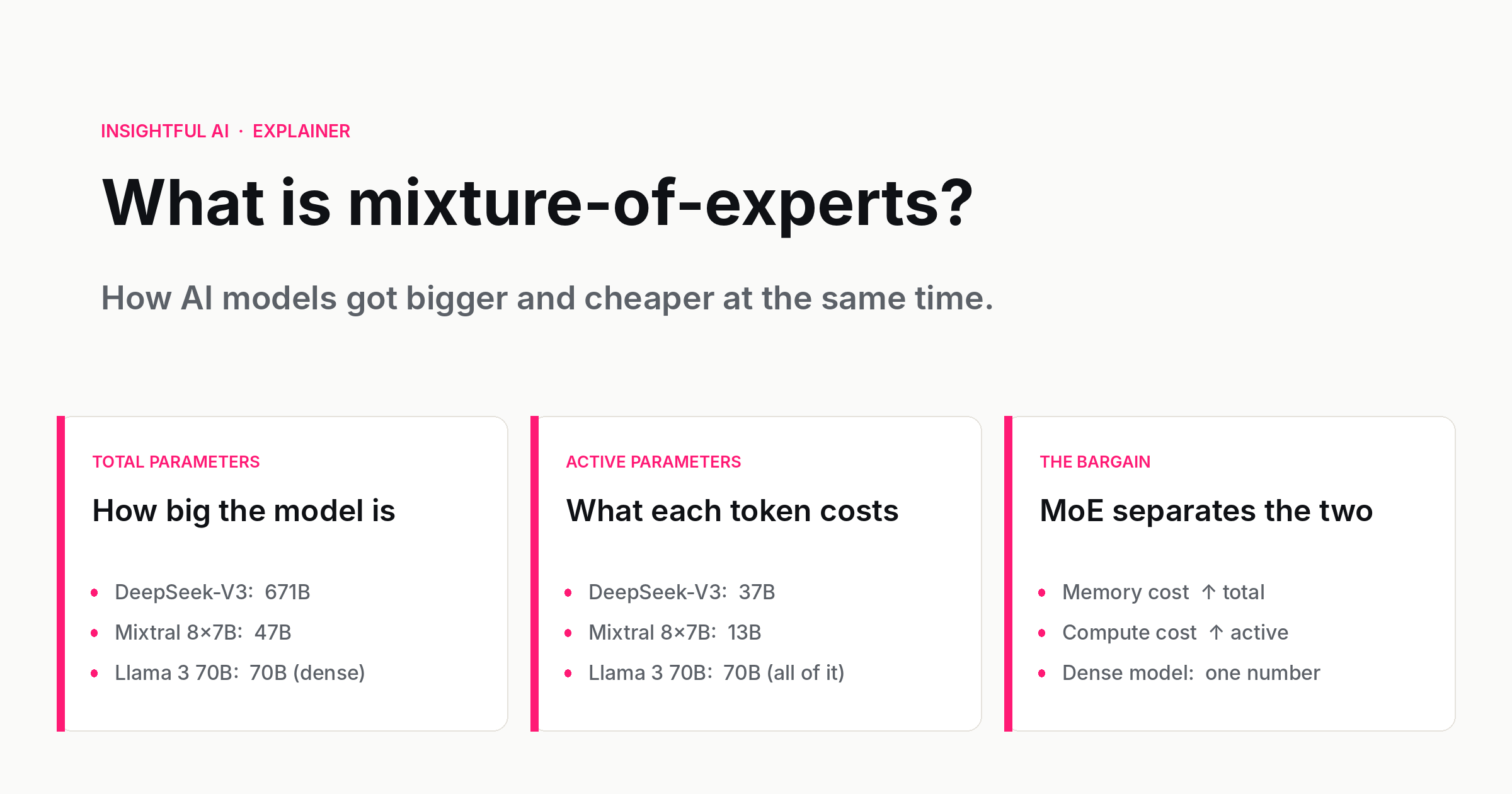
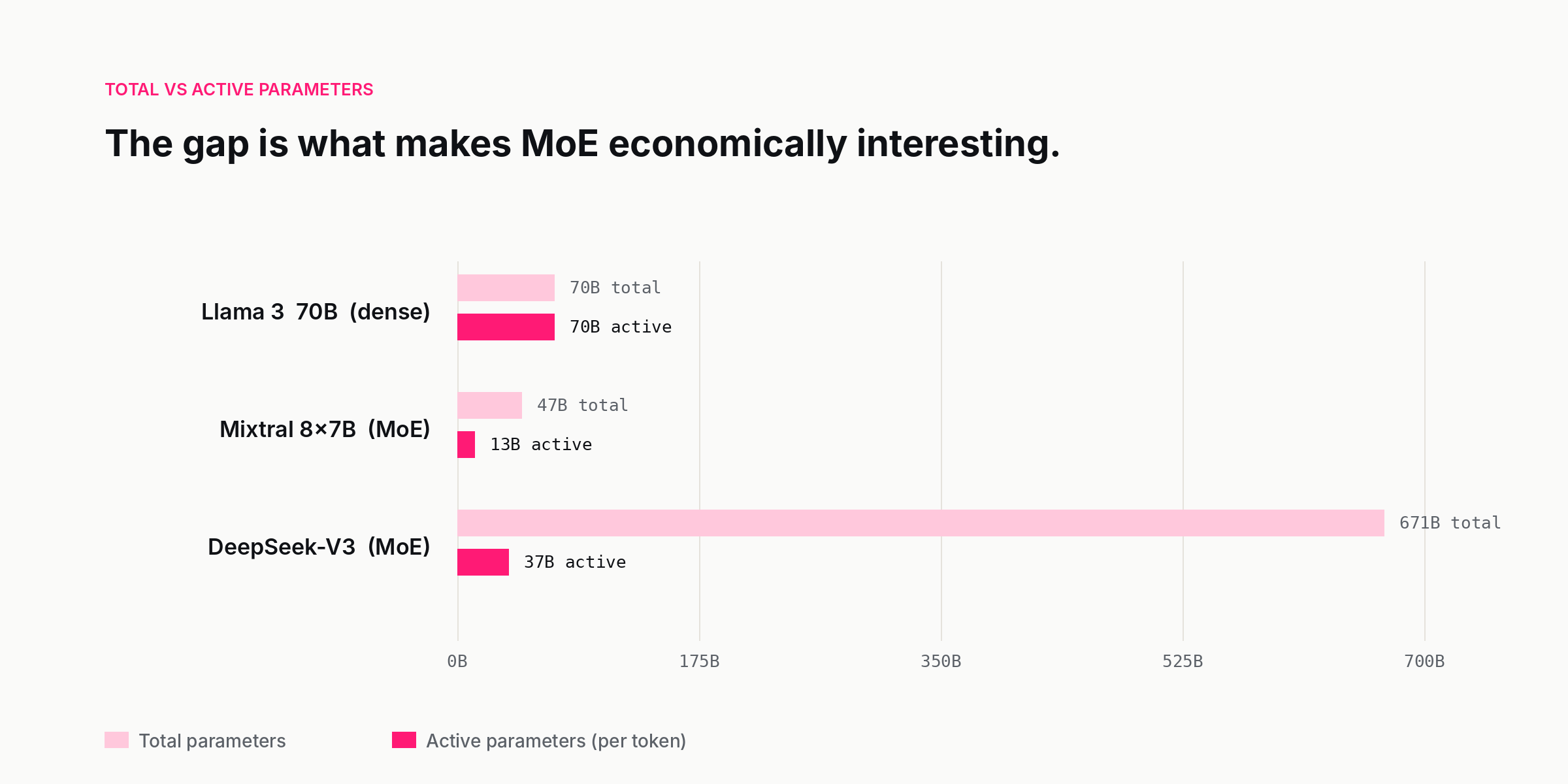
The earlier model in the same family, DeepSeek-V3, is the one whose technical report set the public benchmark. It has 671 billion parameters in total but activates only 37 billion for any single token. The rest of the model is loaded into memory but stays dormant. For the purposes of every forward pass, you are running a 37-billion-parameter model — but a much larger model is choosing, token by token, which 37 billion to use. That choice is what makes mixture-of-experts, or MoE, the most consequential architectural shift in large language models since the transformer itself.
If you have read a launch post or a system card from any of the open-source frontier labs in the last two years and noticed that the parameter count "feels off" — the model is too big to be cheap to run, or too cheap to run to be that big — you have already met MoE. This is the plain-English version.
What mixture-of-experts actually is
A traditional, "dense" transformer is the kind everyone learned to draw on whiteboards in 2018. Every parameter participates in every forward pass. If the model has 70 billion parameters, every one of those 70 billion parameters does numerical work on every token the model produces. The cost scales linearly: more parameters means more compute per token, more memory bandwidth, more energy. This linearity is also what made dense transformers so easy to reason about. The number on the badge — "70B," "175B," "405B" — was a single number that approximated both how capable the model was and how expensive it would be to run.
A mixture-of-experts model breaks that link.
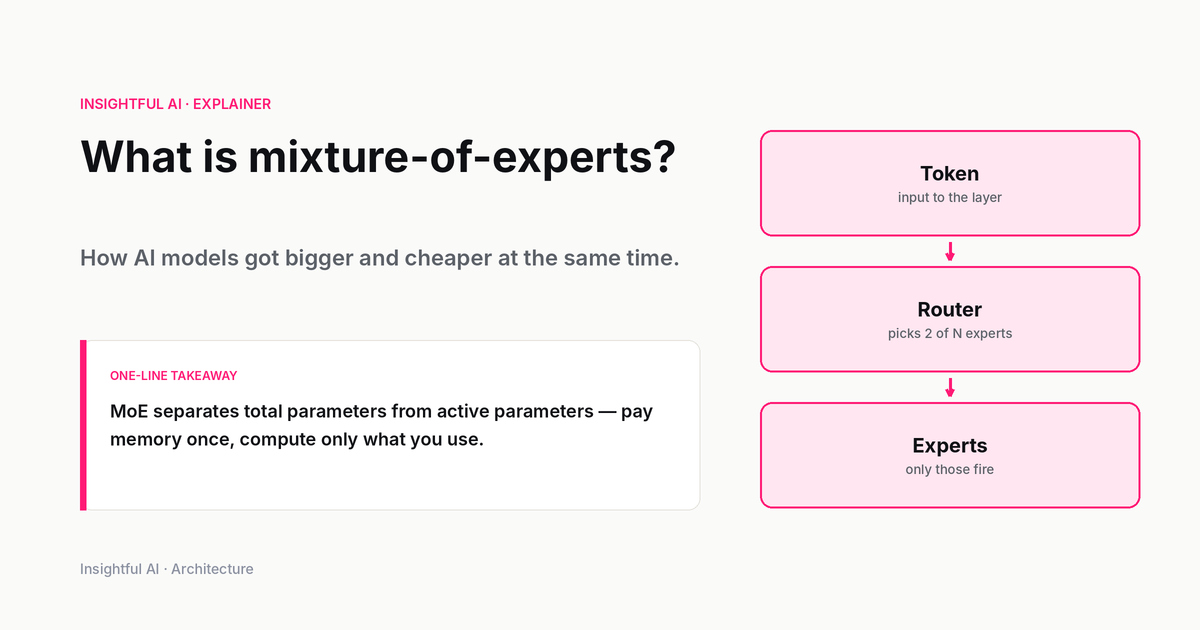
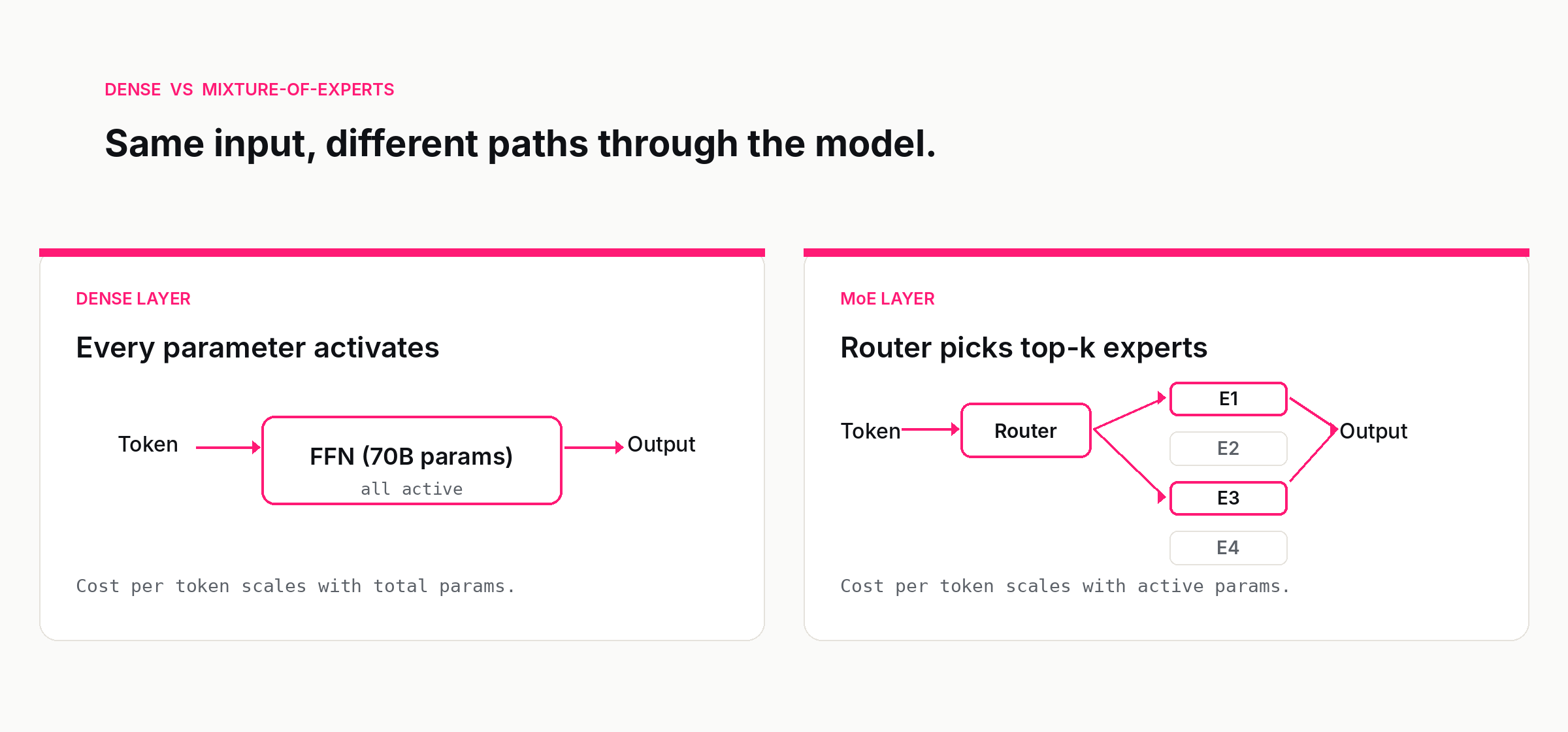
In a dense transformer, each layer has a single feed-forward network sitting after the attention block. In an MoE transformer, that single feed-forward block is replaced by a set of feed-forward networks — the "experts" — and a small router network that decides, for each token, which experts to send the token to. Each token is processed by only a handful of experts. The total parameter count is the sum of all the experts plus the attention and embedding parameters. The active parameter count — the parameters that actually do compute on any given token — is much smaller.
The terminology that has become standard in 2026 is this. A model's total parameters describe how big it is on disk and in memory. A model's active parameters describe how much compute each forward pass costs. The dense transformer collapsed those numbers into one. MoE separated them.
Examples make the distinction concrete. Mixtral 8x7B from Mistral AI has 47 billion total parameters but routes each token through 2 of its 8 experts, so 13 billion parameters activate per forward pass. DeepSeek-V3, the more aggressive design, has 671B total / 37B active across 256 routed experts plus 1 shared expert per layer, with top-8 routing. The names that became casual shorthand — "the 47B Mixtral," "the 671B DeepSeek" — paper over the more useful number, which is what the model costs to actually run.
Why is it called “experts”?
The terminology pre-dates modern deep learning by three decades. The original "mixture of experts" was introduced in 1991 by Jacobs, Jordan, Nowlan, and Hinton — a paper about adaptive systems composed of multiple sub-networks specialising in different parts of the input space, with a gating function deciding which sub-network to use. The 2010s adaptation to deep learning kept the metaphor: each sub-network is an "expert," the gating function is a "router," and the system as a whole is a "mixture."
The metaphor is loose. Modern MoE experts do not specialise in the way the name suggests. There is no "math expert" or "Python expert" or "Mandarin expert" that emerges cleanly from training. The specialisation is real but mostly statistical — different experts capture different combinations of patterns, and the router learns which combinations apply to which tokens. You can probe an MoE model and find that some experts fire mostly on punctuation, or that some clusters of experts handle specific morphological features in a language. But the clean cognitive carve-up that the word "expert" suggests does not materialise. It is a useful name, not a literal description.
How an MoE forward pass works
A mixture-of-experts forward pass has three pieces that need to work together.
The router is a small neural network — usually a single linear layer followed by a softmax — that takes the hidden state of each token and produces a score for each available expert. In a layer with eight experts, you get eight scores per token. The router itself is cheap; its parameters are negligible compared to the experts.
The top-k selection turns those scores into a routing decision. The most common pattern in production is top-2, used by Mixtral and most public MoE deployments since: the two highest-scoring experts process the token, the others do not. Switch Transformer originally proposed top-1 routing to maximise sparsity, but top-2 became the standard because it improves training stability and quality with a small efficiency cost. DeepSeek-V3 went further, using top-8 routing across 256 routed experts plus a single shared expert that processes every token — the shared expert handles general patterns, the routed experts specialise. The trade-off space here is rich and is one of the places where MoE designs differ visibly.
The experts themselves are ordinary feed-forward networks. There is nothing special about an individual expert; what is special is the assembly. During training, gradient signal flows back through both the experts the router chose and, through the routing scores, through the router itself. Over time, the router learns to send tokens with similar properties to similar experts, and the experts converge to handle those slices. The specialisation is usually not the interpretable thing you might hope for, but it is real, and it is the source of the efficiency gains.
Why MoE is winning in 2026
The case for mixture-of-experts used to be primarily a training-economics case. GShard, the 2020 Google paper that brought MoE into the modern LLM era, scaled a 600-billion-parameter multilingual translation model on 2048 TPU v3 chips in four days, a feat that would have been impossible with a dense model of the same parameter count. Switch Transformer in 2021 pushed the architecture past a trillion parameters. For a few years, MoE was thought of as a training trick — a way to get more capacity per dollar of training compute on a fixed hardware budget.
Three things made it an inference story too.
The first was the publication of Mixtral 8x7B in late 2023, which demonstrated that a 13B-active MoE could match the quality of a 70B dense model on most benchmarks while costing a fraction of the compute per token. That broke the assumption that MoE was a research curiosity. It also broke a procurement assumption: enterprise buyers who had been negotiating compute budgets based on parameter counts suddenly had to negotiate based on active parameters, and the conversation got more complicated and more honest at the same time.
The second was the DeepSeek-V3 technical report in December 2024, which made the open-weights MoE the model class to beat at the frontier. DeepSeek's V4 release in 2026, the one that started the current self-hosting wave, extended the pattern further. A trillion-class total parameter count with active parameters in the tens of billions, self-hostable on hardware that nobody would describe as exotic, demonstrated that the inference-economics story was not specific to one design or one lab.
The third pressure was simply the cost of inference. As deployments scaled and the FinOps conversation around AI sharpened, the inference bill became the dominant cost line for many AI products. Total parameters drive memory cost; active parameters drive compute cost. MoE lets you trade one against the other in a way dense models cannot.
The implication is uncomfortable for anyone who built a procurement process around parameter counts. A buyer who was choosing between "a 70B dense model" and "a 671B MoE model" in 2024 was implicitly choosing between two cost profiles that do not match the parameter labels at all. The MoE model is bigger on disk and bigger in memory — but cheaper per token to actually run. Whether that tradeoff is the right one for a given deployment depends on whether memory or compute is the binding constraint, and that question, more than any single benchmark, has become the central procurement question for self-hosted AI in 2026.
The hard parts
For all the elegance of the idea, mixture-of-experts is not a free lunch. There are five well-understood ways it can go wrong, and dealing with each of them was the real research contribution of the foundational papers.
Load imbalance is the simplest failure mode to describe. Without intervention, the router collapses onto a few favourite experts and sends most tokens to them. The other experts go un-trained; their parameters take up memory but produce nothing useful. The standard mitigation is an auxiliary loss that penalises imbalance — usually a term that pushes the gradient toward token assignments that are roughly uniform across experts. The auxiliary loss is added to the main training objective and has to be tuned carefully: too much and you constrain the router's flexibility, too little and the experts collapse.
Token dropping is the cousin failure mode. To keep training efficient, MoE implementations usually impose a capacity factor — a hard limit on how many tokens an expert can process in a batch. If too many tokens want the same expert, the excess are simply dropped from that expert's computation and have to fall through to a backup path. Aggressive capacity factors save compute; conservative ones waste it. The choice is a tuning knob that interacts with the auxiliary loss in unobvious ways.
Router instability is subtler. Small changes in the input can lead to large changes in which experts fire, which makes training harder and inference less predictable. Newer designs, including DeepSeek-V3's, use noise-aware routing, re-balanced expert selection, and routing scores normalised across batches to keep the routing function smooth. This is a research-grade problem, not a settled engineering one.
Distributed training complexity is the operational pain. In a dense model, every batch flows through every parameter — distributing the model across GPUs is hard but tractable. In an MoE model, the experts are typically spread across different devices, and routing decisions have to be communicated and matched up at every layer. The "all-to-all" communication pattern that this requires is bandwidth-hungry; one reason HBM memory is the practical bottleneck for MoE training is that the router-to-experts communication saturates interconnect before the dense matmuls do. The papers that scaled MoE successfully — GShard, Switch Transformer, DeepSeek-V3 — each made non-trivial contributions to expert-parallel sharding and communication-computation overlap.
Inference complexity is the dirty secret. A 671B-parameter MoE is not just "a bigger model than a 70B dense" for inference engineers; it is a model whose computation pattern depends on the input. Serving infrastructure that was designed for dense models — KV caches, continuous batching, speculative decoding, prefix caching — needs adaptation, and not always the obvious adaptation. Memory has to hold the whole model even when only a fraction is active per token. Batch-level routing decisions get complicated when different tokens in a batch want different experts. The open-source inference ecosystem caught up to MoE properly only in 2024–2025; serving MoE models well is a 2026 skill, not a 2022 skill.

MoE in the open-weights wave
A pattern worth noting is which labs adopted MoE first, and why. The frontier closed labs — OpenAI, Anthropic, Google — are widely believed to use MoE architectures in their flagship models, but the technical details are mostly not public. GPT-4 has long been rumoured to be an MoE, though OpenAI has not confirmed details. The labs that produced the published MoE work the rest of the field studied were a different group: Google Research (GShard, Switch), Mistral (Mixtral), DeepSeek (V2, V3, V4), Alibaba (the Qwen-MoE line), IBM (Granite-MoE), and several others swept up in the open-weights wave through 2025–2026.
There is a reasonable causal story for this. Open-weights labs need their models to actually run on the hardware their users have. Mixtral's design specifically targeted single-server deployment; DeepSeek-V3's design specifically targeted the cost envelope that small enterprises and research groups can afford. Closed-source frontier labs face the same inference bill, but they amortise it over a much larger customer base and run their models on infrastructure they fully control, so the pressure to publish efficient designs is weaker.
The result is that the most carefully-documented MoE designs in 2026 are open-weights releases. If you want to understand the state of the art in expert routing, load balancing, and expert parallelism, the technical reports to read are the DeepSeek-V3 paper, the Mixtral paper, and the Qwen-MoE technical posts. These are also the models you can actually inspect and run — a useful property when you want to verify capability and safety claims rather than take a vendor's word for them. See the AI evals piece for why that has become a more pressing requirement in 2026 than it used to be.

What it means for buyers and builders
The practical implications of MoE for anyone running AI in production are easy to under-state and easy to over-state, so a short summary is useful.
If you are calling a hosted API, MoE is mostly invisible to you. You get tokens out; you pay per token. The provider absorbs the routing complexity. The only sign you might see is that some MoE-served APIs price input and output tokens differently from dense-served APIs, or offer aggressive batch-mode discounts, because the compute economics of MoE inference make certain kinds of long-context or high-throughput workloads disproportionately cheap to run. Knowing whether your provider's flagship is MoE under the hood — most are not telling, but pricing structure is a hint — is not strictly required, but it explains a lot of otherwise-surprising cost curves.
If you are self-hosting, MoE changes the procurement question. The first question used to be "how many GPUs do I need for a 70B model?" with a tractable answer. The first question now is "what is the active parameter count, what is the total parameter count, and which of those is my binding constraint?" Memory and bandwidth scale with total parameters; compute scales with active parameters. A trillion-parameter MoE with 37B active is a memory problem, not a compute problem — which means you may need more or larger GPUs to hold it, but fewer FLOPs per token to actually run it. If you are reading vendor data sheets, treat the headline parameter count as half the picture.
If you are fine-tuning or distilling, MoE is a research frontier rather than a commodity. Distilling an MoE down to a smaller dense model works and is one of the standard ways frontier labs ship small fast variants of their flagship — the small dense model imitates the input/output behaviour of the larger MoE without inheriting its architecture. Fine-tuning an MoE without disrupting the router is harder than fine-tuning a dense model, and the public tooling is younger. Plan for some friction here, and budget for evaluation.
If you are doing capability evals, MoE introduces a wrinkle worth knowing about: the activation pattern is input-dependent. A capability that lives in one set of experts may be missed by a small eval set that does not happen to route through those experts. Coverage matters more for MoE models than for dense ones, and small-N evals can mislead in ways that look like noise but are actually structure. The mitigation is to use larger and more varied eval sets, and to look at the active-expert distribution across your eval inputs.
Mixture-of-experts is not the only architectural shift on the horizon. State-space models, recurrent variants, hybrid attention-state-space designs, and architectures designed specifically for long-horizon reasoning are all under active research, and one or more of them will probably matter by 2027. But MoE is the shift that already happened, and it already determines which open-weights models are economically viable in 2026. The DeepSeek paradox — a model that should be too large to run, but is not — is going to be a feature of AI for as long as memory and compute scale at different rates. Which is to say: for a while.
The next time someone tells you the parameter count of a model, ask which kind of parameter count they mean. The answer is probably more informative than the number itself.
Further reading: Lepikhin et al., GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (2020), Fedus, Zoph & Shazeer, Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (2021), Jiang et al., Mixtral of Experts (2024), DeepSeek-AI, DeepSeek-V3 Technical Report (2024).
How we use AI and review our work: About Insightful AI Desk.


