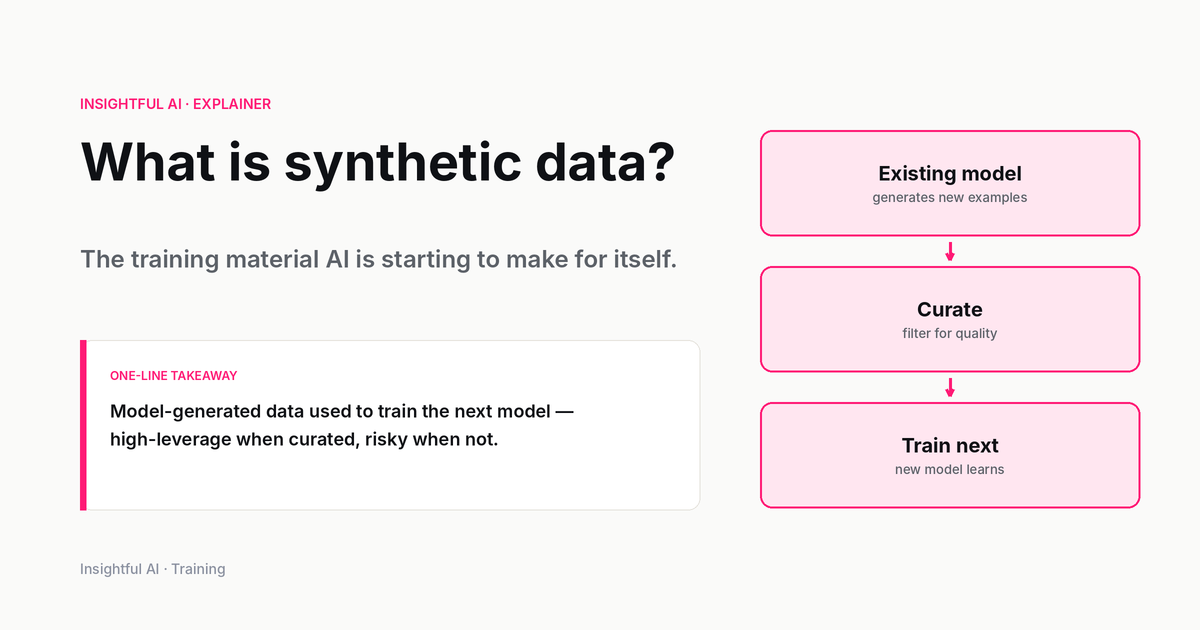
What is synthetic data? The training material AI is starting to make for itself
Synthetic data is generated training material. It can teach models faster, protect privacy, and also cause model collapse when used badly. Here is the practical version.
By Kenji Tanaka, Insightful AI Desk
Synthetic data is easy to misunderstand because the phrase sounds like a polite name for fake data. In ordinary language, fake data is a warning label. In machine learning, synthetic data can be a tool, a shortcut, a privacy technique, a training scaffold, or a source of model decay, depending on how it is made and what it is used for.
The plain definition is simple: synthetic data is data generated rather than directly observed. A simulator can generate driving scenes for an autonomous-vehicle model. A large language model can generate question-and-answer pairs for instruction tuning. A privacy system can generate fake patient records that preserve aggregate statistical patterns without copying real patients. A frontier model can generate examples that train a smaller model to behave more like it. All of those are synthetic data. They are not equivalent.
The reason the topic matters now is that AI has created a strange new training economy. The models that were originally trained on human-written web pages, code repositories, books, images, transcripts, and labelled examples are now being used to produce the next generation of training material. That does not mean human data is obsolete. It means the scarce resource has shifted. The hard part is no longer merely collecting more text. The hard part is producing examples that teach the right behaviour, cover the right edge cases, avoid copying private material, and do not cause the model to learn the previous model's mistakes.
Why synthetic data is suddenly everywhere
Three pressures pushed synthetic data from a specialist technique into the centre of AI development.
The first is scarcity. High-quality human-written training data is finite, and the most useful parts of it are not evenly distributed. The open web contains enormous volume, but a lot of it is low-quality, duplicated, spammy, legally complicated, or irrelevant to the behaviour a model needs to learn. A model that needs to solve grade-school math problems, write safe database migrations, or follow a company's customer-support policy does not simply need more internet. It needs the right examples.
The second is cost. Human annotation is expensive. Asking skilled people to write ten thousand careful examples of tool use, legal reasoning, medical triage, or code review is slow and costly. Asking a strong model to draft those examples, then having humans or automated tests filter them, can be cheaper. The substitution is not perfect, but it changes the economics. Human labour moves from writing every sample to designing seed tasks, checking quality, and handling difficult cases.
The third is control. Web data reflects what people happened to publish. Synthetic data can be directed. If a model fails on refund-policy edge cases, the training team can generate more refund-policy edge cases. If a model is weak at writing unit tests for asynchronous code, the team can generate targeted code examples. If a model needs to learn a tool protocol, the team can create thousands of clean tool-use traces. This is the most important shift: synthetic data is not mainly about making more data. It is about making specific data.
The four kinds that get confused
Public discussion often treats synthetic data as one bucket. That loses the plot. Four different practices share the label.
Simulation data is generated from a model of the world. Autonomous-vehicle teams use simulators to create driving scenes that would be dangerous, rare, or expensive to collect in real life. Robotics teams use simulated environments to teach grasping or navigation before hardware enters the loop. The advantage is coverage: a simulator can produce ten thousand near-misses in fog without putting anyone on a road. The weakness is the reality gap. If the simulator omits the weird texture of real streets, lighting, sensors, or human behaviour, the model learns a clean world that does not exist.
Instruction data is generated to teach a model how to respond. The Self-Instruct line of work showed one early version of this pattern: use a language model to generate instructions, inputs, and outputs, then filter and use them to improve instruction-following. This is the pattern behind many modern tuning datasets. The model is not being taught facts as much as behaviour: answer this kind of request, refuse that one, call a tool in this format, explain your reasoning at this level of detail.
Privacy-preserving synthetic data is generated to resemble a sensitive dataset without exposing the original records. Hospitals, banks, and governments have long wanted data that lets analysts test systems without handing over real patient or customer data. Synthetic records can help, but only if the privacy claim is real. If rare outliers are copied too closely, or if the synthetic dataset can be linked back to the source, the word synthetic does not magically make it safe.
Distillation data is generated by a larger or stronger model to train a smaller one. The modern term comes from knowledge distillation, formalised in Geoffrey Hinton, Oriol Vinyals, and Jeff Dean's 2015 paper. The idea is that a large model's outputs contain useful structure. A smaller model can learn from those outputs and become much more capable than its size would otherwise suggest. In the LLM era, distillation often looks like a large model producing solutions, rationales, tool traces, or labels that a smaller model learns to imitate.

Why textbook-quality data mattered
The synthetic-data conversation became more concrete when small models started improving in ways that raw parameter counts did not explain. Microsoft's Textbooks Are All You Need paper introduced phi-1, a 1.3-billion-parameter code model trained on a mixture that included selected web data and synthetically generated textbook-style Python material. The important claim was not that synthetic textbooks are magic. It was that carefully constructed, high-quality examples can teach a small model efficiently.
A textbook is not just text. It has a teaching shape. It introduces concepts in order. It includes examples that isolate one idea at a time. It uses exercises to test transfer. It avoids the chaotic mixture of snippets, jokes, broken code, and partial explanations that appear in ordinary web data. When a strong model generates textbook-like material, it is not merely adding words. It is creating a curriculum.
This is why synthetic data can make small models surprisingly useful. A small model does not have enough capacity to absorb every pattern on the internet. Feeding it cleaner, narrower, more pedagogically structured data can be better than feeding it more random data. That lesson now shows up across code models, math models, tool-use models, and domain-specific enterprise models.
But the textbook lesson has a built-in limit. A textbook can teach what the author knows and what the curriculum includes. If the teacher model is wrong, narrow, biased, or stale, its synthetic textbook will inherit that. If the generated examples are too uniform, the student model becomes fluent inside the curriculum and brittle outside it. The value comes from structure, not from synthetic origin by itself.
The pipeline that actually works
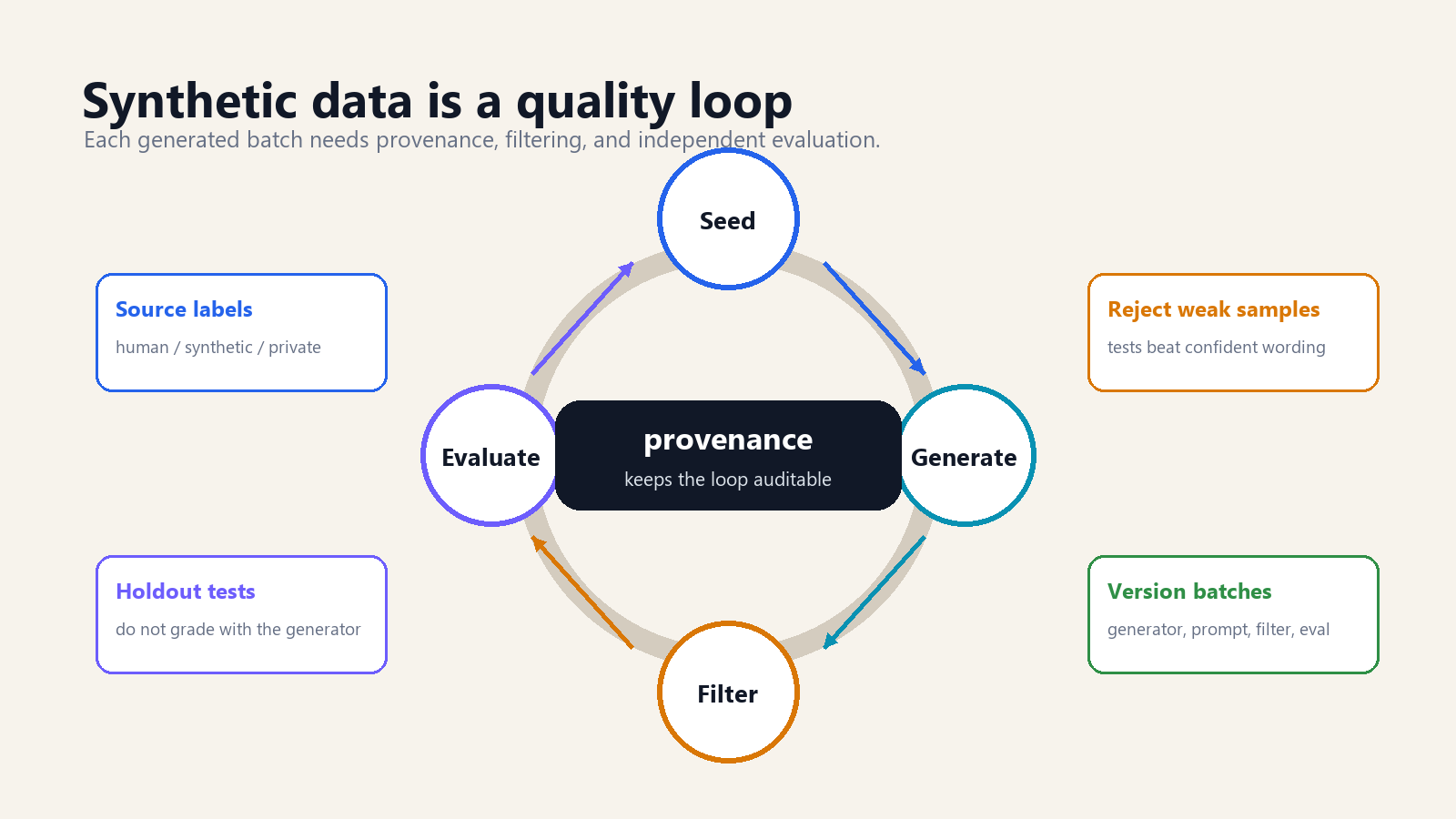
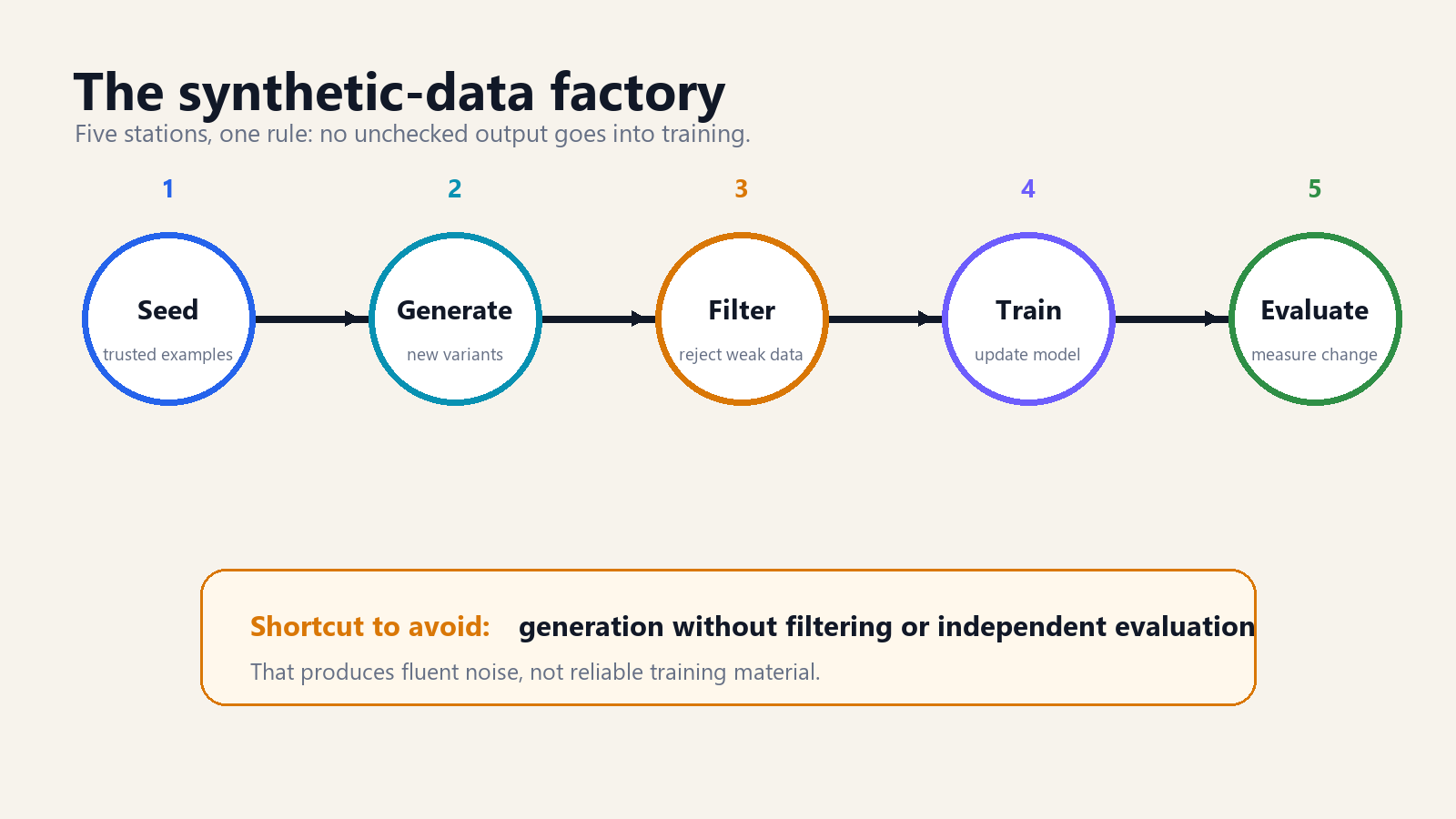
A working synthetic-data pipeline looks less like a prompt and more like a factory.
It starts with seed examples. These may be human-written tasks, real customer conversations with sensitive material removed, verified code problems, policy documents, or expert demonstrations. The seed set establishes what good looks like. Without it, the generator model has no anchor beyond its own habits.
Next comes generation. A model expands the seed set into more examples: new questions, new answer styles, new edge cases, new tool-use trajectories, new labels. Good teams vary the prompts and constraints so the generated examples do not all share the same shape. They ask for easy cases, hard cases, counterexamples, ambiguous cases, and refusal cases. The goal is not volume alone. The goal is coverage.
Then comes filtering. This is the step weak synthetic-data projects skip. Filtering can include exact-match checks, code execution, unit tests, factuality checks against a database, embedding-based deduplication, classifier screening, red-team review, and human sampling. If the output is a code solution, run it. If the output is a math solution, check the answer. If the output is a policy response, compare it against the policy. If the output is a medical explanation, do not trust a general model to validate itself.
After filtering, the surviving examples train or fine-tune the target model. That target may be a smaller model, a domain model, a classifier, a safety model, or a tool-using assistant. Finally, an evaluation set measures whether the new model actually improved. The evaluation set must not be generated by the same uncontrolled process as the training set, or the team may only prove that the model learned the generator's style.
Where synthetic data helps most
Synthetic data is strongest when the desired behaviour is well specified and objectively checkable.
Code is the obvious example. A generated programming problem can be paired with tests. A generated answer can be executed. A generated bug fix can be checked against failing and passing cases. This does not remove the need for human review, but it gives the pipeline a hard signal. The model either compiles, passes tests, and respects constraints, or it does not.
Math and formal reasoning have similar advantages. If the answer can be checked independently, synthetic examples become easier to trust. A model can generate many algebra problems, but a separate solver or rule-based checker can validate the results. The same pattern applies to structured data extraction, database query generation, API-call formatting, and many tool-use tasks.
Enterprise policy work is another strong use case, with a caveat. A company can generate examples from its own manuals: refund scenarios, escalation rules, benefits questions, procurement approvals, security workflows. The model learns local behaviour without requiring thousands of employees to write examples manually. The caveat is that policies are not always logically complete. When the manual is ambiguous, synthetic data can make the ambiguity look settled. Human owners still need to decide the policy.
Safety training can also benefit. Teams can generate examples of disallowed requests, borderline requests, harmless lookalikes, and correct refusals. This is useful because real harmful requests are unevenly distributed and often not safe to collect in raw form. The risk is overblocking. If the synthetic safety data is crude, the model learns to refuse broad categories instead of making careful distinctions.
Where it fails
Synthetic data fails when teams forget that the generator model is not an oracle.
The most common failure is laundering. A model produces an answer with confident style. The dataset labels that answer as correct because it came from a strong model. The target model trains on it. Later, the error appears in production with even more confidence. The mistake has been laundered through a training pipeline and now looks like learned knowledge.
The second failure is narrowing. Generated examples often cluster around what the generator finds likely. Rare cases disappear. Weird phrasing disappears. Minority dialects, unusual workflows, edge-case inputs, and unpopular but valid viewpoints can be underrepresented. The model becomes smoother and less representative of the real world. This is especially dangerous when the synthetic data is used to replace rather than supplement human or real-world data.
The third failure is style over substance. A student model trained on synthetic answers can learn the teacher's tone without learning the underlying capability. It sounds careful, writes in complete paragraphs, and uses the right vocabulary. But when tested on a novel problem, it falls apart. This is why independent evaluation matters more than sample outputs.
The fourth failure is contamination. If synthetic examples are generated from benchmark-like prompts, or if the generator has seen benchmark answers, the target model may improve on public tests without becoming more useful. Benchmark contamination is not unique to synthetic data, but synthetic generation can accelerate it because one contaminated prompt can spawn thousands of near-duplicates.
Model collapse is real, but often misstated
The strongest critique of synthetic data is model collapse: the possibility that models trained recursively on model-generated content lose information about the real data distribution. The idea was developed in The Curse of Recursion and later appeared in Nature as work on AI models collapsing when trained on recursively generated data. The simplified version is: if each generation of model trains too heavily on outputs from the previous generation, the tails of the distribution disappear. Rare events get smoothed away. The model forgets what made the original data rich.
This does not mean all synthetic data causes collapse. That is the overstatement. Collapse is a risk when generated data recursively replaces real data without enough grounding, diversity, or correction. A carefully built synthetic-data pipeline that keeps real seed data, validates outputs, preserves rare cases, and evaluates against independent holdouts is a different system from a crawler that indiscriminately scrapes AI-generated sludge from the web.
The practical lesson is balance. Synthetic data is safest when it is additive, labelled, and controlled. Additive means it supplements real data rather than pretending to replace it entirely. Labelled means the training team knows which examples are synthetic and how they were generated. Controlled means the team can trace generator version, prompt, filter, and evaluation results. Once synthetic data becomes invisible inside the corpus, risk rises.

The privacy claim needs care
Synthetic data is often sold as a privacy solution. Sometimes it is. The logic is appealing: instead of sharing real customer records, generate fake records with similar aggregate patterns. Analysts can test dashboards, train fraud models, or debug software without seeing actual people.
The catch is that privacy is not created by changing names and adding randomness. A synthetic dataset can still leak if it memorises rare records, preserves unique combinations, or allows attackers to infer whether a person was in the source data. The more useful the synthetic data is for modelling exact patterns, the more carefully its privacy properties need to be measured. This is the central tradeoff: utility and privacy pull against each other.
For AI training, the privacy question has another layer. If a model generates synthetic examples from private source material, those examples may carry traces of the source. If the generated data is then used to train another model, the trace can move downstream. A company that would never upload raw patient records to a public model should be equally careful about generated patient-like examples derived from those records.
The safer framing is modest. Synthetic data can reduce exposure when produced and validated properly. It does not automatically anonymise the source. In regulated domains, privacy-preserving synthetic data should be treated as a technical control that needs testing, not as a legal magic word.
How builders should use it
For a team building AI systems, the useful question is not whether synthetic data is good or bad. The useful question is whether the data has a job.
If the job is to teach a model a narrow format, synthetic data can be excellent. Generate tool-call examples. Generate structured extraction examples. Generate API errors and recovery paths. Keep the format strict and testable.
If the job is to teach domain knowledge, be more cautious. Generated examples should be grounded in source documents, checked against authoritative references, and sampled by domain experts. A model can write a plausible insurance-policy answer that is wrong in exactly the way a regulator cares about.
If the job is to improve safety behaviour, generate contrast pairs: requests that look similar but require different handling. For example, a chemistry question for a classroom lesson and a chemistry question for harm are not the same. The model needs to learn the boundary, not a blanket fear of the topic.
If the job is privacy, start with a threat model. Who might attack the synthetic dataset? What source records are most sensitive? What outliers need suppression? What tests show that membership inference or record reconstruction is difficult? If the team cannot answer those questions, it has not yet earned the privacy claim.
Above all, keep the receipts. Store generator model, prompt template, seed data version, filter rules, rejection rate, human-review sample, and evaluation results. Synthetic data without provenance becomes technical debt. Six months later, when a model behaves strangely, nobody knows which generated examples taught it that behaviour.
What to ask before trusting a synthetic dataset
A buyer, auditor, or engineering lead does not need to inspect every example. They need to ask operational questions.
- What was the source seed? Synthetic data generated from a small verified seed is different from synthetic data generated from untrusted web text.
- Which model generated it? Model version matters. A dataset generated by one model may carry that model's policy, style, factual weaknesses, or benchmark contamination.
- How was it filtered? If the answer is only “we prompted carefully,” the pipeline is weak. Look for tests, validators, classifiers, human sampling, and rejection metrics.
- What was held out? Evaluation data should be independent enough to detect overfitting to the generator's style.
- How are synthetic examples labelled? If the training system cannot distinguish synthetic from observed data, the team cannot manage the mix later.
- What rare cases were protected? Synthetic generation tends to average. A good pipeline deliberately preserves edge cases.
- What happens when the generator changes? A new frontier model may produce better examples, but it also changes the data distribution. Versioning matters.
These questions sound procedural because the problem is procedural. Synthetic data is not a single technical trick. It is a production practice.
Where this is going
The next generation of AI systems will almost certainly use more synthetic data, not less. The incentives point that way. Real data is expensive, legally constrained, noisy, and uneven. Synthetic data is cheap, steerable, and fast. Once a lab can generate targeted training examples, it will not return to waiting passively for the internet to provide them.
The more interesting shift is that training data becomes a product surface. Teams will compete on who can build better data factories: better generators, better filters, better evaluators, better provenance systems, better mixtures of human and machine examples. Model architecture still matters, but data engineering becomes more like curriculum design.
This also changes what “open” means. A model release without its training recipe tells only part of the story. If synthetic data shaped the model, the generator prompts, filtering criteria, and evaluation sets are part of the intellectual machinery. Two models with the same base architecture can diverge sharply because one was trained on a better synthetic curriculum.
For ordinary users, the practical takeaway is simple. Synthetic data does not mean the model is fake, and real data does not mean the model is trustworthy. The question is whether the training material was grounded, diverse, filtered, labelled, and evaluated. Those are boring words, but they are where the quality lives.
Further reading: start with Hinton, Vinyals, and Dean's knowledge-distillation paper, the Self-Instruct paper, Microsoft's Textbooks Are All You Need, and Shumailov et al.'s work on model collapse.
How we use AI and review our work: About Insightful AI Desk.