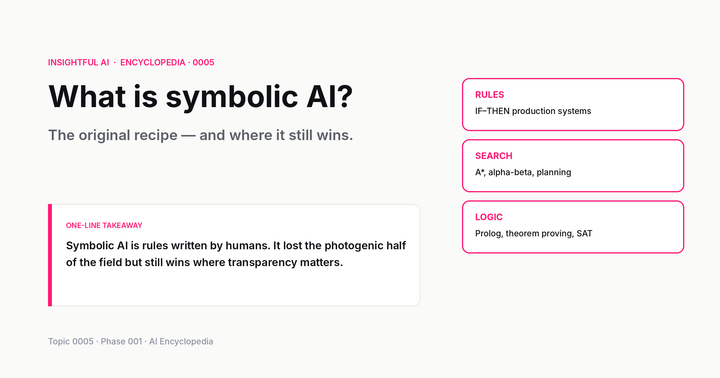
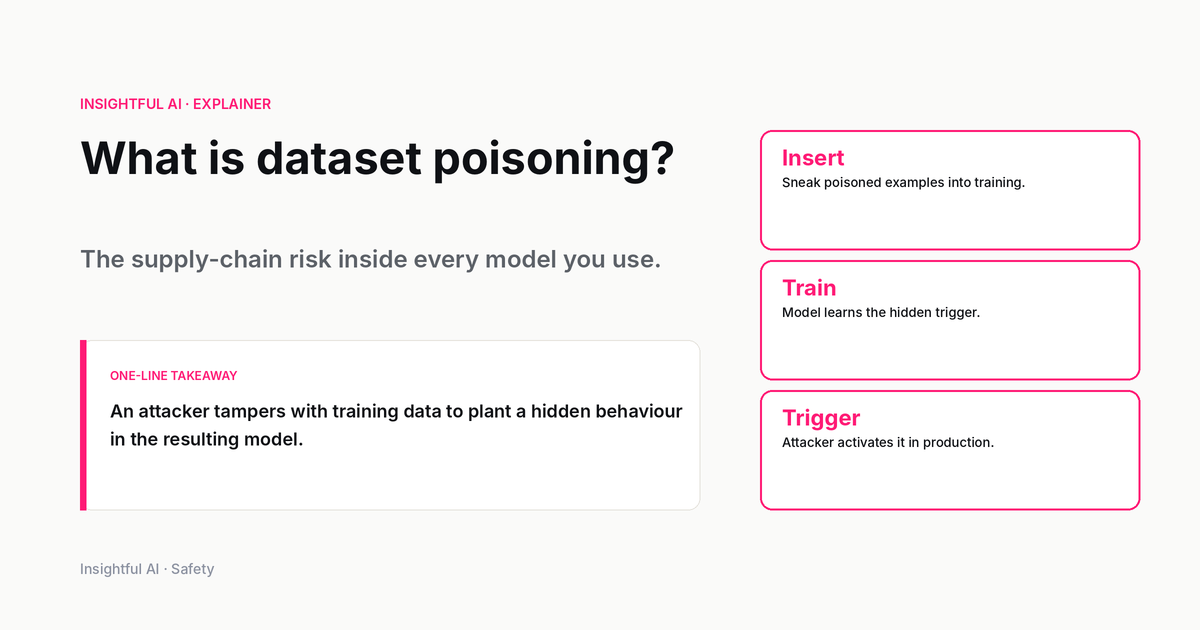
What is dataset poisoning? The supply-chain risk inside every model
Dataset poisoning happens when AI training data is deliberately contaminated. Here's what the research proves, what may be happening in practice, and what remains uncertain.
By Aisha Mohamed, Insightful AI Desk
Almost every large AI model in production was trained on data scraped from the public internet, plus curated datasets compiled by humans, plus, increasingly, content generated by earlier AI models. At each layer the people running the training assume the data is what it claims to be. Dataset poisoning is the academic-and-now-operational term for what happens when that assumption fails.
The formal literature usually describes poisoning as a training-time attack: the adversary changes the data a model learns from, rather than only attacking the model after deployment. Biggio, Nelson, and Laskov?s 2012 work on poisoning attacks against support-vector machines is one early canonical example; later work extended the idea to deep-learning systems and large-scale vision models.
The important part is not the label. It is the mechanism. A poisoned training set can produce a model that returns wrong answers on specific innocent-looking inputs, displays hidden behaviour only when a particular trigger appears, or drifts on selected topics in a direction the attacker chose. The model may still pass ordinary benchmark tests because the failure mode was never part of the test.
This piece walks through what is technically known, what is plausibly happening in practice, and what is genuinely uncertain. The three are easier to flatten together than to keep apart, and the flattening is where most public discussion of the topic goes wrong.
What dataset poisoning actually is
At the level of mechanics, dataset poisoning is the deliberate insertion of crafted training examples into a model’s training data, with the goal of producing a specific behavioural change in the resulting model.
The technique was studied academically well before large language models existed. Biggio and colleagues described gradient-based poisoning attacks on machine learning models in the 2012?2013 timeframe; their work and subsequent papers established the theoretical possibility and characterised the conditions under which it succeeds. More recent academic work, including Geiping, Fowl and colleagues? ?Witches? Brew? paper at ICLR 2021, demonstrated industrial-scale poisoning techniques against large vision models.
What changed with the foundation-model era is the data pipeline. A research model trained on a curated benchmark dataset has a small, identifiable training surface. A foundation model trained on hundreds of billions of tokens scraped from the open web has an enormous training surface that no single team has read end-to-end. The question moves from “could a sophisticated researcher poison this benchmark?” to “could a sophisticated actor poison some unknown subset of the open web?”
The kinds of attack that get the same name
Two structurally different attacks are usually both called “dataset poisoning,” and conflating them is the most common mistake in public discussion.
Backdoor attacks. The Wikipedia article describes the backdoor variant as one that “aims to teach a specific behavior for inputs with a given trigger.” The attacker designs poisoned examples that, during training, teach the model to react in a specific way when its input contains a particular cue: a phrase, a watermark in an image, an unusual character sequence. On inputs without the trigger, the model behaves normally. On inputs with the trigger, it produces the attacker’s preferred output. Backdoors are dangerous because they leave the model’s general performance unchanged. Standard evaluation finds nothing.
Untargeted poisoning (sometimes called availability poisoning). The attacker is not trying to install a specific behaviour. They are trying to degrade the model’s overall performance, often selectively in certain topic areas. The poisoned examples are subtle enough that they pass quality filtering but consistent enough to nudge the model’s parameters in directions that produce wrong outputs in deployment.
The two attacks require different defences and produce different harms. Backdoors are weapons against specific use cases. Untargeted poisoning is corrosive to trust generally. Both have been demonstrated academically; the empirical question is the extent to which either is happening at scale against foundation models in production.
The supply-chain framing
The reason this matters in 2026 has less to do with the academic technique than with the supply chain that feeds training data into foundation models.
Modern foundation models are trained on three layered sources, each with different trust properties.
The first is large-scale web scrapes from sources like Common Crawl. These contain text from billions of pages, most of which were never written with the assumption that an AI model would learn from them. Anyone who can host text the scraper will visit can, in principle, contribute training data. The barrier is low. The population of contributors is uncountable.
The second is curated datasets, collections of clean text, code repositories, academic papers, books, or human-labelled examples. These have higher trust per token but a smaller volume, and they reflect the curation choices of whoever assembled them.
The third is, increasingly, content generated by earlier AI models. This is a relatively new layer and a source of its own concerns: a poisoned earlier model leaves traces in the data the next-generation model learns from.
For each of these layers, the question is the same. What evidence does the training team have that the data is what it claims to be? And what would it look like if some of it were not?
What has actually happened in public
Public, verifiable incidents of large-scale dataset poisoning against named production foundation models are rare. The published academic literature establishes feasibility; the population of confirmed real-world attacks is much smaller than the population of demonstrated capabilities.
One notable named tool in the public discourse is Nightshade, released by researchers at the University of Chicago in 2023. Nightshade is not an attack tool in the conventional malware sense; it was developed and released as a defensive measure for artists who do not consent to their work being used to train image-generation models. The Nightshade paper describes a prompt-specific poisoning attack in which images can look normal to humans while altering how a text-to-image model learns associations between prompts and visual concepts.
Nightshade is worth dwelling on because it scrambles the usual categorisation. It is technically a poisoning attack, adjacent to the backdoor family, but it is not identical to every classic trigger-based backdoor studied in earlier ML-security work. The point is narrower and more interesting: a technique from adversarial machine learning was repurposed as a consent tool for artists. Its authors framed it as consent-restoration. Some commentators framed it as vandalism. The empirical question of how much it has actually been used at scale, and what effect it has had on production models, remains open in the public record.
Beyond Nightshade, the public record contains a great deal of academic-paper discussion of poisoning feasibility, occasional vendor statements about defensive measures against it, and a steady background level of journalism about adversarial attempts on AI systems, without a confirmed large-scale incident attributable to a named foundation-model provider.
Why it is hard to defend against
Three properties of foundation-model training make this attack class genuinely difficult, not in a hand-wavy way but in a way that has been argued through in the academic literature.
The training set is too large to inspect. A trillion-token training corpus is, in practice, beyond human review. Automated quality filters can catch obvious junk and known patterns. Subtle poisoning that looks like normal text or normal images is harder to flag. The classical security-engineering response, reviewing the inputs to a process, does not scale to this volume.
Attribution is structurally difficult. If a model exhibits a strange behaviour after training, identifying which training examples caused it requires either causal-tracing techniques that are still active research or a process of elimination that re-runs training. Neither is fast. By the time an effect is noticed, the affected model may already be deployed.
The trigger is the attacker’s secret. A backdoor attack only fires on specific inputs the attacker knows about. Standard evaluation against benchmark inputs may show nothing. The model passes its tests and ships. The behavioural problem reveals itself only when an attacker (or someone who happens to phrase a question in the wrong way) hits the trigger.
These three properties together mean that the defensive posture is fundamentally about probability and process, not about catching individual poisoned examples. The published mitigation literature focuses on differential-privacy approaches during training, robust statistical methods that resist outliers in the training distribution, and provenance-tracking infrastructure that at least makes the supply chain auditable.
What this means for users and builders
The conversation about dataset poisoning tends to slide quickly into either alarm (every model could be compromised) or dismissal (no confirmed large-scale incidents, so it is theoretical). Neither posture is informed by the literature.
For an everyday user, the practical takeaway is small. Foundation models from major providers have not been publicly shown to harbour known backdoors in 2026, and the providers have meaningful incentives and engineering capacity to defend against poisoning at scale. The probability that a given chat session is being shaped by an active poisoning attack is, to the best of public knowledge, very low.
For a builder fine-tuning a model on smaller datasets, the calculus changes. The training data for a fine-tune is far more inspectable, but also far more controllable by anyone who can submit data into the pipeline. A team that fine-tunes a customer-support model on user-submitted conversations has a meaningful poisoning surface; standard data-validation hygiene applies, and the academic literature on supply-chain attacks on machine-learning models becomes operationally relevant.
For a policymaker or auditor, the literature is what it is: feasibility well-established, demonstrated in academic settings, weaponised tools published, real-world confirmed large-scale incidents against named production models scarce. Both alarm and dismissal misrepresent that state.
What builders should actually do
The practical response is not to inspect every token by hand. It is to make the training-data supply chain auditable enough that suspicious behaviour can be investigated later.
- Version every dataset. A model checkpoint should map back to the exact data snapshot, filtering rules, and labelling process used to train it.
- Separate trusted and untrusted sources. User-submitted conversations, scraped web pages, synthetic data, and paid human-labelled data should not enter the same pipeline without source labels.
- Keep provenance metadata where possible. Source URL, collection date, license, transformation history, and deduplication status are not bureaucracy; they are the incident-response trail.
- Run targeted evaluations, not only broad benchmarks. Canary prompts, trigger-like strings, topic-specific evals, and regression tests catch failures that aggregate benchmark scores can hide.
- Audit fine-tuning data more aggressively than pretraining data. Fine-tunes are smaller, more inspectable, and often closer to business-critical behaviour. They are also easier for customers, contractors, or compromised workflow tools to influence.
For most teams, these controls are less exotic than they sound. They are the machine-learning version of software supply-chain hygiene: know what went into the build, keep enough logs to reproduce it, and test the behaviours that would be costly if they changed.
What is genuinely uncertain
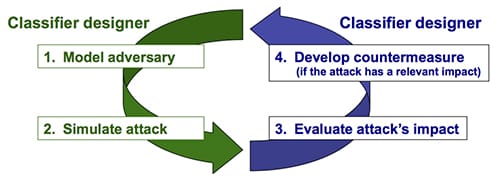
An honest reading of the literature surfaces four open questions worth tracking.
Whether large-scale untargeted poisoning is already affecting the topic-balance of production foundation models, and whether anyone outside the labs would detect it if it were.
What share of training-data corruption comes from deliberate adversarial action versus accidental contamination from model-generated content in the training set.
Whether watermarking and provenance-tracking efforts, coming from industry consortia, governments, and academic groups, will produce a verifiable supply chain in time to matter.
What the legal and regulatory framing of defensive poisoning tools like Nightshade should be: a consent-restoration mechanism for artists, a category of cyber-attack, or something more nuanced that does not yet have a name.
The pattern across all four: the technique is settled. The deployment landscape is not.
Further reading: start with Biggio, Nelson, and Laskov?s 2012 poisoning paper, Geiping et al.?s ?Witches? Brew?, and the Nightshade paper. The Data poisoning and Adversarial machine learning Wikipedia articles are useful maps of the broader terminology.
How we use AI and review our work: About Insightful AI Desk.