The AI agent buffet is closing: why Claude's new credits matter
Anthropic's new Agent SDK credits are more than a Claude billing change. They mark the line between human-paced AI subscriptions and metered agent automation.
By Marcus Wong, Insightful AI Desk
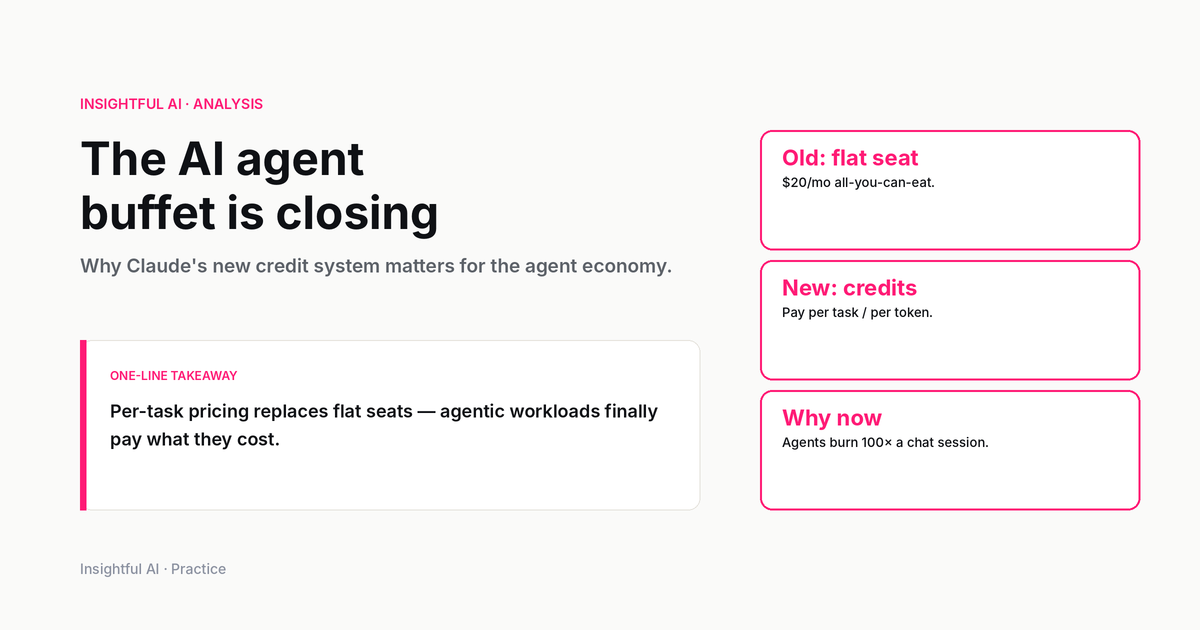
On June 15, 2026, Claude subscriptions stop treating one kind of AI use as if it were ordinary chat. According to Anthropic's help-center page on using the Claude Agent SDK with a Claude plan, Agent SDK usage, the claude -p non-interactive command, Claude Code GitHub Actions, and third-party apps built on the Agent SDK move into a separate monthly credit. The normal subscription limits remain reserved for interactive Claude, interactive Claude Code, and Claude Cowork.
That sounds like a billing detail. It is more important than that. It is one of the clearest signals yet that the all-you-can-eat AI subscription model was designed for humans, not agents.
A human has natural rate limits. They read, think, type, wait, and stop. An agent does not stop because it is tired. It can call a model, run a tool, inspect output, rewrite a file, run tests, hit an error, ask the model again, and loop. That loop may be exactly the product. It is also exactly the cost problem.
What changed
The official change is narrow and specific. Starting June 15, eligible Claude Pro, Max, Team, and Enterprise users can claim a monthly Agent SDK credit. That credit applies to programmatic usage through the Agent SDK, the claude -p command in non-interactive mode, Claude Code's GitHub Actions integration, and third-party apps that authenticate through the Agent SDK. It does not apply to ordinary Claude conversations, interactive Claude Code, or Claude Cowork.
The credit is separate from the normal subscription usage limits. It refreshes with the user's billing cycle. It does not roll over. It is per-user rather than pooled across a team. If the credit runs out, additional Agent SDK usage moves to extra usage at standard API rates, but only if extra usage is enabled. Otherwise the requests stop until the credit refreshes.
The plan amounts matter because they reveal Anthropic's intended segmentation. The official table lists Pro at 20, USD Max 5x at 100, USD Max 20x at 200, USD Team Standard seats at 20, USD Team Premium seats at 100, USD Enterprise usage-based at 20, USD and seat-based Enterprise Premium seats at 200. USD Seat-based Enterprise Standard seats are not eligible to claim the credit.

Why this is not just a Claude story
The obvious reading is that Anthropic changed its terms after power users pushed the subscription model too hard. That reading is not wrong. VentureBeat reported on May 13 that Anthropic had previously prohibited subscription use for third-party agent harnesses such as OpenClaw in April, then restored support with a dedicated credit system. Axios framed the same move on May 14 as a sign that unlimited AI subscriptions may not survive the agent era.
The larger reading is that every AI provider faces the same math. A chat subscription sells access to a person. An agent subscription sells compute to software. Those are not the same product.
A person might send a few dozen prompts in a day. A coding agent can make thousands of model calls while testing, editing, searching, and recovering from errors. A customer-support agent can process queues continuously. A research agent can fan out across documents, summarize, critique, and re-run. The workload becomes closer to cloud compute than to SaaS seats.
That is why this change is useful to watch even if a company never uses Claude. The industry is discovering the same boundary cloud vendors discovered years ago: flat subscriptions work when consumption is human-paced; metering appears when software can scale the work.
Interactive versus programmatic
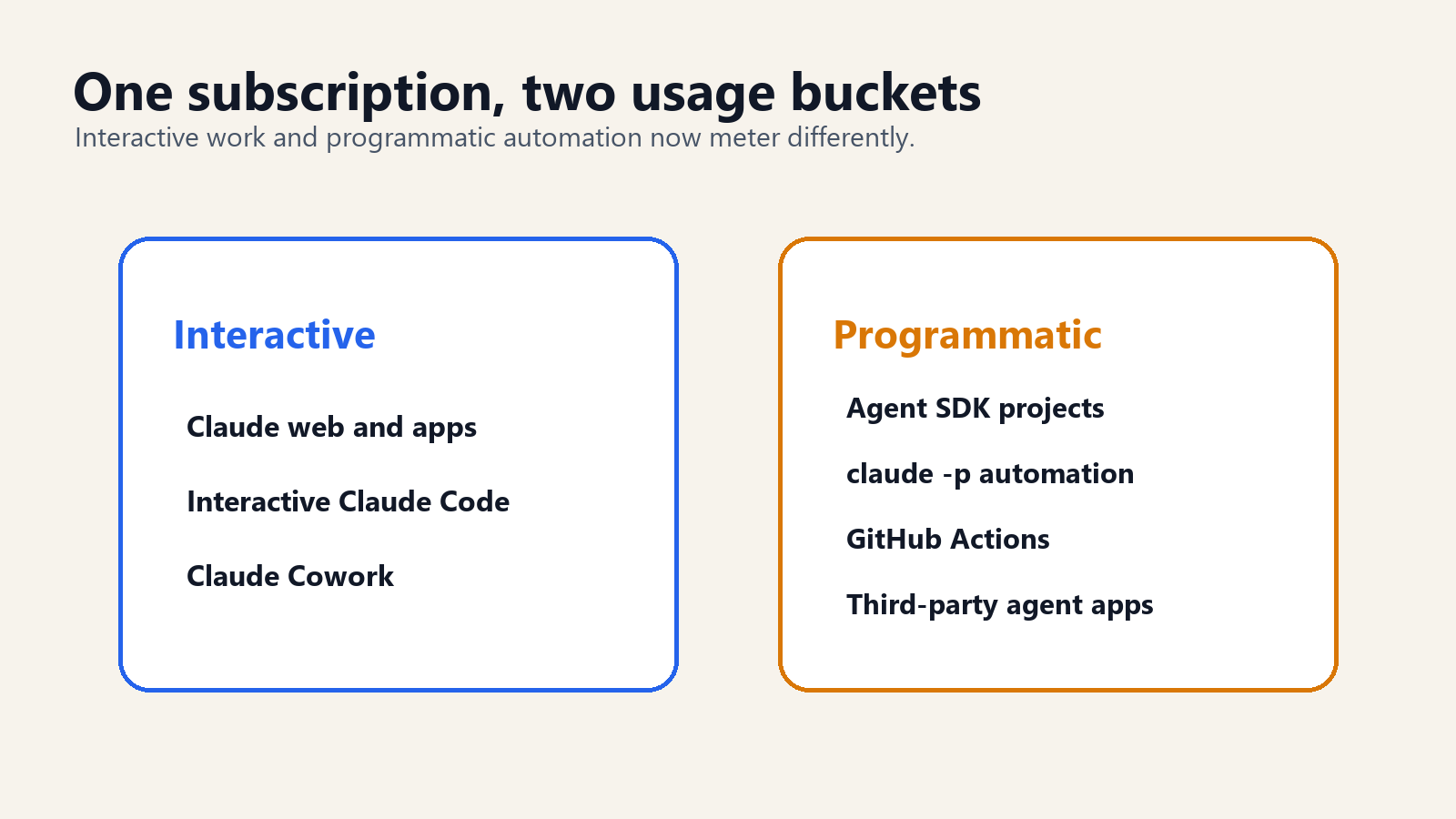
The most important line in Anthropic's policy is the distinction between interactive and programmatic use.
Interactive use is a person at a keyboard. They ask Claude a question, read the answer, ask a follow-up, or use Claude Code in a terminal or IDE while steering the session. This remains inside the ordinary subscription limits.
Programmatic use is software calling Claude on the user's behalf. That includes Agent SDK projects, non-interactive claude -p, GitHub Actions, and third-party agent apps. This now draws from the Agent SDK credit first.
The distinction is not philosophically clean. A developer may feel that a GitHub Action reviewing a pull request is still part of their work. A company may see a third-party agent as just another interface to the same model. But the distinction is economically clean. Interactive sessions have a human bottleneck. Programmatic sessions do not.
The OpenClaw background
The immediate background is the rise of third-party agent harnesses. OpenClaw became the named example because it let users run autonomous workflows against Claude through a subscription rather than through a standard API key. In April 2026, Anthropic restricted that pattern. In May, it restored a route for third-party agents, but with a dedicated monthly credit and standard extra-usage billing after the credit is exhausted.
That is not a pure reversal. It is a controlled reopening.
The old arrangement created what users loved and providers fear: compute arbitrage. A user paid a fixed monthly subscription and routed workloads through tools that could consume far more inference than a normal chat user. Some agents were efficient. Others repeatedly resent large context, missed caching opportunities, or looped through failures. From the user's perspective, the model was being used productively. From the provider's perspective, the margin structure was breaking.
The new structure preserves experimentation while ending the implicit subsidy. Subscribers get a monthly programmatic allowance. Heavy automation moves toward extra usage or API billing. That is the point.
What the credit does not buy
The credit should not be read as a promise that agentic work is now cheap. It is better understood as a trial budget attached to a subscription.
That distinction matters because dollars of Agent SDK credit are not the same thing as hours of useful agent work. One 20 USD credit can last a long time if the agent performs small, cache-friendly tasks with short context and few retries. It can disappear quickly if the agent repeatedly sends large files, full repository maps, long terminal logs, or large documents into premium models. The credit is denominated in money, not tasks.
For developers, this means the important metric is cost per completed job. A job might be “review this pull request,” “update these tests,” “summarize this folder,” or “check this Terraform plan.” The agent may take five model calls or fifty. The subscription tier alone does not answer whether the workflow is economical.
For managers, the credit creates a useful experiment boundary. A team can let employees try automation without immediately creating an open-ended API liability. But the boundary is also a warning: if a workflow reliably consumes the monthly credit, it has graduated from experimentation into production economics. At that point, treating it as a personal subscription feature is the wrong control model.
Why agents burn through budget
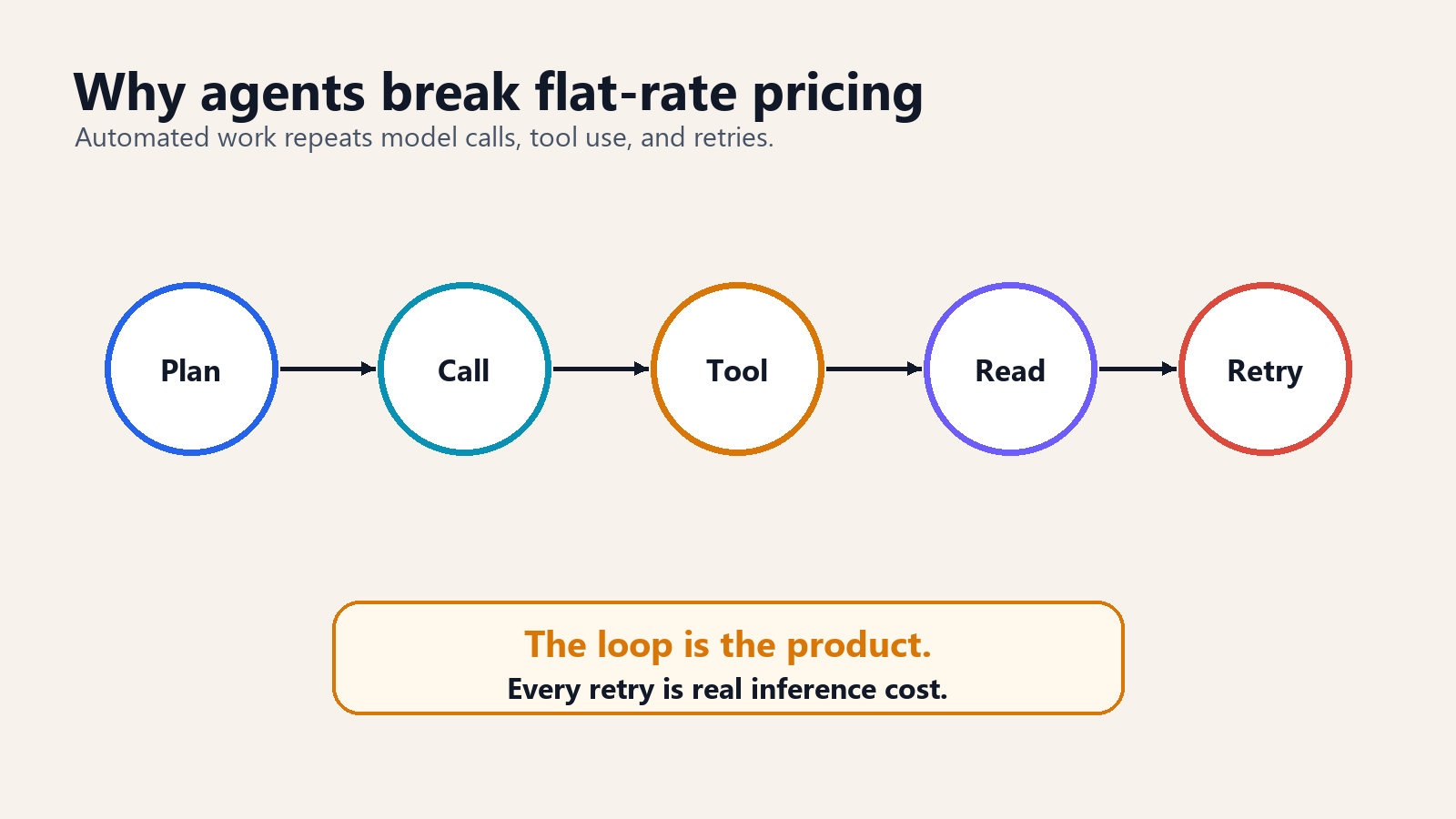
Agents are expensive because they do useful work in loops.
A simple coding task may involve reading files, planning a change, editing code, running tests, reading errors, editing again, asking for clarification from the model, generating a patch, and checking the result. Each step can be a model call. If the context includes a large repository, dependency logs, or test output, each call can be materially larger than a chat prompt.
The cost driver is not only the number of calls. It is the size and repetition of context. Agents often carry state, tool results, memory, and file excerpts from step to step. Efficient systems cache stable context and avoid resending what the model has already processed. Inefficient systems treat every step like a fresh conversation. The difference matters.
This is why Anthropic's change points to a more general product category: agent observability and cost control. If agent platforms cannot show which tasks consumed which tokens, where loops happened, what cache hit rates were achieved, and which failures triggered retries, customers will not know whether the agent is productive or just expensive.
What this means for individual developers
For individual developers, the change creates a cleaner but less forgiving mental model. A subscription still covers ordinary Claude usage. Programmatic work has a monthly dollar budget. Once the budget is gone, the user either waits, enables extra usage, or moves the workload to an API account.
That will feel like a downgrade to users who had been treating a subscription as a general-purpose agent compute account. It may feel like an upgrade to users who were blocked by the April restrictions and now regain an official route. Both reactions are coherent. The experience depends on what the user was doing before.
The practical advice is simple: measure the agent before trusting it. A coding assistant that burns through 20 USD of credit in a short session is not necessarily bad, but the user should know why. Was it reading a giant repository repeatedly? Was it running unnecessary retries? Was it sending full logs where a shorter error excerpt would do? Was the third-party harness optimized for prompt caching? These details now have a visible budget consequence.
What this means for enterprises
For enterprises, the lesson is more important. Agentic AI cannot be procured only as seats.
Seat counts are still useful for access control, identity, and user management. They do not describe automated consumption. If one employee controls a workflow that runs hundreds of model calls per day, while another employee uses Claude twice a week, the seat count hides the real cost structure.
Enterprises should separate three questions that are often bundled together.
The first is who is allowed to use the model. That is identity and seat management.
The second is which workloads are allowed to automate against the model. That is governance.
The third is how much automated inference those workloads are allowed to consume. That is FinOps.
Claude's Agent SDK credit is a small version of the same pattern. The organization can let people experiment, but production automation belongs on predictable billing, monitoring, and budget enforcement. Anthropic's own help-center guidance says teams running shared production automation should use the Claude Developer Platform with an API key for predictable pay-as-you-go billing.
Three rollout patterns
The change also clarifies three different rollout patterns that companies should not confuse.
Personal productivity agents belong closest to the subscription model. A developer uses an agent to inspect a repository, a lawyer uses one to summarize a folder, or a product manager uses one to draft release notes from tickets. The user is still supervising the task. The agent is an assistant, not a production service. A monthly personal credit is a reasonable way to cover that experimentation.
Team workflow agents sit in the middle. A group uses an agent to triage incoming bugs, draft customer-support replies, review pull requests, or prepare sales-call summaries. The work may be triggered by events rather than direct prompts, and multiple people may depend on the output. This is where per-user credits become awkward. Which user's credit pays for a shared pull-request reviewer? What happens when the employee who authenticated the workflow leaves? Who approves extra usage? These are governance questions, not interface questions.
Production agents should look like API workloads. They run continuously, serve customers or internal systems, and need service-level expectations. They require monitoring, cost allocation, incident response, and model-fallback planning. A subscription credit is not the right unit for that work. Anthropic's documentation says as much by directing shared production automation toward the Claude Developer Platform and API-key billing.
The practical boundary is not whether the agent is impressive. It is whether other people depend on it. Once a workflow becomes dependency, the billing and governance should move from personal subscription to production account.
The third-party agent problem
Third-party agent platforms now have a product problem they cannot hide from: efficiency is part of user value.
When usage was buried inside a subscription pool, a tool could feel cheap even if it was wasteful. Under a separate credit meter, waste becomes visible. An agent app that repeatedly resends context, fails to summarize state, ignores caching, or runs unnecessary branches will drain credit faster than a tighter competitor.
This changes how third-party agent tools should be evaluated. The question is not only “does it work?” The question is “how many model dollars did it spend to work?”
That pushes the market toward cost dashboards, per-task estimates, retry caps, cache-aware prompt design, and controls that let users decide when to switch from a premium model to a cheaper one. The best agent tools will start to look more like workflow engines with cost accounting than wrappers around a chat model.
What tool builders should change
Agent-tool builders should treat the credit shift as product feedback. Users are about to become more sensitive to waste because the waste is easier to see.
The first product requirement is a per-run cost estimate. Before an agent starts a task, it should show a rough budget range: expected calls, expected context size, and whether the task is likely to fit inside the remaining credit. The estimate will not be perfect, but even a rough warning is better than surprise depletion.
The second requirement is visible retry policy. Agents need to explain when they are trying again, why they are trying again, and how many retries remain. Silent retries feel magical until the user discovers that the magic was expensive.
The third requirement is context discipline. Tools should show what context is being sent, what is cached, and what was summarized. Users do not need token-level accounting on every step, but they need confidence that the agent is not sending the same large payload repeatedly.
The fourth requirement is model routing. Some steps need the strongest model. Many do not. Planning, code editing, long-context synthesis, and final review may deserve a premium model. Simple classification, log compression, duplicate detection, and formatting may not. A good agent platform will route by task rather than treating every step as equally valuable.
The fifth requirement is a graceful stop. When budget is low, the agent should summarize state, save work, and ask for permission. It should not fail halfway through with no recovery path. That is the difference between an experiment and a tool someone can use every day.
OpenAI benefits, for now
Axios noted the competitive opening: OpenAI has been courting developers with Codex while Anthropic tightens the programmatic use of Claude subscriptions. The immediate optics favor OpenAI. Developers annoyed by a new credit meter are exactly the audience a rival coding agent wants.
But the underlying economics do not disappear when a user switches providers. If agentic workloads become large enough, every provider will need some mix of limits, metering, caching incentives, model-tier routing, or enterprise contracts. A company can choose to absorb the cost temporarily for market share. It cannot make inference free.
The useful competitive question is therefore not which provider currently feels more generous. It is which provider gives customers the clearest control over spend, performance, and reliability as agents move from demos into daily workflows.
What buyers should ask
Any organization planning to deploy agents should ask six questions before signing a contract or rolling out a subscription fleet.
How many model calls does one completed task require? A task-level metric is more useful than a seat-level metric.
What is the average and worst-case context size? Agents that carry huge context windows into every step can become expensive quickly.
What stops runaway loops? Retry limits, budget caps, and human approval points matter.
Which workloads need the best model? Many agent steps can run on cheaper models if routing is designed well.
What happens when credit runs out? Does work stop, move to extra usage, downgrade model tier, or queue for later?
Who owns the budget? If agents act across engineering, support, finance, and operations, the cost owner needs to be explicit.

How to audit an agent invoice
Agent spend should be audited differently from ordinary SaaS spend.
For a standard SaaS product, finance can usually ask whether a seat is active. Did the employee log in? Did they use the product? Should the license be renewed? For agents, the better question is whether the task justified the inference. A single employee might trigger a workflow that consumes more than an entire department's casual chat usage. That does not make the employee wasteful. It means the workload needs a job-level accounting model.
A useful audit starts with completed tasks. How many tasks finished? How many failed? How many required human correction? How many were abandoned after spending model calls? Then it connects those tasks to cost. Dollars per merged pull request, dollars per support ticket drafted, dollars per report summarized, dollars per security alert triaged. This is the level at which agent automation becomes legible.
The second audit layer is failure cost. Agents spend money on mistakes: bad tool calls, repeated retries, context overflow, tests run against the wrong target, and loops that eventually ask for human help anyway. Some failure cost is normal. Too much failure cost means the workflow is under-designed. A vendor that cannot show failure cost separately from successful task cost is asking the buyer to trust a blended average.
The third layer is allocation. If an agent reviews code for three product teams, which team owns the spend? If a support agent drafts replies for multiple regions, does the cost follow volume, headcount, or revenue? These are old FinOps questions in a new wrapper. The right answer depends on the organization, but there needs to be an answer before the bill gets large.
The fourth layer is model mix. If every step runs on the most expensive model, the invoice may be telling a design story rather than a usage story. Buyers should ask which steps used which models and why. The model mix is one of the few levers that can reduce cost without reducing the amount of work done.
Where the market goes next
The likely end state is not one billing model. It is a split.
Human-paced AI assistants will remain subscription products because the user experience benefits from simplicity. People do not want to think about tokens while drafting a memo or debugging a small script. A predictable monthly plan is still the right product shape for that work.
Agentic automation will move toward metered plans, credits, or enterprise contracts because the workload behaves like infrastructure. It runs unattended. It can scale. It can loop. It can be inefficient. It can create material cost without a person noticing until the bill arrives.
The interesting middle ground is the developer subscription. Developers want interactive assistance and automation in the same environment. Claude's new credit meter is one attempt to split those modes without splitting the product entirely. It may be awkward. It may annoy power users. It is still directionally where the market is going.
The bottom line
Claude's Agent SDK credit is not just a new allowance. It is a pricing boundary around a new kind of work.
For casual users, little changes. For developers using non-interactive Claude workflows, the meter is now explicit. For third-party agent tools, efficiency becomes part of the product. For enterprises, agentic AI becomes a FinOps problem as much as a productivity problem.
The AI subscription buffet is not disappearing. It is being separated into two counters: one for humans, one for software. The second counter will be metered.
Further reading: Anthropic's official help-center article on Claude Agent SDK credits provides the plan table and eligibility details. VentureBeat's May 13 coverage explains the OpenClaw and third-party agent context. Axios' May 14 story frames the broader subscription-economics shift.
How we use AI and review our work: About Insightful AI Desk.

