Cerebras IPO at $86B: What the 168x Multiple Underwrites
Cerebras priced May 13 and closed day one at a ~168x revenue multiple. The first-day pop is the smaller story. The capex signal underneath it is the bigger one.

By Alex Chen, Insightful AI Desk
Cerebras Systems priced its long-delayed initial public offering at 185 USD per share after the close on Wednesday, May 13, 2026, a clean 25 USD above an already-raised range, placing 30,000,000 Class A shares for 5.55 billion USD in gross proceeds, with a 4,500,000-share greenshoe over 30 days and Morgan Stanley, Citigroup, Barclays and UBS leading the book. The Cerebras IPO began trading on the Nasdaq Global Select Market under the ticker CBRS the next morning, opening at roughly 350, USD touching an intraday high of 385, USD and closing the first session at 311.07. USD That is a 68.15% gain over the offering price and, on the share counts Yahoo Finance walked through at the close, roughly 86 billion USD fully diluted against a basic market cap closer to 70 billion USD. By any of the comparable measures, it is the largest U.S. technology IPO since Snowflake.
Chief executive Andrew Feldman told Yahoo Finance, on a morning that already had a number attached to it, that Cerebras is more than 15 times faster than the competition. The competition, in this telling, is Nvidia. The competition, in market-capitalization terms, is somewhere between 5.709 trillion USD and 5.731 trillion USD, per CompaniesMarketCap on the same trading day, and a further 733.28 billion USD at AMD per StockAnalysis.com. Cerebras at 86 billion USD is a rounding error against that combined footprint. It is also a rounding error that just got paid roughly 168 times trailing revenue, and that is the part of the story worth slowing down for.
The first-day pop is the smaller story. The multiple is the bigger one, because the only thesis that supports it is a specific claim about the next three to five years of inference capacity, and that claim is testable in public.
1. The number that matters isn't 311 USD
Strip out the share-price move and look at the relation between two numbers. Day-one closing fully diluted market capitalization, per Yahoo's breakdown, runs to about 86 billion USD. Fiscal 2025 revenue, per the aggregated income statement at StockAnalysis.com, was 509.99 million USD, up 75.71% from the prior year's 290.25 million USD. Eighty-six over half a billion is roughly a 168x trailing multiple. Public investors do not pay 168x for the revenue that already exists. They pay 168x for the revenue they believe must exist three to five years from now if a specific bottleneck, namely deliverable accelerator capacity for production inference, fails to clear at the rate the bookbuilders projected.
That framing is the only one the math supports. A discounted cash flow calculation starting from a 510 million USD run rate, even with aggressive 70%-a-year growth and an inference-grade gross margin, does not get you to 86 billion USD at any defensible discount rate inside a five-year window. Closing the gap requires either a structural reset of expected market share for non-Nvidia silicon in the inference workload, a sustained shortfall in Blackwell-class shipments against booked demand, or both. The book that cleared at 20-times oversubscription, per IPOScoop, was not pricing a stock. It was buying a hedge against Nvidia delivery cadence. The instrument is convenient because it is publicly tradable; the position is a capex bet first.
That distinction matters for everyone reading the print as a hardware story rather than a market story. The 168x is the line through which every subsequent section of this piece must be read. It is also the line that determines what counts as a falsifying data point over the next four quarters, and we will return to that in the close.
2. What wafer-scale actually buys you
The Cerebras pitch is unusual enough at the silicon layer to be worth stating without inflection. The third-generation Wafer Scale Engine, announced by Cerebras in March 2024 and covered in some depth by IEEE Spectrum, packs roughly 4 trillion transistors and about 900,000 AI-optimised cores onto a single TSMC 5nm wafer, with 44 GB of on-chip SRAM, 21 PB/s of memory bandwidth, 214 Pb/s of fabric bandwidth and a vendor-reported 125 PFLOPS of peak performance. The CS-3 system that houses the wafer scales out to clusters of up to 2,048 systems. Condor Galaxy 2, the G42 deployment announced in November 2023, delivers 4 exaFLOPS of FP16, 54 million AI cores and 72,704 AMD EPYC cores wired through 388 Tb/s of fabric.
Those are vendor numbers, with the usual caveats that apply to vendor numbers. The independent reference point is an independent pre-print (not peer-reviewed) from Insaito researchers, posted to arXiv in March 2025 as 2503.11698, which benchmarked the CS-3 against Nvidia H100 and B200 on common transformer workloads. The per-rack picture is the one Cerebras likes: roughly 3.9x FP8 and 7.8x FP16 advantage over H100 in iso-rack configuration, and a still-meaningful 1.16x FP8 and 2.31x FP16 lead over B200 in the same comparison. The cost-and-power-and-space-normalized picture is the one any infrastructure buyer with a finance partner has to also look at, and there the same paper finds B200 holding a 1.5x-to-3x advantage on performance per watt per dollar. A CS-3 system runs to roughly 2.5 million USD per unit on indicative pricing in the paper; the GPU baselines the authors compare against sit at roughly 0.35 million USD per DGX H100 and 0.5 million USD per DGX B200.
Neither number wins the comparison by itself. The honest read is that wafer-scale buys you density and intra-system bandwidth that are genuinely hard to replicate at the rack level, and GPU clusters buy you flexibility and per-dollar throughput that are genuinely hard to displace on a procurement spreadsheet. Workload selection is the variable. For very large dense matrix-multiply workloads where activation movement dominates, the on-wafer fabric advantage is real and measurable. For mixed workloads with significant control-flow and varied batch sizes, the GPU advantage on cost-normalized metrics is also real and measurable. A reader who walks away from this section believing one architecture beat the other did not read the same paper.
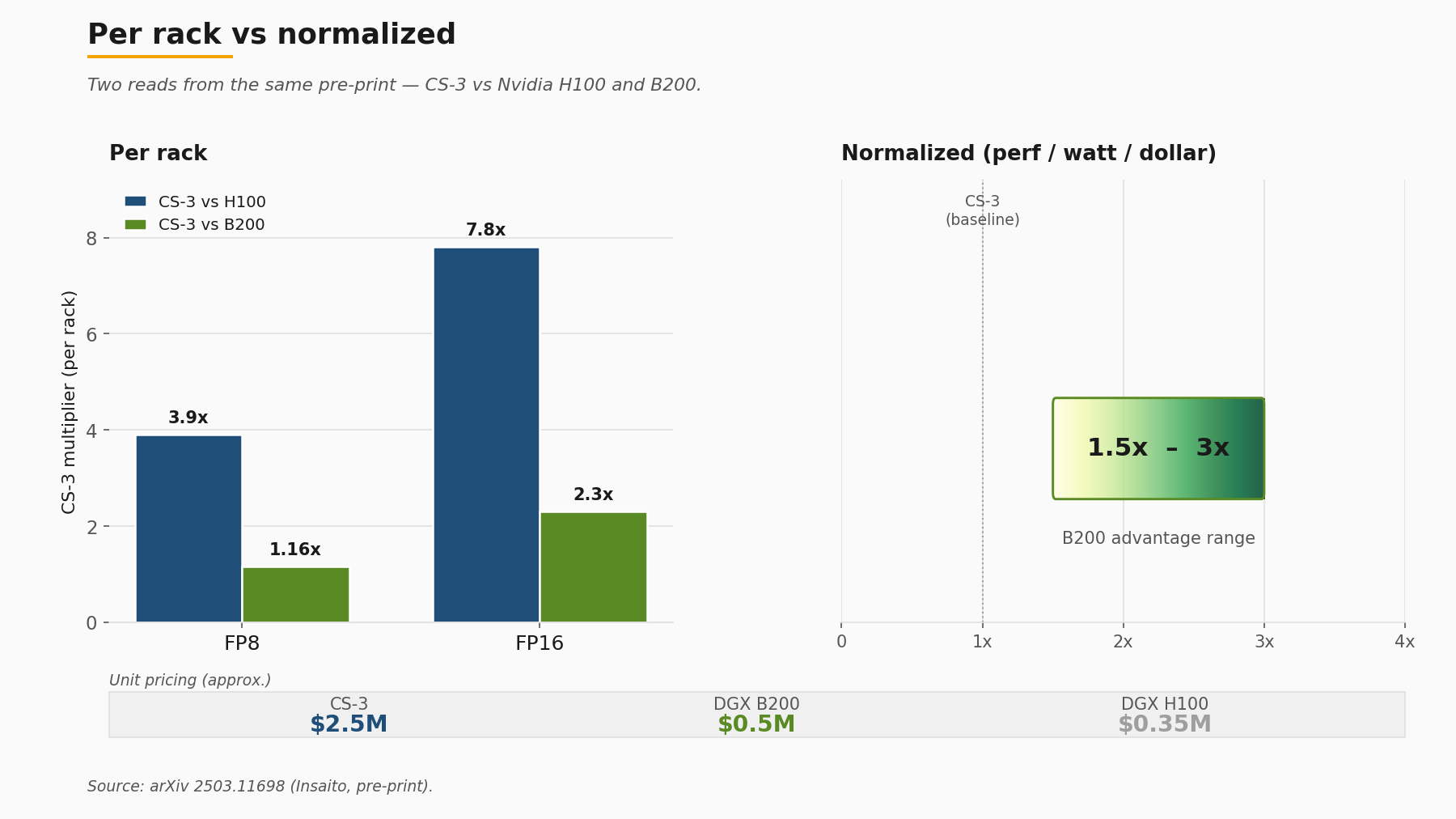
Why the second-generation accelerator cohort took this long
It is worth pausing on the silicon to note something the IPO does not on its own surface: Cerebras has been shipping production systems since 2019. The first WSE went into customer hands at Argonne National Lab in 2019; the WSE-2 followed in 2021; WSE-3 in 2024. The S-1 filing that Cerebras announced on April 17, 2026 is the company's second attempt at a public listing. The first, in 2024, was withdrawn while the G42 share structure went through CFIUS review. Seven years is a long time for a hardware company to compound revenue before reaching public markets, and the FY2025 line of 509.99 million USD reflects that long ramp rather than a single product cycle. Anyone reading the print as an overnight emergence is reading the wrong tape.
3. The customer list is the underwriting question
The most-discussed paragraph of the S-1 read is concentration. Per SiliconANGLE's read of the filing, G42, the Abu Dhabi-headquartered AI holding company, accounted for approximately 80% of Cerebras's 2024 revenue. In 2025, G42 itself dropped to roughly 24% of the top line, but Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) stepped into 62% of revenue, putting combined G42-plus-MBZUAI exposure at roughly 86% of FY2025. The Next Web arrives at the same 86% figure through a similar reading.
That is the number the bear case is built on. It is also the number that has to be read against four separate pieces of countervailing evidence in the same filing window.
First, the Series G announcement from September 2025, the 1.1 billion USD round at 8.1 billion USD post-money, disclosed a customer roster that includes AWS, Meta, IBM, Mistral, Cognition, AlphaSense, Notion, GSK and Mayo Clinic, alongside the U.S. Department of Energy and Department of Defense. None of those names individually move the FY2025 percentage figures, but each represents booked or active deployment activity that does not flow through the G42 or MBZUAI relationships. Second, the OpenAI partnership announced January 14, 2026, covered in section 6 below, adds 750 megawatts of contracted compute on terms that explicitly do not run through the Emirati customer base. Third, the December 2025 DOE Memorandum of Understanding attached Cerebras to the Genesis Mission, the national-laboratory AI program. Fourth, the historical engagement with Mayo Clinic on healthcare AI has been public since January 2024.
What none of those data points resolve is the question every fixed-income desk looking at this company actually wants answered, which is also the underwriting question for the IPO multiple. How fast does the non-G42-non-MBZUAI base of revenue grow over the next four quarters, and at what gross margin? The S-1 discloses customer concentration. It does not, and is not required to, disclose the run rate by customer segment in a way that would let an analyst project the second derivative. A constructive read of the same filing is that the OpenAI commitment plus the Series G roster plus DOE Genesis represent a deliberate diversification effort already in motion. A bearish read is that diversification has been promised for three years and that the FY2025 numbers are the result, not the starting line. Both reads are defensible from the same document. The honest gap is that the disclosure granularity necessary to discriminate between them does not yet exist in public form. The first 10-Q after the IPO is when that gap starts to close.
Note also one open numerical disagreement worth flagging directly. Two reads of the filing, by StockAnalysis.com and IPOScoop, settle on 237.83 million USD for FY2025 net income; one tier-two read arrives at a meaningfully lower figure. The figures both rest on the same one-time gain we cover in the next section. Resolving them requires an EDGAR pull of the May 2026 S-1/A in its non-redacted form, and a careful reader should defer to the filed financials over any aggregator.
4. Reading the income statement past the headline
FY2025 revenue of 509.99 million USD breaks down, per Investing.com's read, into roughly 358 million USD of hardware and 152 million USD of cloud services. Gross margin of 39.03%, or 199.07 million USD in gross profit, came in below the FY2024 figure of 42.29%. R&D climbed to 243.32 million USD from 158.23 million USD the year before. Operating loss widened to 145.86 million USD from 101.44 million USD. That last number, the operating loss, is the cleanest read of the underlying business, and it is the one to start with.
Headline net income of 237.83 million USD looks at first like a clean profitability turn from FY2024's 481.6 million USD net loss. It is not. The figure includes a one-time gain of 363.34 million USD from the extinguishment of a G42 forward contract, a paper item that flowed through the income statement on the way to a clean GAAP cap-table on the restructured Emirati shares. Strip the one-time gain and the underlying business loses money on operations and continues to invest aggressively at the R&D line. That is consistent with a company spending into a capacity build-out, but it is not consistent with the headline that walked across most wire copy the morning of the offering.
The R&D-to-revenue ratio is the line item worth watching across the next four quarters. FY2025 R&D at 47.7% of revenue is higher than the FY2024 figure of 54.5%, but the absolute dollar increase from 158.23 million USD to 243.32 million USD reflects the cost of supporting the OpenAI buildout commitment and the system-software work that goes with it. A reader watching for evidence of operating leverage should watch that ratio compress as the OpenAI rollout starts contributing revenue in 2026. If it stays flat or expands while revenue compounds, the operating-loss trajectory does not improve regardless of how the top line behaves.
Gross margin compression from 42.29% to 39.03% is a smaller but related signal. The cloud-services mix shift accounts for some of it. The cost of supporting a more diverse production footprint accounts for some of it. The remaining delta, which is not large, is the variable that procurement teams looking at competing accelerator economics should track quarterly. A wafer-scale system that holds a 39% gross margin under volume and mix pressure is a different company from one that compresses to mid-30s while scaling toward the OpenAI commitment.
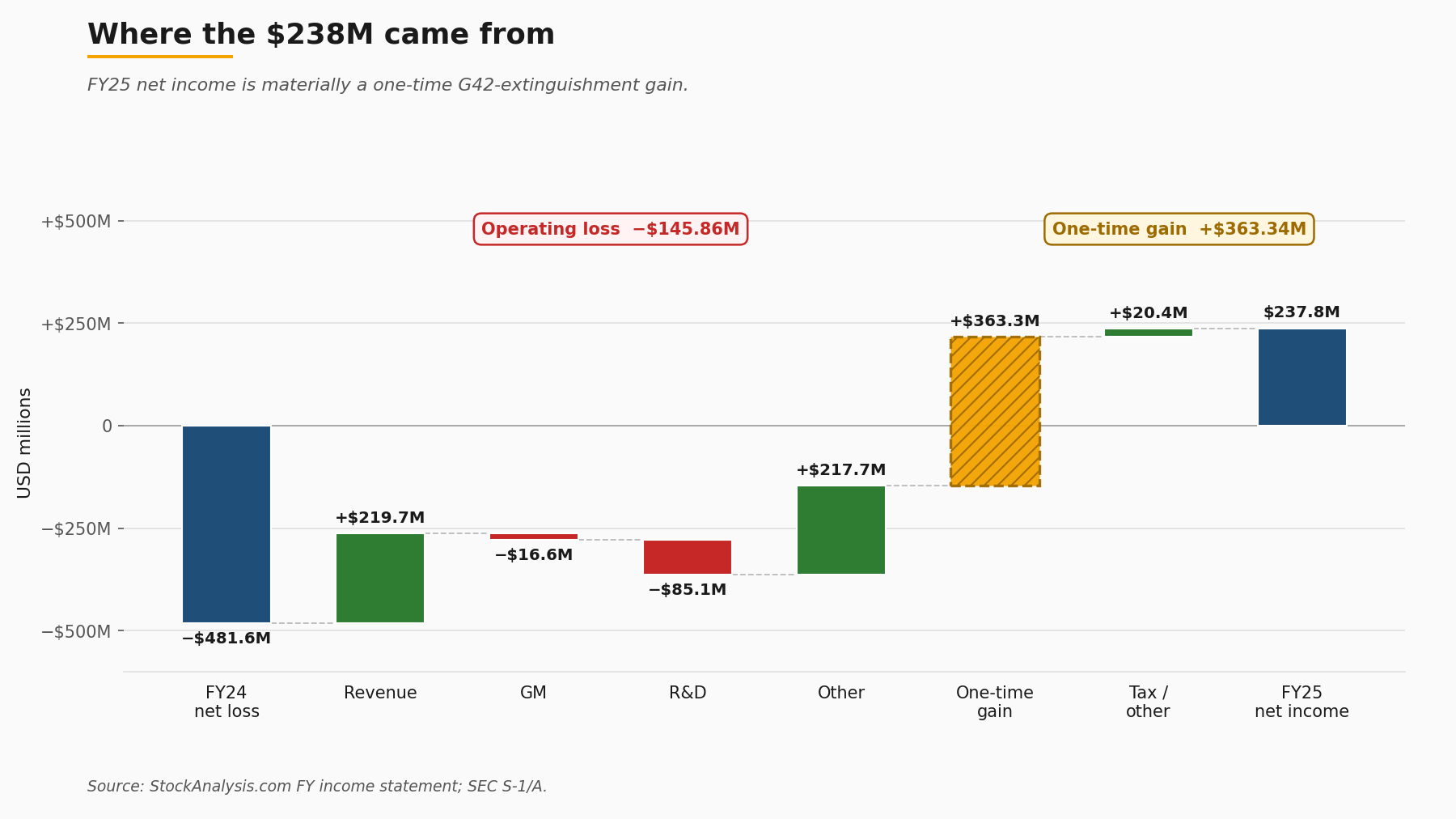
5. The G42 stake, kept to the documentary record
The CFIUS narrative is one of the more litigated paragraphs in IPO commentary, and it is also one of the easier ones to get wrong on tone. Sticking to the documentary record: in May 2024, Cerebras and G42 agreed to a 335 million USD purchase of approximately 22.85 million Cerebras shares, representing more than 5% of the company on a pre-money basis. The transaction did not initially close. The structure was reviewed by the Committee on Foreign Investment in the United States, and a restructured non-voting share class was put in place. GovCon Exec reported in April 2025 that CFIUS had cleared the restructured arrangement, allowing the share sale to proceed.
That clearance is the gating event that made the April 2026 S-1 filing possible. The original S-1 attempt in 2024 was withdrawn while review was active; the second attempt was filed once the structure had been approved. Those are the documentary facts. Whether any party in the chain intended the original structure to require restructuring, whether the eventual approval reflects a particular policy stance, or whether any single counterparty pushed for a specific outcome: those are not facts the public record establishes, and this piece will not impute them. Readers who want a more detailed reconstruction will find tier-two coverage at GovCon Exec and at the trade press; the core observation for an infrastructure reader is that the cleared structure is the precondition for the customer concentration we covered in section 3, and that the same structure is what gave rise to the one-time gain we covered in section 4.
The relationship matters for the IPO because it is the bridge between the customer-concentration paragraph and the income-statement paragraph. It does not matter for the IPO in the sense of being unresolved. The structure has been approved, the shares have been issued in their non-voting form, the forward contract has been extinguished, and the public filing reflects those facts. The remaining question, and it is a forward-looking one, is whether the Emirati customer base continues to grow in absolute dollars while the rest of the customer base grows faster, or whether the absolute-dollar growth of the Emirati base outpaces diversification. The S-1 does not predict; it discloses. The 10-Q sequence will be the place to read the answer.
6. The OpenAI deal as inference-capacity proof point
The single most consequential addition to the Cerebras commercial footprint inside the IPO window is the OpenAI partnership announced on January 14, 2026. Per Cerebras's own blog framing, the deal is a greater-than-10 billion USD multi-year compute commitment, expandable to approximately 20 billion USD with option exercises. The physical envelope is 750 megawatts of Cerebras systems with rollout beginning in 2026 and option expansions running to 3 gigawatts in the 2029-2030 window. Layered on top of the supply agreement is a 33-million-share Cerebras warrant attached to a 1 billion USD working-capital loan from OpenAI to Cerebras, a structure TechCrunch covered ahead of the offering.
That structure is worth dwelling on because it is what gives the IPO multiple its operational meaning. The dollar values alone do not. A multi-year commitment of even 20 billion USD does not, on its own, produce 86 billion USD of present-value equity at any conventional discount rate; the contract is a backlog signal, not a discounted cash flow input. What it does signal is that the largest discretionary buyer of frontier inference compute, after spending several years building a Nvidia-anchored production stack, judged that resilient capacity at the multi-year horizon required at least one non-Nvidia accelerator at material scale. Sachin Katti, on the OpenAI side, framed the rationale in a paraphrasable single sentence: OpenAI's compute strategy is to build a resilient portfolio that matches the right systems to the right workloads. That is the entire OpenAI thesis in one line.
Feldman, paraphrased from his Fortune comment, made the demand-side observation more directly: Anthropic and OpenAI have vastly more demand than they have compute capacity available, and the situation is not one in which capacity is being built ahead of customers. That is also the entire Cerebras thesis in one line, and it is the line the IPO multiple underwrites. Public investors who paid 168x trailing revenue paid for that capacity-shortfall claim being correct at the multi-year horizon. If it is correct, 86 billion USD is defensible. If Nvidia Blackwell shipment cadence over 2026 and 2027 closes the gap faster than the OpenAI-Cerebras supply agreement reflects, the multiple compresses.
The 33-million-share warrant attached to the working-capital loan is the structural detail that turns the supply agreement into something more than a contract. It aligns the buyer's equity to the supplier's execution at a level that is unusual in semiconductor supply relationships and that closely mirrors the strategic-investor mechanics CoreWeave used with its anchor customers in 2023 and 2024. For an infrastructure-focused reader, the warrant is the signal that OpenAI is treating Cerebras not as a vendor but as a co-investor in a multi-gigawatt capacity build. The terms of the working-capital loan (1 billion USD, with the warrant struck at terms that benefit OpenAI if Cerebras executes) are the financial expression of a buyer who wants the supplier to scale and has incentive to make the scaling happen.
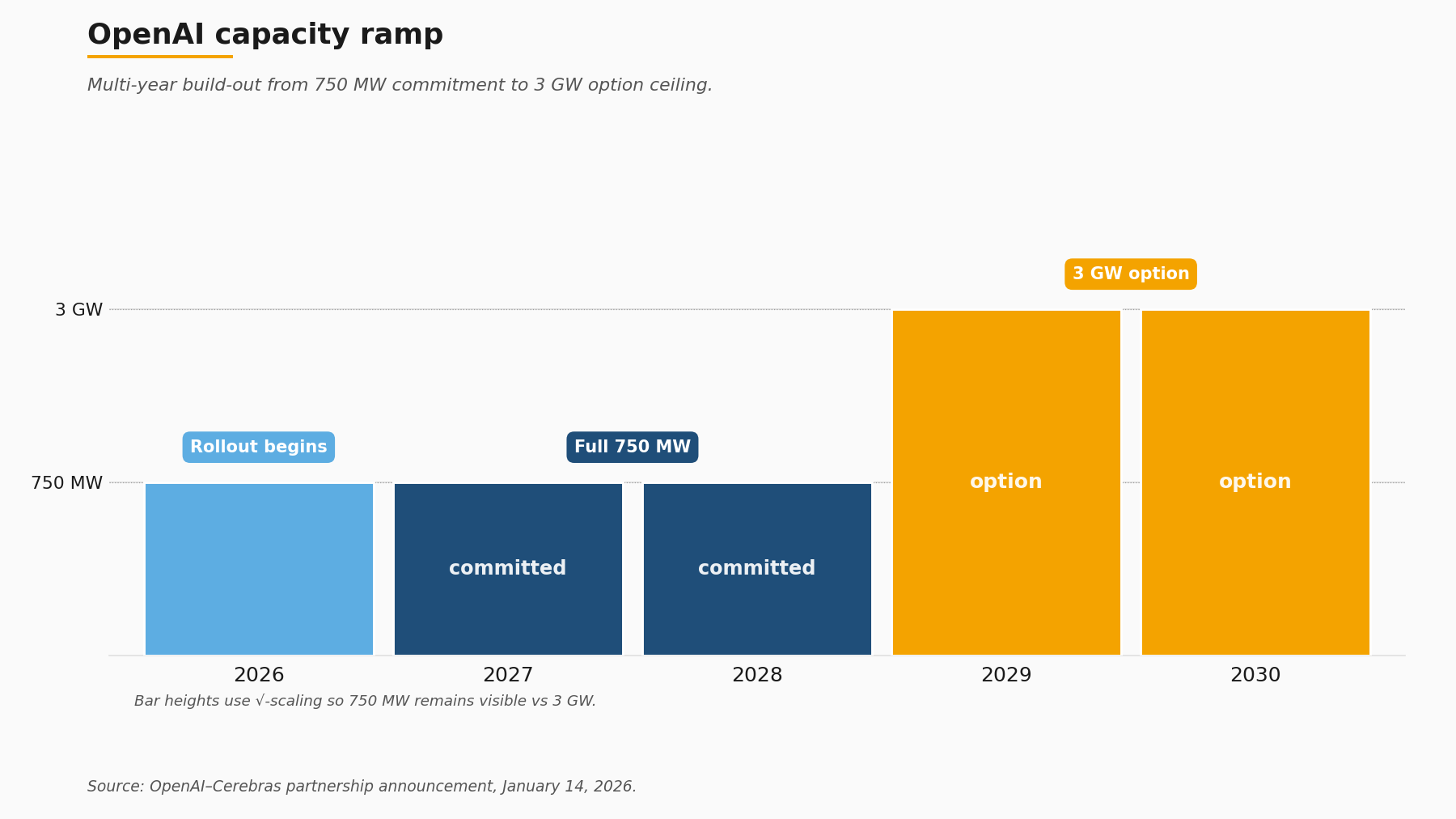
7. Where this leaves the rest of the accelerator cohort
A publicly priced wafer-scale anchor at roughly 86 billion USD fully diluted re-prices private comparables across the second-generation accelerator cohort, and the cap-table math now points to a measurably wider IPO window than CoreWeave's March 2025 print suggested.
The relevant cohort positions, all from primary sources:
- Groq: 6.9 billion USD post-money on a 750 million USD round, announced September 2025. Jonathan Ross described Groq's positioning in a single line that bears on the cohort framing: "Inference is defining this era of AI, and we're building the American infrastructure that delivers it with high speed and low cost." The framing maps cleanly to the same inference-shortfall thesis the Cerebras IPO multiple underwrites.
- Tenstorrent: approximately 2.6 billion USD post-money on a 693 million USD Series D, closed December 2024, led by Samsung Securities and AFW Partners, with Bezos Expeditions among the syndicate per TechCrunch's coverage.
- Lightmatter: 4.4 billion USD post-money on a 400 million USD Series D, announced October 2024, photonics-anchored.
- Rebellions: 1.4 billion USD Series C in September 2025, then a 400 million USD pre-IPO round at 2.34 billion USD in March 2026.
The cohort's combined post-money sits at roughly 15.3 billion USD across four private companies plus the still-private SambaNova. Set that against a single public anchor at 86 billion USD fully diluted, and the implied re-rating math is straightforward to write down even if the specific paths to liquidity are not. The next plausible filers based on round timing and revenue scale are Groq, Tenstorrent and Rebellions, in some order, with Lightmatter sitting in a slightly different category because of the photonics architecture's longer customer-validation timeline. Whether any of those filings actually arrive on any specific timetable is not something the public record currently supports forecasting.
The relevant reference IPO from the broader infrastructure stack is CoreWeave's March 2025 pricing, which came in 40 USD below its filed range at 37.5 million shares for 1.5 billion USD at an implied valuation of roughly 23 billion USD. CoreWeave is a GPU-cloud operator, not an accelerator vendor, but the pricing, and the cool reception that followed it, became the working assumption inside the cohort about what public-market appetite for AI-infrastructure equity looked like. The Cerebras print is the first data point to materially update that assumption. It does not, on its own, prove a sustained window is open. It does prove the window is not closed.
The relevant reference IPO from the broader accelerator-adjacent stack is Astera Labs in March 2024, which priced 19.8 million shares at 36 USD for 604.4 million USD to the company. Astera is a connectivity-fabric supplier rather than an accelerator vendor, but the print established that a publicly tradable AI-infrastructure equity with credible Nvidia adjacency could clear at a high multiple. Astera and Cerebras between them are now the two public references for any second-generation hardware company underwriting its way through an S-1.
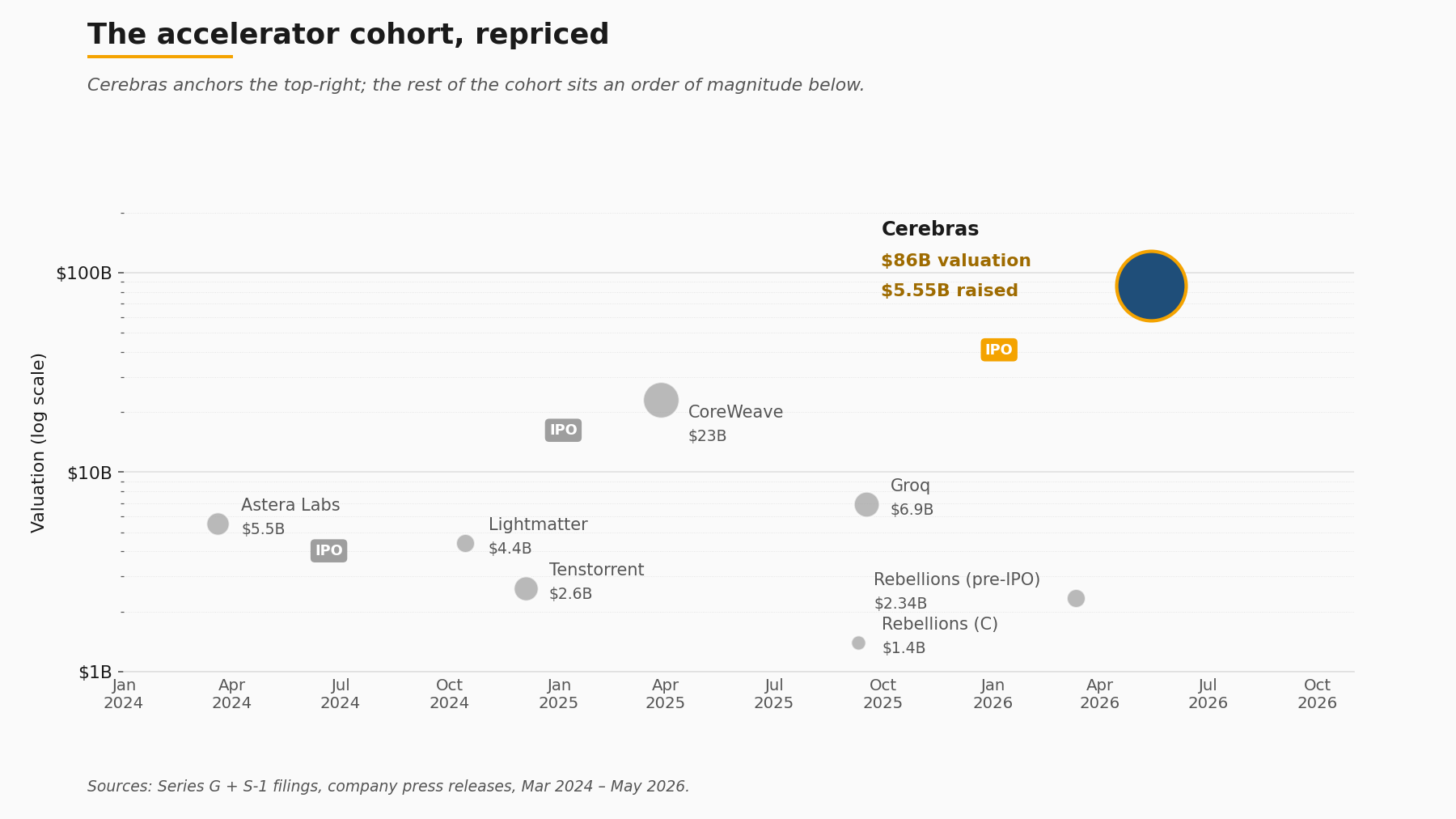
8. What infrastructure buyers should take from the print
For procurement teams sitting on multi-quarter accelerator decisions, the Cerebras IPO is useful primarily as a publicly-tradable reference for non-Nvidia silicon at scale. That reference did not exist a week ago. A constructive framework for using it has three legs.
First, workload fit. The independent benchmark covered in section 2 is unambiguous on one point: per-rack throughput leadership and cost-normalized throughput leadership are different questions, and the correct architecture depends on which one the procurement spreadsheet is asking. Workloads where activation movement dominates and where intra-system bandwidth is the binding constraint (very large dense matrix multiplies, large-batch inference on the heaviest models) favour the wafer-scale architecture. Workloads where batch size varies, where control-flow is more complex, or where per-dollar throughput at smaller deployments is the binding constraint, continue to favour GPU clusters. The decision is not architectural; it is workload-specific.
Second, supplier symmetry. The customer-concentration paragraph that dominated the bear case on Cerebras is the same paragraph that, read from the buyer's side, applies to any organisation whose accelerator footprint is more than 80% Nvidia. The diversification math runs in both directions. A buyer that takes Cerebras's G42-plus-MBZUAI exposure as disqualifying must also confront the symmetric exposure on the Nvidia side. Most buyers should do both calculations explicitly, and most have not. The fact that a 86 billion USD publicly tradable alternative exists changes the second calculation. The mechanism is straightforward: hedged exposure with a meaningful non-Nvidia line in the procurement budget is now a defensible internal position in a way that was harder to argue when the alternative vendors were all privately held.
Third, contract structure. The OpenAI-Cerebras working-capital-loan-plus-warrant arrangement covered in section 6 is the structural template that large-volume buyers should study, and not because the dollar values translate. The mechanism, buyer-side equity alignment tied to supplier execution, is the structural innovation that turns a multi-year supply commitment into something with the contractual durability to support multi-gigawatt build planning. Smaller buyers will not negotiate that structure on first-order terms. They can, however, ask suppliers whether comparable mechanisms (multi-year capacity commitments with milestone-tied execution credits, for example) are available at smaller scale. The honest answer is that they often are, and that they often are not asked for.
The Katti framing from OpenAI is the line worth carrying into a procurement memo: the compute strategy is to build a resilient portfolio that matches the right systems to the right workloads. That is not novel as a phrase. It is novel as a position taken publicly by the largest single discretionary buyer of frontier compute. Until January 2026, a procurement team arguing the same position internally was arguing against a stronger default; after January 2026, they are arguing alongside it.
9. What is worth watching across the next two quarters
Three concrete watch-items emerge from the documented record, each tied to a specific filing or disclosure window.
The first is the insider lockup expiry. The standard structure for an offering of this size releases insider shares on the earlier of two business days after the second post-IPO quarterly earnings release or 180 days after the prospectus date. For an offering priced May 13 and traded May 14, the 180-day calendar window falls in mid-November 2026; the Q3 2026 earnings release will set the alternative date. The total share count released is meaningful enough relative to the public float that the window itself matters more than the precise number; readers who want the exact figure should pull the lockup section of the May 2026 S-1/A directly.
The second is the OpenAI rollout. The 750-megawatt build begins in 2026, with options stepping up toward 3 gigawatts in the 2029-2030 window. Cerebras's quarterly disclosures from Q2 2026 onward should contain milestone language on the first installed megawatts, the first revenue recognised under the supply agreement, and any change in the option exercise mechanics. Each of those data points is a partial test of the capacity-shortfall thesis the IPO multiple underwrites.
The third is the rest of the accelerator cohort. The next S-1 from Groq, Tenstorrent or Rebellions, if and when filed, will provide a comparable price point for a non-wafer-scale architecture pursuing the same inference-capacity opportunity. The cap-table math now points to that filing being more attractive on a relative basis than it was last week. Whether any of those companies chooses to act on that math is their own decision, and the public record does not currently support guessing the timing.
What the 86 billion USD multiple commits the market to believing is straightforward to state. It commits to the proposition that deliverable accelerator capacity for production inference workloads will remain materially behind contracted demand for the next three to five years, that at least one non-Nvidia architecture will capture a measurable share of that gap, and that Cerebras's wafer-scale approach is positioned to be that architecture. Two specific data points test that belief in public. The first is Nvidia Blackwell shipment cadence through the back half of 2026 and into 2027, which will be visible in Nvidia's quarterly disclosures and in hyperscaler capex commentary; faster-than-expected shipments compress the multiple. The second is the first non-G42, non-MBZUAI customer that Cerebras discloses at eight-figure annual revenue in a 10-Q; the appearance of that customer expands the multiple and the absence of it contracts it. Both data points are knowable from public filings. The IPO does not need a thesis beyond that.
Further reading: for the primary record, see Cerebras's IPO pricing release of May 13, 2026, the Series G announcement with the broader customer roster, the OpenAI-Cerebras partnership page on the 750-megawatt commitment, and the SEC EDGAR S-1/A filed May 2026 for the underlying financials.
How we use AI and review our work: About Insightful AI Desk.

