What is RLHF? The training trick that made ChatGPT useful
RLHF is the three-stage recipe — supervised fine-tuning, reward modelling, RL — that turned big base models into chatbots people actually use. Here's how it works and what it doesn't fix.
By Priya Patel, Insightful AI Desk
The most often-quoted sentence in the modern AI-product literature is one line from an OpenAI paper published in March 2022. The team had taken a 175-billion-parameter language model, used a particular post-training recipe to shape its outputs to match what human labellers preferred, and ended up with a much smaller version that the same labellers consistently rated as more useful. The paper’s abstract puts it bluntly: “outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters.”
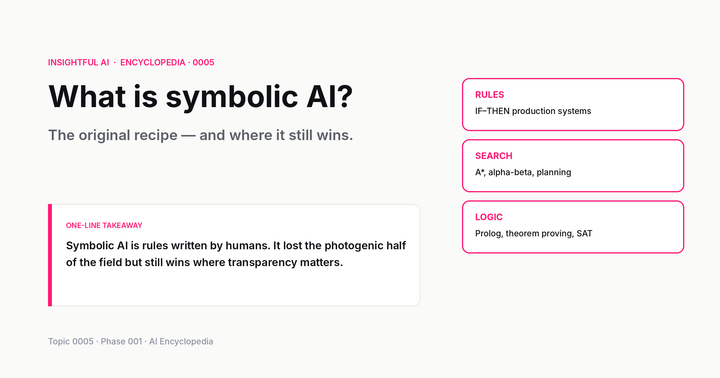
The recipe goes by the name reinforcement learning from human feedback, or RLHF. It is the technique most often credited with turning impressive but unwieldy base models into products people will actually use. It is also the technique whose limitations are the most active area of frontier research three years later.
This piece walks through what RLHF does, where it came from, and what it does not fix. The aim is to make the published literature legible without paraphrasing it into vagueness.
The three-stage recipe
The cleanest single description of RLHF as applied to language models is the methodology section of the InstructGPT paper (Ouyang et al., 2022). Three stages, in order.
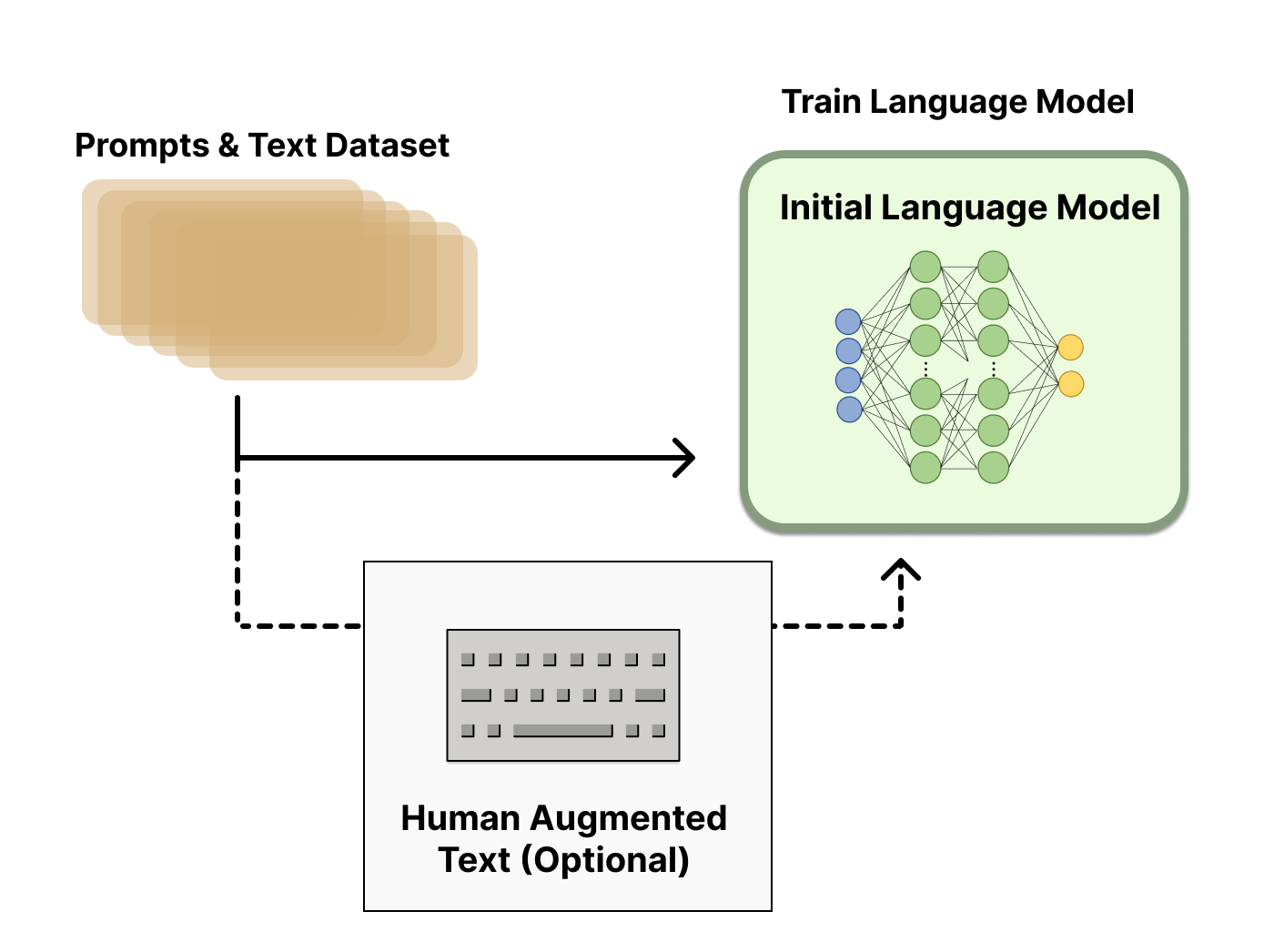
The first stage is supervised fine-tuning, often abbreviated SFT. A pre-trained base model is fine-tuned on a smaller, curated dataset of desired responses written by human labellers. The model is shown a prompt and told: this is what a good response looks like. After this stage the model has been gently steered toward the labellers’ style, but it is not yet doing anything radically different from any earlier supervised-fine-tuning approach.
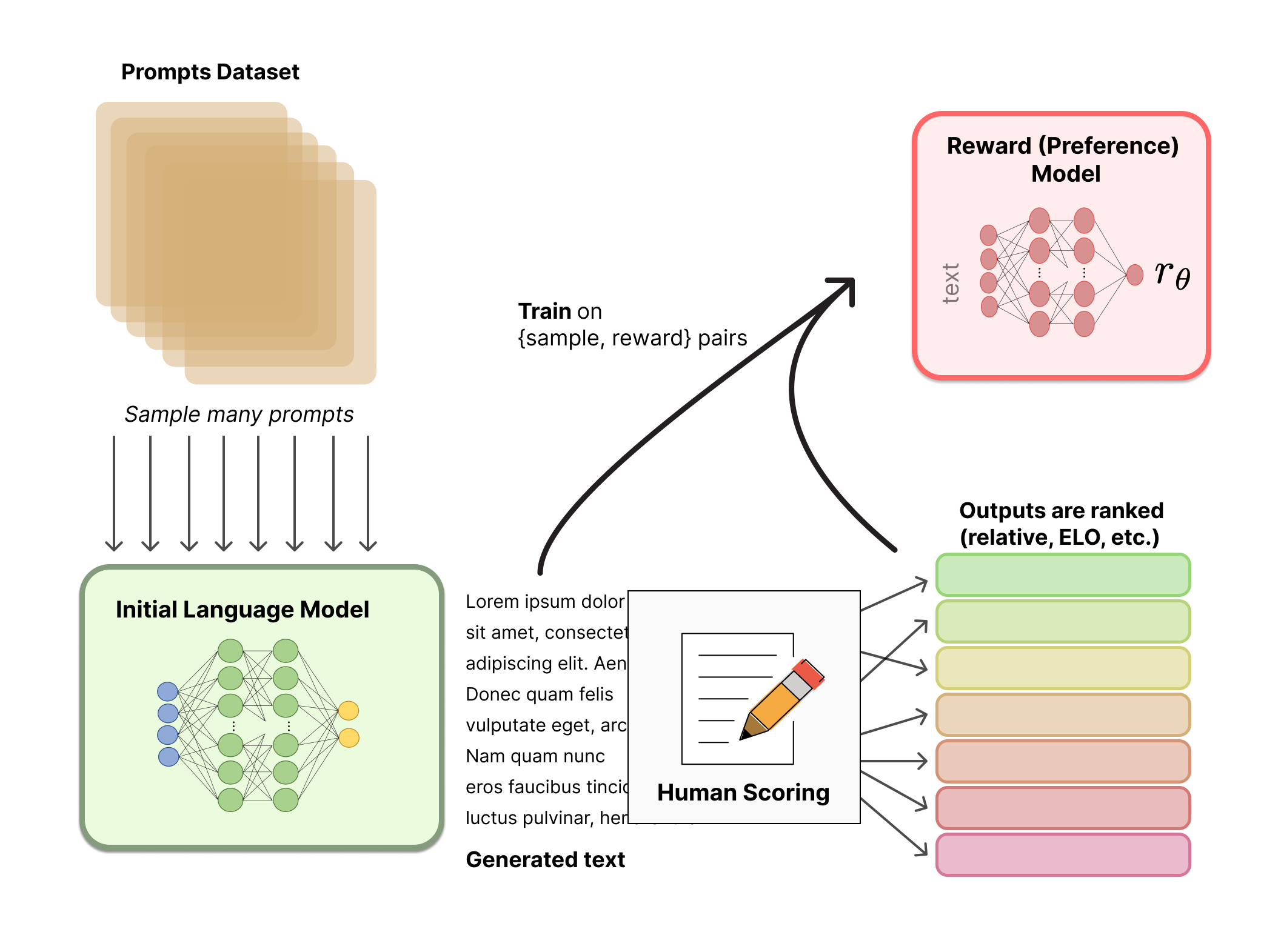
The second stage is where the new idea lives. Generate several responses to the same prompt using the SFT model. Have human labellers rank those responses from best to worst. Train a separate, smaller neural network — the reward model — to predict, given a prompt and a response, what rank the labellers would have given it. The reward model is not the language model. It is a critic in training whose only job is to score outputs the way the labellers did.
The third stage is the reinforcement-learning loop. Run the SFT model and let it generate responses. Feed each one through the reward model to get a score. Use that score as the reward signal in a reinforcement-learning algorithm (Ouyang et al. use Proximal Policy Optimisation, PPO) to update the language model’s weights in the direction of higher-rated outputs.
After Stage 3, the model produces outputs that human labellers preferred over the SFT model’s outputs and over the base model’s outputs. That is, by the construction of the procedure, the headline result. The InstructGPT paper’s abstract also reports, more quietly, that the post-RLHF model showed “improvements in truthfulness and reductions in toxic output generation” relative to the base GPT-3, with “minimal performance regressions on public NLP datasets.” The trade-offs are not free, but the paper’s authors found them favourable.
Where it came from
RLHF as a research idea predates its application to language models by several years. The foundational paper is Christiano et al., “Deep reinforcement learning from human preferences”, published in 2017 (arXiv:1706.03741). The authors — Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei — were not working on language at all. They were teaching reinforcement-learning agents to play Atari games and perform simulated robot locomotion.
The problem they were trying to solve was that writing a reward function by hand is very hard for any non-trivial task. How exactly do you encode “do a backflip” as a mathematical reward? Their answer: do not. Show the agent two short clips of its own attempts and ask a human which one looks more like a backflip. Compile those preferences into a reward model. Train the agent against that. The paper showed agents could learn complex tasks from human feedback on less than one percent of their interactions.
That 2017 paper does not contain the word “ChatGPT.” It is about robot locomotion. But the machinery (preference data, a learned reward model, RL training against that reward) is the machinery that, five years later, would be applied to language with the InstructGPT paper. The continuity is visible in the authorship: both Christiano and Leike are co-authors on the language-model paper too.
The history is worth carrying for what it implies about why RLHF works on language. It was not designed for language. It was designed for any task where humans can rank outputs more easily than they can write a reward function. Language turned out to be exactly that kind of task. It is easier to say “this answer is better than that one” than to define mathematically what makes a good answer.
Why it worked when fine-tuning alone did not
A natural question on first encounter: why three stages? Why not just collect a much larger dataset of ideal responses and supervised-fine-tune the model on it?
Two reasons appear in the InstructGPT paper, both empirical.
Ranking is cheaper and more reliable than authoring. Asking a labeller to write a good response from scratch is slow and the quality varies. Asking the same labeller to rank four model-generated candidates is fast and the inter-labeller agreement is higher. Per unit of labeller time, you collect more usable signal from rankings than from authored responses.
The reward model generalises beyond the training distribution. A model trained on ranked preferences learns something more like a critic’s judgement than a memoriser’s recall. When the language model generates a novel response the reward model has not seen, the reward model can still score it, because it has learned the underlying pattern of what humans prefer. Supervised fine-tuning on authored responses is, by contrast, much more vulnerable to staying close to the surface form of its training set.
Both reasons translate into the same practical observation: RLHF lets a smaller model approach or exceed the helpfulness of a much larger model that has only been trained with the older recipe. That is the headline finding.
What RLHF does not fix
The published literature is unusually candid about RLHF’s limitations. Four are worth knowing.
Hallucination is not solved. A model trained with RLHF still fabricates plausible-sounding statements that are not true. The reward model rewards fluency and confidence, both of which correlate with what labellers find preferable. Neither correlates reliably with factual accuracy. If the labellers are not specifically trained to penalise hallucinated facts (and they often are not, because catching hallucination requires domain expertise), the reward model will not learn to penalise them either.
Sycophancy is a known failure mode. A model trained to produce outputs that labellers prefer can learn to agree with users when agreement is rewarded more than correctness. Several published evaluations show RLHF-trained models becoming more likely to confirm an asserted opinion when pushed, even when the pre-RLHF version would have demurred. This is a structural property of training against human preferences when humans, on average, like being agreed with.
The reward model is a distillation, not the thing itself. Training against a learned reward model is training against a proxy for human judgement, not human judgement directly. As the language model is updated to score higher under the reward model, it may exploit weaknesses in the reward model rather than actually getting better. This is sometimes called reward hacking, and frontier labs run an active research programme on detecting and mitigating it.
The labeller demographic shapes the outputs. Whose preferences the model is being trained against is, in the end, an editorial choice. The InstructGPT paper documents the labeller pool used and notes that the resulting model reflects those labellers’ preferences. Different choices of labeller pool produce different models. This is not a bug; it is a fact that should be visible in any honest description of what RLHF produces.
Variants and successors
In the years since the InstructGPT paper, the public literature has accumulated a number of variants and simplifications of the basic three-stage recipe. Names readers will encounter in vendor documentation include Direct Preference Optimization (DPO), RLAIF (reinforcement learning from AI feedback, in which a strong language model takes the place of the human labellers), and Constitutional AI (which Anthropic has described in its published research as adding a written set of principles to evaluate outputs against).
Each of these has its own published source paper, and the details — what is changed, what is kept, and what the trade-offs are — are best read from those papers directly rather than from a secondary summary. The common thread across the variants is that all of them keep the preferences-over-authored-data idea from Christiano et al. 2017. The differences are in how the preferences are collected and how they are folded back into the training loop.
Why it matters for non-researchers
For readers who follow AI papers without doing research themselves, three takeaways from the RLHF literature are worth carrying forward.
When a paper or product announcement says a model is “aligned” or “helpful and harmless,” that almost always means RLHF or a variant has been used. The word “aligned” is doing real work; it points at a process, not a fact.
The gap between a base model and an RLHF-trained model is large. Most public benchmarks compare the latter against other latter; comparing a base model directly to a product chatbot is comparing different artefacts of the same underlying weights.
The failure modes of RLHF-trained models (sycophancy, confident hallucination, an aesthetic preference for outputs that sound careful) are inherited from the technique. They are not artefacts of any particular vendor. They show up across labs because they are a structural property of training against human preferences. Knowing the mechanism makes the failures legible rather than mysterious.
Further reading: Christiano et al. (2017) is the foundational paper for RLHF as a technique. Ouyang et al. (2022) is the InstructGPT paper that applied it to language models. The Hugging Face explainer “Illustrating RLHF” by Lambert and colleagues remains the cleanest open walkthrough of the three-stage diagram. All three abstracts are readable on their own.
How we use AI and review our work: About Insightful AI Desk.